Athena
Solving fundamental computational problems that deliver meaningful impact for Google’s products, society, and scientific progress.

Solving fundamental computational problems that deliver meaningful impact for Google’s products, society, and scientific progress.
About the team
Athena is an international team of research scientists and engineers who tackle product-inspired problems with novel solutions to assist, complement, empower, and inspire people — from the everyday to the imaginative. Our work spans algorithms, artificial intelligence (AI), language understanding, and many other fields, and yields state-of-the-art breakthroughs in areas like efficiency, privacy, and user engagement.
We collaborate closely with partners across Google to take discoveries from publication to implementation for the Company's largest and most trusted products. Beyond Google's portfolio of products and services, our contributions to AI, computer science and machine learning power scientific advances for climate science, journalism, microeconomics and other data-driven disciplines.
We recognize that AI is a foundational and transformational technology and are proud to contribute to a long history of responsible innovation. Our commitment to Responsible AI principles ensure we develop and use technologies in ways that are socially beneficial, avoid bias, are built and tested for safety, are accountable to people and aligned with our values
Team focus summaries
We extend machine learning approaches to better model the relationships contained in information networks. These models (e.g., semi-supervised similarity ranking & clustering, neural graph embedding, and graph convolutional approaches) are useful in a wide range of machine learning applications.
Auction theory, mechanism design, and advanced algorithms serve to improve Ads and other market-based products
Applying integer programming, linear programming, constraint programming, and graph algorithms to solve problems at scale for transportation, search, natural language understanding, computer vision, robotics and more.
We advance the state of the art in natural language technologies and build systems that learn to understand and generate language in context.
We focus on large scale machine learning including supervised learning (e.g. deep learning and kernel-based learning), and semi/unsupervised learning (e.g. streaming clustering and efficient similarity search). The research areas include distributed optimization, personalization and privacy-preserving learning, on-device learning and inference, recommendation systems, data-dependent hashing, and learning-based vision. We develop principled approaches and apply them to Google’s products. Our team regularly publishes in top-tier learning conferences and journals. Our team’s work has been applied across Google, powering Search and Display Ads, YouTube, Android, Play, Gmail, Assistant and Google Shopping.
We provide fast clustering of the datasets that can scale to billions of datapoints, and a streaming throughput of hundreds of thousands of points per second. The goal is to provide scalable nonparametric clustering without making simplistic generative assumptions like convexity of clusters which are rarely true in practice. The team develops techniques that can handle drift in data distributions over time. These techniques are being used in a large number of applications including dynamic spam detection in multiple products and semantic expansion in NLP.
