Google Research, 2022 & beyond: Algorithms for efficient deep learning
February 7, 2023
Posted by Sanjiv Kumar, VP and Google Fellow, Google Research
Quick links
The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning.
As these models increasingly find themselves deployed in production and business applications, the efficiency and costs of these models has gone from a minor consideration to a primary constraint. In response, Google has continued to invest heavily in ML efficiency, taking on the biggest challenges in (a) efficient architectures, (b) training efficiency, (c) data efficiency, and (d) inference efficiency. Beyond efficiency, there are a number of other challenges around factuality, security, privacy and freshness in these models. Below, we highlight an array of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
Efficient architectures
A fundamental question is “Are there better ways of parameterizing a model to allow for greater efficiency?” In 2022, we focused on new techniques for infusing external knowledge by augmenting models via retrieved context; mixture of experts; and making transformers (which lie at the heart of most large ML models) more efficient.
Context-augmented models
In the quest for higher quality and efficiency, neural models can be augmented with external context from large databases or trainable memory. By leveraging retrieved context, a neural network may not have to memorize the huge amount of world knowledge within its internal parameters, leading to better parameter efficiency, interpretability and factuality.
In “Decoupled Context Processing for Context Augmented Language Modeling”, we explored a simple architecture for incorporating external context into language models based on a decoupled encoder-decoder architecture. This led to significant computational savings while giving competitive results on auto-regressive language modeling and open domain question answering tasks. However, pre-trained large language models (LLMs) consume a significant amount of information through self-supervision on big training sets. But, it is unclear precisely how the “world knowledge” of such models interacts with the presented context. With knowledge aware fine-tuning (KAFT), we strengthen both controllability and robustness of LLMs by incorporating counterfactual and irrelevant contexts into standard supervised datasets.
 |
| An encoder-decoder cross-attention mechanism for context incorporation that allows decoupling of context encoding from language model inference, leading to efficient context-augmented models. |
One of the questions in the quest for a modular deep network is how a database of concepts with corresponding computational modules could be designed. We proposed a theoretical architecture that would “remember events” in the form of sketches stored in an external LSH table with pointers to modules that process such sketches.