We sift through data to discover, understand, and model implicit signals in user behavior. We partner with Product Areas such as Ads, YouTube, Android, and more to add machine learning functionality to products across Google. Due to the open ended nature of data mining, ongoing projects vary and currently include smart notifications on Android, Ads Pricing optimizations, differential privacy work, and more.
The goals of the Structured Data group are: 1) working with various product teams closely and leverage our expertise in structured data to solve challenging technical problems and initiate new product features; 2) providing scientific expertise in computational journalism across Google in the fight against digital misinformation; 3) drive a long-term agenda that will advance state-of-the-art research in structured data with real world impact.
We develop techniques for large scale similarity search in massive databases with arbitrary data types (sparse or dense high dimensional data) and similarity measures (metric/non-metric, potentially learned from data). The focus has been on developing data-dependent ML-based hashing techniques and tree-hash hybrids that are driving a multitude of applications at Google. This team also develops techniques for fast inference in machine learning models including neural networks, often improving the speeds over 50x while maintaining near exact accuracy.
Our mission is to accurately and efficiently represent, combine, optimize and search models of speech and text. In particular, we devise automata, grammars, neural and other models that represent word histories, context-dependent lexicons for speech and keyboard, written-to-spoken transductions and extractions of dates, times, currency, measures, etc, and transliteration and contextual models of language. These can be combined and optimized to give high-accuracy, efficient speech recognition and synthesis, text normalization, and more. We provide efficient decoding algorithms to search these models. This work is used extensively in Google's speech and text processing infrastructure.
Our mission is to create a comprehensive set of classifiers for detecting offensive, inappropriate & controversial content in images and video. We accomplish this using a variety of techniques, including ensembles of ML models that are trained on images and text from the web. We also apply transfer learning on deep vision models for domain-specific classifier creation.
Semi-supervised learning is increasingly critical to solving many real-world product problems where data is sparse, sparsely labeled, or noisy. We develop semi-supervised and unsupervised machine learning systems that operate at Google scale. We apply our research to a broad range of problems, including query understanding, conversation understanding, and media understanding.
We develop systems for transforming cloud-resident ML models to highly efficient models that run on resource-constrained mobile devices.
We enrich electronic conversations by understanding media using multi-modal signals from images, video, text, and the web. We accomplish this by marrying machine vision models with ML-enabled natural language understanding and generation systems.
Many fundamental learning problems we solve at Google have non-trivial combinatorial structure that prevents the application of general purpose ML algorithms. They exhibit complex and discontinuous loss functions (e.g., in pricing) or combinatorial explosions (such as contextual bandits, feature selection, or integer programming) and may require solutions that are robust against strategic behavior. Our team pushes the boundaries in these areas through research that blends techniques from learning theory, game theory, and discrete/continuous optimization.
Glassbox Learning does R&D into making ML more controllable and interpretable, without sacrificing accuracy. An important line of research is how to translate policy goals about metrics and fairness into machine learning training. For interpretability, Glassbox provides end-to-end guarantees on the relationship of inputs to outputs, such as monotonicity and other shape constraints. To achieve these goals, Glassbox researches and utilizes new algorithms for constrained optimization.
Dataset Search, also known as Science Search, is a project to index all datasets on the web and to make the metadata (and, where possible, the data itself) searchable and useful. Datasets and related data tend to be spread across multiple data repositories on the web. In most cases, data is not linked nor has it been indexed which makes searching tedious or, in some cases, impossible.
Featured publications
Highlighted work
-
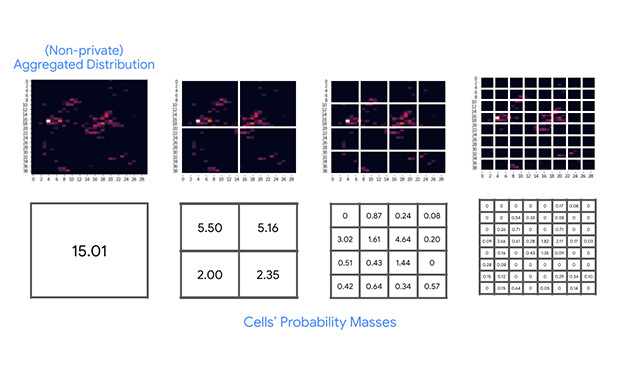 Differentially privacy heatmapsIntroducing an efficient differential privacy (DP) algorithm for computing heatmaps with provable guarantees.
Differentially privacy heatmapsIntroducing an efficient differential privacy (DP) algorithm for computing heatmaps with provable guarantees. -
 Simulating wildfires before they happenSince 1930, 50% of California's largest wildfires occurred in the last 5 years. Learn how Google Research's Foresight team predicts wildfire behavior using AI & simulations.
Simulating wildfires before they happenSince 1930, 50% of California's largest wildfires occurred in the last 5 years. Learn how Google Research's Foresight team predicts wildfire behavior using AI & simulations. -
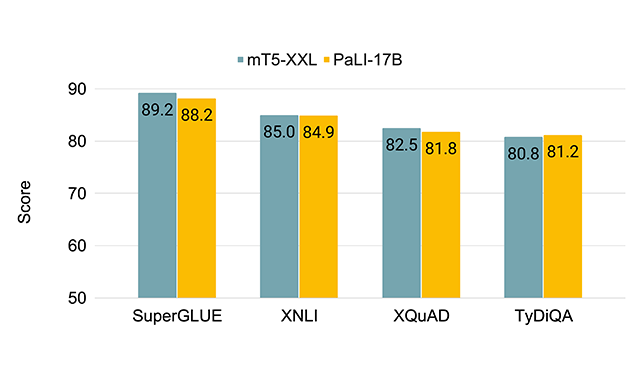 A scalable approach to joint modeling of language and imagesPaLI is a simple, reusable and scalable architecture that can reuse previously trained models. It is trained on WebLI data to perform a wide range of tasks across image-only, language-only, and image-language domains.
A scalable approach to joint modeling of language and imagesPaLI is a simple, reusable and scalable architecture that can reuse previously trained models. It is trained on WebLI data to perform a wide range of tasks across image-only, language-only, and image-language domains. -
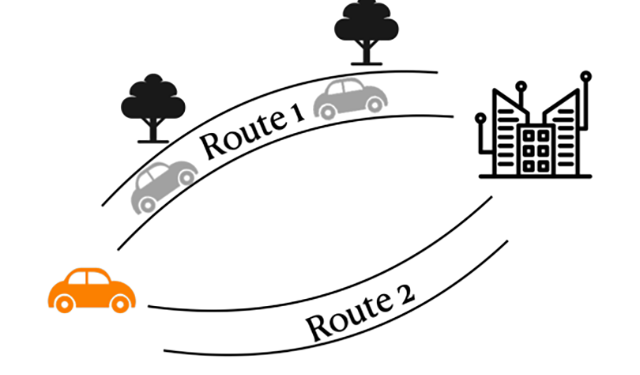 Learning with queried hintsAlgorithms can achieve strong guarantees even when the feedback from the model is in the form of a weak hint in bandit-like settings.
Learning with queried hintsAlgorithms can achieve strong guarantees even when the feedback from the model is in the form of a weak hint in bandit-like settings. -
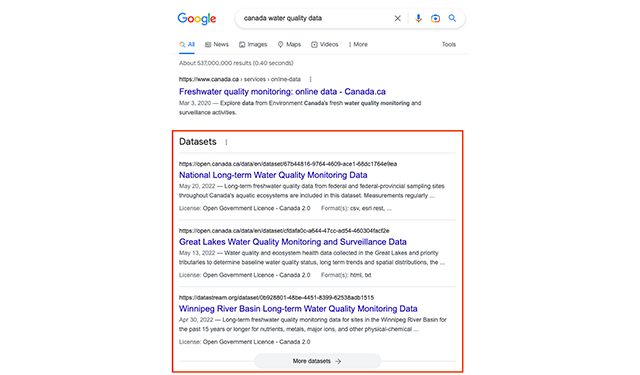 Datasets at your fingertips in Google SearchDataset Search is a dedicated search engine for datasets with more than 45 million indexed datasets from more than 13,000 websites covering many disciplines and topics, including government, scientific, and commercial datasets.
Datasets at your fingertips in Google SearchDataset Search is a dedicated search engine for datasets with more than 45 million indexed datasets from more than 13,000 websites covering many disciplines and topics, including government, scientific, and commercial datasets. -