Another challenge in context-augmented models is fast retrieval on accelerators of information from a large database. We have developed a TPU-based similarity search algorithm that aligns with the performance model of TPUs and gives analytical guarantees on expected recall, achieving peak performance. Search algorithms typically involve a large number of hyperparameters and design choices that make it hard to tune them on new tasks. We have proposed a new constrained optimization algorithm for automating hyperparameter tuning. Fixing the desired cost or recall as input, the proposed algorithm generates tunings that empirically are very close to the speed-recall Pareto frontier and give leading performance on standard benchmarks.
Mixture-of-experts models
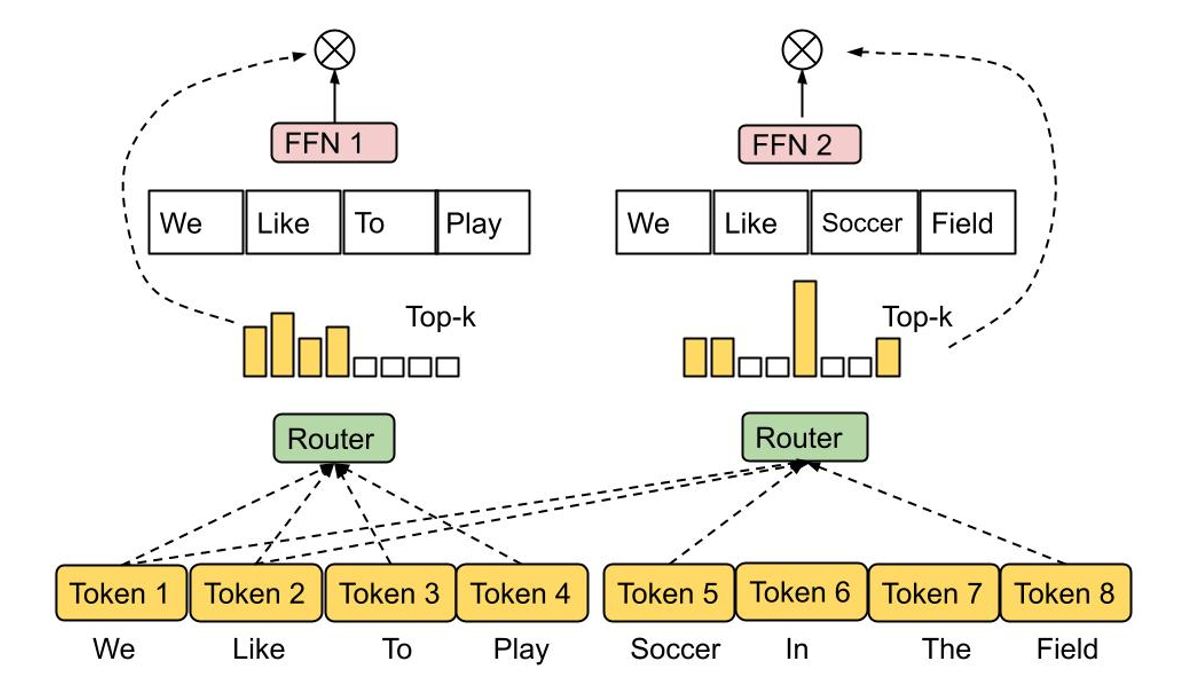
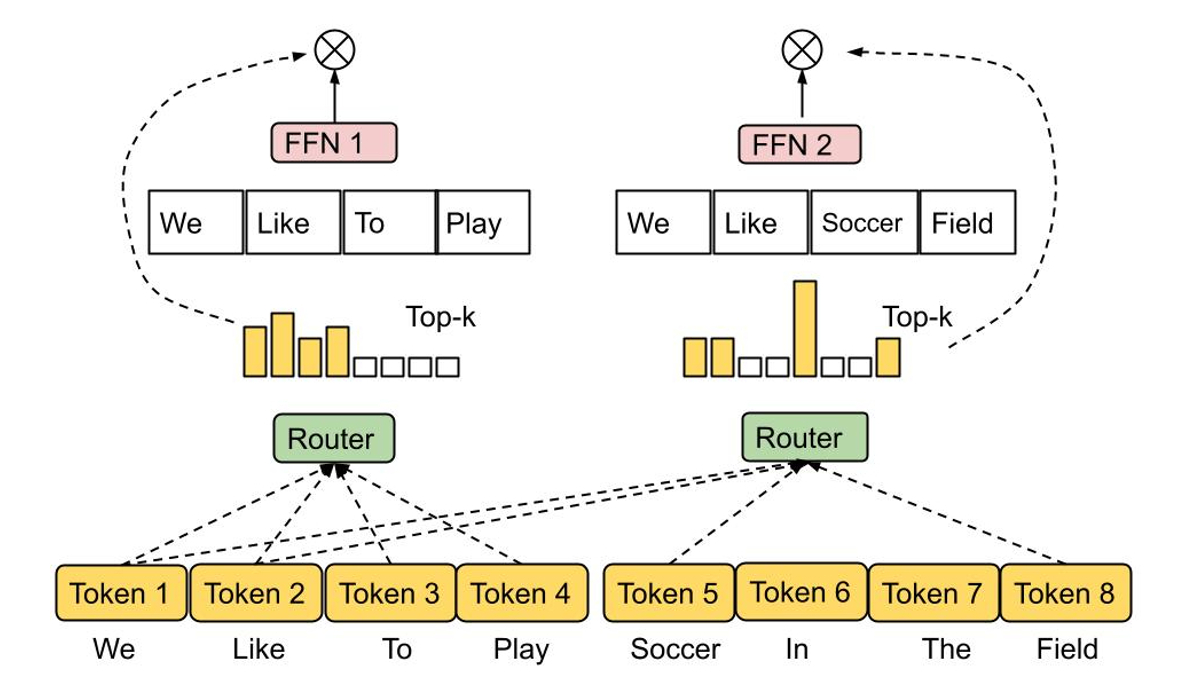
Mixture-of-experts (MoE) models have proven to be an effective means of increasing neural network model capacity without overly increasing their computational cost. The basic idea of MoEs is to construct a network from a number of expert sub-networks, where each input is processed by a suitable subset of experts. Thus, compared to a standard neural network, MoEs invoke only a small portion of the overall model, resulting in high efficiency as shown in language model applications such as GLaM.
 |
| The architecture of GLaM where each input token is dynamically routed to two selected expert networks out of 64 for prediction. |
The decision of which experts should be active for a given input is determined by a routing function, the design of which is challenging, since one would like to prevent both under- and over-utilization of each expert. In a recent work, we proposed Expert Choice Routing, a new routing mechanism that, instead of assigning each input token to the top-k experts, assigns each expert to the top-k tokens. This automatically ensures load-balancing of experts while also naturally allowing for an input token to be handled by multiple experts.
 |
| Expert Choice Routing. Experts with predetermined buffer capacity are assigned top-k tokens, thus guaranteeing even load balancing. Each token can be processed by a variable number of experts. |
Efficient transformers
Transformers are popular sequence-to-sequence models that have shown remarkable success in a range of challenging problems from vision to natural language understanding. A central component of such models is the attention layer, which identifies the similarity between “queries” and “keys”, and uses these to construct a suitable weighted combination of “values”. While effective, attention mechanisms have poor (i.e., quadratic) scaling with sequence length.