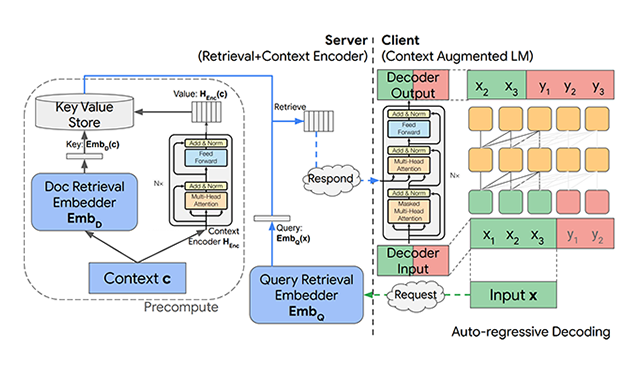 2022 & beyond: Algorithms for efficient deep learningOur research on efficient architectures reduce cost and latency to enable ML breakthroughs in production and business deployments.
2022 & beyond: Algorithms for efficient deep learningOur research on efficient architectures reduce cost and latency to enable ML breakthroughs in production and business deployments. -
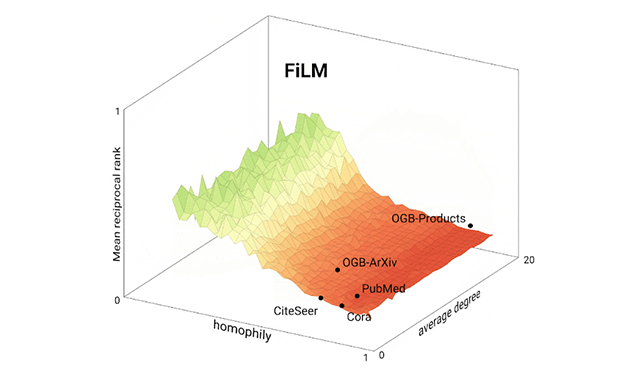 2022 & beyond: Algorithmic advancesWe're pushing the bounds of clustering, optimization and scalability for algorithms that power Google-scale services. Innovation in algorithmic theory sets the foundation for our global knowledge graph with applications for Ads, Maps, YouTube and more.
2022 & beyond: Algorithmic advancesWe're pushing the bounds of clustering, optimization and scalability for algorithms that power Google-scale services. Innovation in algorithmic theory sets the foundation for our global knowledge graph with applications for Ads, Maps, YouTube and more. -
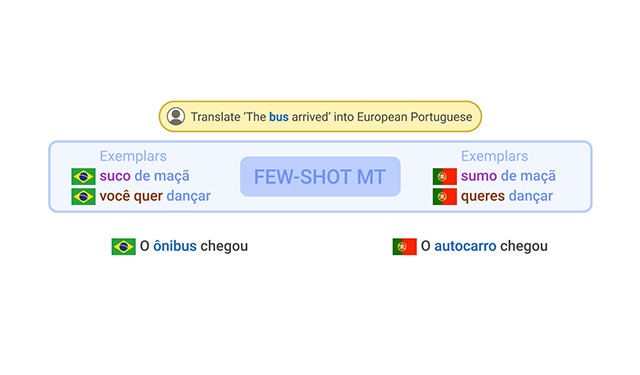 FRMT: A benchmark for few-shot region-aware machine translationAn evaluation dataset used to measure machine translation systems’ ability to support regional varieties through a case study on Brazilian vs. European Portuguese and Mainland vs. Taiwan Mandarin Chinese.
FRMT: A benchmark for few-shot region-aware machine translationAn evaluation dataset used to measure machine translation systems’ ability to support regional varieties through a case study on Brazilian vs. European Portuguese and Mainland vs. Taiwan Mandarin Chinese. -
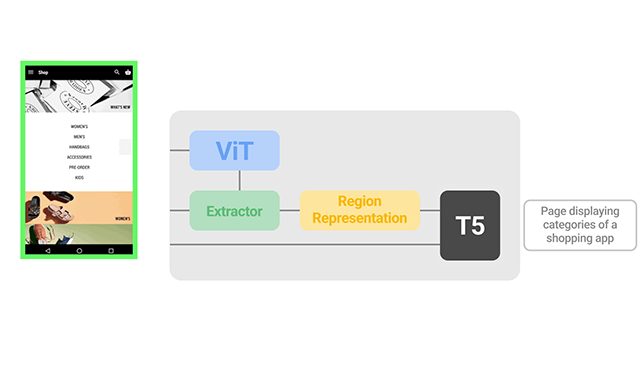 A vision-language approach for foundational UI understandingA vision-only approach that aims to achieve general UI understanding completely from raw pixels — a key step towards achieving intelligent UI behaviors.
A vision-language approach for foundational UI understandingA vision-only approach that aims to achieve general UI understanding completely from raw pixels — a key step towards achieving intelligent UI behaviors. -
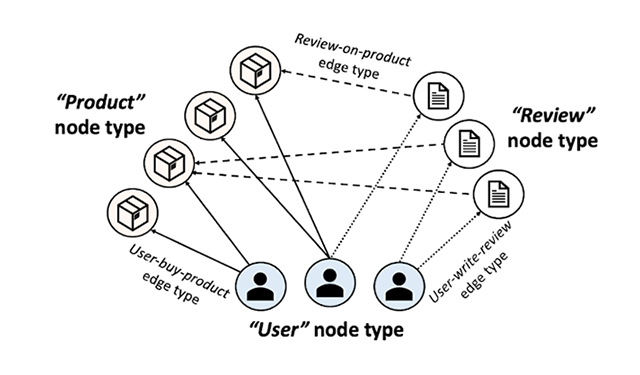 Teaching old labels new tricks in heterogeneous graphsA novel zero-shot transfer learning approach to improve model performance on a target domain with no labels using the knowledge learned by the model from another related source domain with adequately labeled data.
Teaching old labels new tricks in heterogeneous graphsA novel zero-shot transfer learning approach to improve model performance on a target domain with no labels using the knowledge learned by the model from another related source domain with adequately labeled data. -
 Leveraging transfer learning for large scale differentially private image classificationTransfer learning can be used to improve the accuracy of differentially private image classification models by leveraging knowledge learned from pre-training tasks. This is especially useful when there is limited or low-quality data available for the target problem.
Leveraging transfer learning for large scale differentially private image classificationTransfer learning can be used to improve the accuracy of differentially private image classification models by leveraging knowledge learned from pre-training tasks. This is especially useful when there is limited or low-quality data available for the target problem.
Some of our locations







Some of our people
-

Su Wang
- Machine Perception
- Natural Language Processing
-

Emmanuel Guere
- Algorithms and Theory
- Machine Intelligence
- Software Engineering
-

Ross Michael Anderson
- Algorithms and Theory
- Machine Intelligence
-

You (Will) Wu
- Data Management
- Data Mining and Modeling
- Information Retrieval and the Web
-

Brandon Asher Mayer
- Distributed Systems and Parallel Computing
- Machine Intelligence
- Machine Perception
-

Tianjian Lu
- Algorithms and Theory
- Hardware and Architecture
- Machine Intelligence
-

Jae Hun Ro
- Machine Intelligence
- Natural Language Processing
-

Harikrishna Narasimhan
- Algorithms and Theory
- Machine Intelligence
-

Alexander Ku
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Cibu C Johny
- Natural Language Processing
-

Mihai Amarandei-Stavila
- Networking
-

Sumit Kumar Sanghai
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Frederic Didier
- Algorithms and Theory
- Machine Intelligence
-

Rasmus Munk Larsen
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Donald Metzler
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Kshipra Bhawalkar
- Algorithms and Theory
- Economics and Electronic Commerce
-

Yun-hsuan Sung
- Machine Intelligence
- Natural Language Processing
- Speech Processing
-

Felix Yu
- Machine Intelligence
- Machine Learning
- Machine Perception
-

Vinh Q. Tran
- Machine Intelligence
- Natural Language Processing
-

Serena Lutong Wang
- Machine Intelligence
-
Ashish V. Thapliyal
- General Science
- Machine Intelligence
- Machine Translation
-

Santiago R. Balseiro
- Algorithms and Theory
- Economics and Electronic Commerce
-

Moustafa Alzantot
- Machine Intelligence
- Mobile Systems
- Natural Language Processing
-

Vincent Pierre Cohen-addad
- Algorithms and Theory
- Machine Intelligence
-

Fotios Iliopoulos
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-
Shankar Kumar
- Data Mining and Modeling
- Machine Translation
- Natural Language Processing
-
Neha Arora
- Algorithms and Theory
- Data Mining and Modeling
- Information Retrieval and the Web
-

Yang Li
- Human-Computer Interaction and Visualization
- Machine Intelligence
- Mobile Systems
-

Hao Zhang
- Machine Learning
- Machine Translation
- Natural Language Processing
-

Amr Ahmed
- Data Mining and Modeling
- Human-Computer Interaction and Visualization
- Information Retrieval and the Web
-
Mingyang Zhang
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-
Harsh Mehta
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
-

Cheng Li
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-
Gang Li
- Natural Language Processing
-

Tao Chen
- Information Retrieval and the Web
- Natural Language Processing
-

Krishna Srinivasan
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Xin Wang
- Algorithms and Theory
- Machine Intelligence
-
Deepak Ramachandran
- Machine Intelligence
- Natural Language Processing
-

Qing Wang
- Distributed Systems and Parallel Computing
- General Science
-

Li Yang
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Di Wang
- Algorithms and Theory
- Data Mining and Modeling
- Information Retrieval and the Web
-

Yichen Zhou
- Data Mining and Modeling
- Machine Intelligence
- Machine Learning
-

Zach Fisher
- General Science
- Machine Intelligence
- Natural Language Processing
-
Jing Lu
- Information Retrieval and the Web
- Natural Language Processing
-

Zhe Feng
- Algorithms and Theory
- Economics and Electronic Commerce
- Machine Intelligence
-

Kate Lin
- Machine Intelligence
- Machine Perception
-
Xi Chen
- Machine Intelligence
- Natural Language Processing
-

Chao Zhang
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-
Lin Chen
- Algorithms and Theory
- Machine Intelligence
-

Jennifer Brennan
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Vahab S. Mirrokni
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- Algorithms and Theory
-

Corinna Cortes
- Algorithms and Theory
- Data Mining and Modeling
- General Science
-

Michael Riley
- Information Retrieval and the Web
- Machine Intelligence
- Algorithms and Theory
-

Tania Bedrax-Weiss
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Gagan Aggarwal
- Algorithms and Theory
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Sanjiv Kumar
- Algorithms and Theory
- Information Retrieval and the Web
- Machine Intelligence
-

Jon Orwant
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Information Retrieval and the Web
-

Aranyak Mehta
- Algorithms and Theory
- Economics and Electronic Commerce
-

Ameesh Makadia
- Machine Intelligence
- Machine Perception
-

Vincent Furnon
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Sarvjeet Singh
- Data Management
- Machine Intelligence
- Responsible AI
-