As the scale of transformers continues to grow, it is interesting to study if there are any naturally occurring structures or patterns in the learned models that may help us decipher how they work. Towards that, we studied the learned embeddings in intermediate MLP layers, revealing that they are very sparse — e.g, T5-Large models have <1% nonzero entries. Sparsity further suggests that we can potentially reduce FLOPs without affecting model performance.
We recently proposed Treeformer, an alternative to standard attention computation that relies on decision trees. Intuitively, this quickly identifies a small subset of keys that are relevant for a query and only performs the attention operation on this set. Empirically, the Treeformer can lead to a 30x reduction in FLOPs for the attention layer. We also introduced Sequential Attention, a differentiable feature selection method that combines attention with a greedy algorithm. This technique has strong provable guarantees for linear models and scales seamlessly to large embedding models.
 |
| In Treeformer, attention computation is modeled as a nearest neighbor retrieval problem. Hierarchical decision trees are used to find which keys to pay attention to for each query, reducing the quadratic cost of classical attention substantially. |
Another way to make transformers efficient is by making the softmax computations faster in the attention layer. Building on our previous work on low-rank approximation of the softmax kernel, we proposed a new class of random features that provides the first “positive and bounded” random feature approximation of the softmax kernel and is computationally linear in the sequence length. We also proposed the first approach for incorporating various attention masking mechanisms, such as causal and relative position encoding, in a scalable manner (i.e., sub-quadratic with relation to the input sequence length).
Training efficiency
Efficient optimization methods are the cornerstone of modern ML applications and are particularly crucial in large scale settings. In such settings, even first order adaptive methods like Adam are often expensive, and training stability becomes challenging. In addition, these approaches are often agnostic to the architecture of the neural network, thereby ignoring the rich structure of the architecture leading to inefficient training. This motivates new techniques to more efficiently and effectively optimize modern neural network models. We are developing new architecture-aware training techniques, e.g., for training transformer networks, including new scale-invariant transformer networks and novel clipping methods that, when combined with vanilla stochastic gradient descent (SGD), results in faster training. Using this approach, for the first time, we were able to effectively train BERT using simple SGD without the need for adaptivity.
Moreover, with LocoProp we proposed a new method that achieves performance similar to that of a second-order optimizer while using the same computational and memory resources as a first-order optimizer. LocoProp takes a modular view of neural networks by decomposing them into a composition of layers. Each layer is then allowed to have its own loss function as well as output target and weight regularizer. With this setup, after a suitable forward-backward pass, LocoProp proceeds to perform parallel updates to each layer’s “local loss”. In fact, these updates can be shown to resemble those of higher-order optimizers, both theoretically and empirically. On a deep autoencoder benchmark, LocoProp achieves performance comparable to that of higher-order optimizers while being significantly faster.
 |
| Similar to backpropagation, LocoProp applies a forward pass to compute the activations. In the backward pass, LocoProp sets per neuron "targets" for each layer. Finally, LocoProp splits model training into independent problems across layers where several local updates can be applied to each layer's weights in parallel. |
One key assumption in optimizers like SGD is that each data point is sampled independently and identically from a distribution. This is unfortunately hard to satisfy in practical settings such as reinforcement learning, where the model (or agent) has to learn from data generated based on its own predictions. We proposed a new algorithmic approach named SGD with reverse experience replay, which finds optimal solutions in several settings like linear dynamical systems, non-linear dynamical systems, and in Q-learning for reinforcement learning. Furthermore, an enhanced version of this method — IER — turns out to be the state of the art and is the most stable experience replay technique on a variety of popular RL benchmarks.
Data efficiency
For many tasks, deep neural networks heavily rely on large datasets. In addition to the storage costs and potential security/privacy concerns that come along with large datasets, training modern deep neural networks on such datasets incurs high computational costs. One promising way to solve this problem is with data subset selection, where the learner aims to find the most informative subset from a large number of training samples to approximate (or even improve upon) training with the entire training set.