Andrew Tomkins
- Algorithms and Theory
- Data Mining and Modeling
- Human-Computer Interaction and Visualization
-

Silvio Lattanzi
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Sergei Vassilvitskii
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Vidhya Navalpakkam
- Human-Computer Interaction and Visualization
- Information Retrieval and the Web
- Machine Perception
-

Michael Bendersky
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Radu Soricut
- General Science
- Machine Intelligence
- Machine Translation
-

Marc Najork
- Information Retrieval and the Web
- Machine Intelligence
-

Craig Boutilier
- Algorithms and Theory
- Economics and Electronic Commerce
- Human-Computer Interaction and Visualization
-

Rich Washington
- Algorithms and Theory
- Machine Intelligence
-
Katrina Sostek
-

Anna Katanova
- Machine Intelligence
- Natural Language Processing
- Speech Processing
-

Fabien Viger
- Algorithms and Theory
- Machine Intelligence
-

Cyril Allauzen
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-

Kevin Aydin
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Laurent Perron
-

Mario Guajardo-Céspedes
- Data Management
- Education Innovation
- Human-Computer Interaction and Visualization
-

Jeongwoo Ko
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Bruno De Backer
- Algorithms and Theory
- Hardware and Architecture
-

Sameer Agarwal
- Algorithms and Theory
- Machine Perception
-
Tom Bagby
- Natural Language Processing
- Speech Processing
-
Chih-wei Hsu
- Machine Intelligence
-

Alex Fabrikant
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-

Alexander Gutkin
- Natural Language Processing
- Speech Processing
-

Allan Heydon
- Machine Intelligence
- Software Engineering
- Software Systems
-

Xavi Gonzalvo
- Machine Intelligence
- Speech Processing
-
Zoya Svitkina
- Algorithms and Theory
-

Kai Kohlhoff
- Distributed Systems and Parallel Computing
- General Science
- Machine Intelligence
-

Afshin Rostamizadeh
- Algorithms and Theory
- Data Mining and Modeling
- Education Innovation
-

Umar Syed
- Machine Intelligence
- Security, Privacy and Abuse Prevention
-

Mohammad Mahdian
- Algorithms and Theory
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Kevin Canini
- Machine Intelligence
-

Kishore Papineni
- Education Innovation
- Information Retrieval and the Web
- Machine Intelligence
-

Clement Courbet
- Algorithms and Theory
- Hardware and Architecture
- Software Engineering
-

Tamas Sarlos
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-
Bo Pang
- Natural Language Processing
-

Burcu Karagol Ayan
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Ondrej Sykora
- Algorithms and Theory
- Hardware and Architecture
- Software Engineering
-

David Rybach
- Speech Processing
-

Sandeep Tata
- Data Management
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Sebastian Goodman
- Machine Perception
- Natural Language Processing
-

Alejandra Estanislao
- Algorithms and Theory
-

Guillaume Chatelet
- Hardware and Architecture
- Software Engineering
- Software Systems
-

Brian Roark
- Natural Language Processing
- Speech Processing
-

Nan Ding
- General Science
- Machine Intelligence
- Machine Perception
-
Dustin Zelle
- Data Mining and Modeling
- Machine Intelligence
-

Pawel Lichocki
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- General Science
-

Erik Vee
- Algorithms and Theory
- Economics and Electronic Commerce
- Information Retrieval and the Web
-
Jai Gupta
- Algorithms and Theory
- Data Mining and Modeling
-
Jing Xie
- Machine Intelligence
-

Aaron Archer
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Jonathan Halcrow
- Algorithms and Theory
- Machine Intelligence
-

Renato Paes Leme
- Algorithms and Theory
- Economics and Electronic Commerce
-

Morteza Zadimoghaddam
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Economics and Electronic Commerce
-

Austin Waters
- Machine Intelligence
- Speech Processing
-

Simon Baumgartner
- Information Retrieval and the Web
- Machine Intelligence
- Software Engineering
-

Natasha Noy
- Data Management
- Data Mining and Modeling
- Human-Computer Interaction and Visualization
-
Flip Korn
- Data Management
- Data Mining and Modeling
-

Zhenhai Zhu
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Ruiqi Guo
- Machine Intelligence
- Machine Perception
-

Da-Cheng Juan
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Chris Welty
- Machine Intelligence
- Natural Language Processing
-

Saeed Alaei
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Economics and Electronic Commerce
-
Anne-Claire Haury
- Machine Intelligence
-

Rina Panigrahy
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Dmitry Storcheus
- Algorithms and Theory
- Machine Intelligence
-

Sreenivas Gollapudi
- Algorithms and Theory
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Kyle Gorman
- Natural Language Processing
- Speech Processing
-

Edith Cohen
- Algorithms and Theory
- Data Mining and Modeling
- Machine Learning
-

Xuanhui Wang
- Information Retrieval and the Web
- Machine Intelligence
-

Joonseok Lee
- Data Mining and Modeling
- Machine Intelligence
- Machine Perception
-
ying sheng
- Machine Intelligence
-
Andres Munoz Medina
- Data Mining and Modeling
- Economics and Electronic Commerce
- Security, Privacy and Abuse Prevention
-

Mandy Guo
- Machine Intelligence
- Machine Translation
- Natural Language Processing
-

Karthik Raman
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Ehsan Variani
- Machine Intelligence
- Speech Processing
-

Balasubramanian Sivan
- Algorithms and Theory
- Economics and Electronic Commerce
-

Ji Ma
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Seungyeon Kim
- Data Mining and Modeling
- Machine Intelligence
-

Kostas Kollias
- Algorithms and Theory
- Economics and Electronic Commerce
-
Yin-Wen Chang
- Machine Translation
- Natural Language Processing
-

Isin Demirsahin
- Natural Language Processing
-

Dana Alon
- Machine Intelligence
- Natural Language Processing
-

bertrand Le cun
- Algorithms and Theory
-

Nachiappan Valliappan
- Human-Computer Interaction and Visualization
- Machine Intelligence
- Machine Perception
-

Alessandro Epasto
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-

Ananda Theertha Suresh
- Algorithms and Theory
- Machine Intelligence
-
Spurthi Amba Hombaiah
- Information Retrieval and the Web
- Natural Language Processing
-

Sherol Chen
- Education Innovation
- Human-Computer Interaction and Visualization
- Machine Intelligence
-

Vincent Perot
- Machine Intelligence
- Natural Language Processing
-

Jialu Liu
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Bryan Perozzi
- Data Mining and Modeling
- Machine Intelligence
-

Felix Chern
- Algorithms and Theory
- Hardware and Architecture
- Machine Intelligence
-
Manish Purohit
- Algorithms and Theory
- Machine Intelligence
-

Weize Kong
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Junfeng He
- Information Retrieval and the Web
- Machine Intelligence
- Machine Perception
-

David Applegate
- Algorithms and Theory
-

Stéphane Soppera
- Algorithms and Theory
- Machine Intelligence
- Software Engineering
-

Kareem Amin
- Algorithms and Theory
- Economics and Electronic Commerce
- Machine Intelligence
-

Walid Krichene
- Algorithms and Theory
- Machine Intelligence
- Machine Learning
-

Si Si
- Data Mining and Modeling
- Machine Intelligence
-
Grady Simon
- Human-Computer Interaction and Visualization
- Machine Intelligence
- Natural Language Processing
-

Filip Radlinski
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Zhen Qin
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

CJ Carey
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-

Sen Zhao
- Data Mining and Modeling
- Machine Intelligence
-

Tomer Levinboim
- Machine Intelligence
- Natural Language Processing
-

Jason Baldridge
- Natural Language Processing
-
Guolong Su
- Machine Intelligence
- Natural Language Processing
-
Gustavo Hernandez Abrego
- Machine Translation
- Natural Language Processing
-
Yinlam Chow
- Algorithms and Theory
- Machine Intelligence
- Robotics
-
Sashank Reddi
- Algorithms and Theory
- Machine Intelligence
- Natural Language Processing
-

Michal Lukasik
- Machine Learning
- Natural Language Processing
-

John Palowitch
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Giulia DeSalvo
- Algorithms and Theory
- General Science
- Machine Intelligence
-

Dimitris Paparas
- Algorithms and Theory
- Data Management
- Economics and Electronic Commerce
-

Sarah Mohajeri
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
-
Dara Bahri
- Algorithms and Theory
- Machine Intelligence
- Natural Language Processing
-
Badih Ghazi
- Algorithms and Theory
- Machine Intelligence
- Security, Privacy and Abuse Prevention
-

Hossein Esfandiari
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Economics and Electronic Commerce
-

Chun-Ta Lu
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Arjun Gopalan
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Sara Ahmadian
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-
Christian Tjandraatmadja
- Algorithms and Theory
- Machine Intelligence
-

Song Zuo
- Algorithms and Theory
- Economics and Electronic Commerce
-
Tianqi Liu
- Data Mining and Modeling
- Machine Intelligence
-

Andreas Veit
- Machine Intelligence
- Machine Perception
-

Ankit Singh Rawat
- Algorithms and Theory
- Machine Intelligence
-

Srinadh Bhojanapalli
- Algorithms and Theory
-

Masrour Zoghi
- Information Retrieval and the Web
- Machine Intelligence
-

Jean Pouget-Abadie
- Algorithms and Theory
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Daniel Glasner
- Machine Intelligence
- Machine Perception
-
Ameya Velingker
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-

Sasan Tavakkol
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Honglei Zhuang
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Fei Sha
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Srikumar Ramalingam
- Machine Intelligence
- Machine Perception
- Robotics
-
Jieming Mao
- Algorithms and Theory
- Economics and Electronic Commerce
- Security, Privacy and Abuse Prevention
-

Pasin Manurangsi
- Algorithms and Theory
- Machine Intelligence
- Security, Privacy and Abuse Prevention
-

Phil Sun
- Algorithms and Theory
- Hardware and Architecture
- Machine Intelligence
-

Zonglin Li
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Jeremiah Liu
- Algorithms and Theory
- Machine Intelligence
- Natural Language Processing
-

Felix Stahlberg
- Machine Translation
- Natural Language Processing
-

Nick Doudchenko
- Economics and Electronic Commerce
-

Marialena Kyriakidi
- Data Mining and Modeling
- Information Retrieval and the Web
- Machine Intelligence
-

Le Yan
- Data Mining and Modeling
- General Science
- Information Retrieval and the Web
-

Sadeep Jayasumana
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Matthew Fahrbach
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-
Wittawat Jitkrittum
- Machine Learning
-

Matthew Joseph
- Algorithms and Theory
- Security, Privacy and Abuse Prevention
-

Juan Pablo Vielma
- Algorithms and Theory
- Machine Intelligence
-

Wennan Zhu
- Algorithms and Theory
- Economics and Electronic Commerce
-

Yuan Deng
- Algorithms and Theory
- Economics and Electronic Commerce
- Machine Intelligence
-
Carolina Osorio
- Algorithms and Theory
- Machine Intelligence
-

Rolf Jagerman
- Information Retrieval and the Web
- Machine Intelligence
-

Carlos Esteves
- Machine Intelligence
- Machine Perception
- Robotics
-
Rajat Sen
- Algorithms and Theory
- Machine Intelligence
-

Ayan Chakrabarti
- Machine Intelligence
- Machine Perception
-
Ceslee Montgomery
- Machine Perception
- Natural Language Processing
-

Otilia Stretcu
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Mehran Kazemi
- Machine Intelligence
- Natural Language Processing
-

Luke Vilnis
- Machine Intelligence
- Natural Language Processing
-

Anton Tsitsulin
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
-

Kai Hui
- Information Retrieval and the Web
- Natural Language Processing
-

Rajesh Jayaram
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
-
Parker Riley
- Machine Intelligence
- Machine Translation
- Natural Language Processing
-

Tal Schuster
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Joey Huchette
- Algorithms and Theory
- Machine Intelligence
-

Yichao Zhou
- Data Mining and Modeling
- Machine Intelligence
- Natural Language Processing
-

Krisztian Balog
- Information Retrieval and the Web
- Machine Intelligence
- Natural Language Processing
-

Hussein Hazimeh
- Data Mining and Modeling
- Machine Intelligence
- Security, Privacy and Abuse Prevention
-
Kazuma Hashimoto
- Machine Intelligence
- Natural Language Processing
-
Thibaut Cuvelier
- Algorithms and Theory
- Machine Intelligence
-

Jiaming Shen
- Data Mining and Modeling
- Information Retrieval and the Web
- Natural Language Processing
-
Yifeng Teng
- Algorithms and Theory
- Economics and Electronic Commerce
-

Sjoerd van Steenkiste
- Machine Intelligence
- Machine Perception
- Natural Language Processing
-

Cenk Baykal
- Algorithms and Theory
- Machine Intelligence
-

Sami Abu-El-Haija
- Algorithms and Theory
- Machine Perception
-

Yaqing Wang
- Data Mining and Modeling
- Machine Intelligence
- Natural Language Processing
-

Najoung Kim
- Machine Intelligence
- Natural Language Processing
-

Beliz Gunel
- Data Management
- Information Retrieval and the Web
- Natural Language Processing