We analyzed a subset selection framework designed to work with arbitrary model families in a practical batch setting. In such a setting, a learner can sample examples one at a time, accessing both the context and true label, but in order to limit overhead costs, is only able to update its state (i.e., further train model weights) once a large enough batch of examples is selected. We developed an algorithm, called IWeS, that selects examples by importance sampling where the sampling probability assigned to each example is based on the entropy of models trained on previously selected batches. We provide a theoretical analysis, proving generalization and sampling rate bounds.
Another concern with training large networks is that they can be highly sensitive to distribution shifts between training data and data seen at deployment time, especially when working with limited amounts of training data that might not cover all of deployment time scenarios. A recent line of work has hypothesized “extreme simplicity bias” as the key issue behind this brittleness of neural networks. Our latest work makes this hypothesis actionable, leading to two new complementary approaches — DAFT and FRR — that when combined provide significantly more robust neural networks. In particular, these two approaches use adversarial fine-tuning along with inverse feature predictions to make the learned network robust.
Inference efficiency
Increasing the size of neural networks has proven surprisingly effective in improving their predictive accuracy. However, it is challenging to realize these gains in the real-world, as the inference costs of large models may be prohibitively high for deployment. This motivates strategies to improve the serving efficiency, without sacrificing accuracy. In 2022, we studied different strategies to achieve this, notably those based on knowledge distillation and adaptive computation.
Distillation
Distillation is a simple yet effective method for model compression, which greatly expands the potential applicability of large neural models. Distillation has proved widely effective in a range of practical applications, such as ads recommendation. Most use-cases of distillation involve a direct application of the basic recipe to the given domain, with limited understanding of when and why this ought to work. Our research this year has looked at tailoring distillation to specific settings and formally studying the factors that govern the success of distillation.
On the algorithmic side, by carefully modeling the noise in the teacher labels, we developed a principled approach to reweight the training examples, and a robust method to sample a subset of data to have the teacher label. In “Teacher Guided Training”, we presented a new distillation framework: rather than passively using the teacher to annotate a fixed dataset, we actively use the teacher to guide the selection of informative samples to annotate. This makes the distillation process shine in limited data or long-tail settings.
We also researched new recipes for distillation from a cross-encoder (e.g., BERT) to a factorized dual-encoder, an important setting for the task of scoring the relevance of a [query, document] pair. We studied the reasons for the performance gap between cross- and dual-encoders, noting that this can be the result of generalization rather than capacity limitation in dual-encoders. The careful construction of the loss function for distillation can mitigate this and reduce the gap between cross- and dual-encoder performance. Subsequently, in EmbedDistill, we looked at further improving dual-encoder distillation by matching embeddings from the teacher model. This strategy can also be used to distill from a large to small dual-encoder model, wherein inheriting and freezing the teacher’s document embeddings can prove highly effective.
 |
| In EmbedDistill, teacher to student distillation is done by designing new loss functions that match the geometry of student embeddings with that of the teacher in addition to matching the final predictions. |
On the theoretical side, we provided a new perspective on distillation through the lens of supervision complexity, a measure of how well the student can predict the teacher labels. Drawing on neural tangent kernel (NTK) theory, this offers conceptual insights, such as the fact that a capacity gap may affect distillation because such teachers’ labels may appear akin to purely random labels to the student. We further demonstrated that distillation can cause the student to underfit points the teacher model finds “hard” to model. Intuitively, this may help the student focus its limited capacity on those samples that it can reasonably model.
Adaptive computation
While distillation is an effective means of reducing inference cost, it does so uniformly across all samples. Intuitively however, some “easy” samples may inherently require less compute than the “hard” samples. The goal of adaptive compute is to design mechanisms that enable such sample-dependent computation.
Confident Adaptive Language Modeling (CALM) introduced a controlled early-exit functionality to Transformer-based text generators such as T5. In this form of adaptive computation, the model dynamically modifies the number of transformer layers that it uses per decoding step. The early-exit gates use a confidence measure with a decision threshold that is calibrated to satisfy statistical performance guarantees. In this way, the model needs to compute the full stack of decoder layers for only the most challenging predictions. Easier predictions only require computing a few decoder layers. In practice, the model uses about a third of the layers for prediction on average, yielding 2–3x speed-ups while preserving the same level of generation quality.
 |
| Text generation with a regular language model (top) and with CALM (bottom). CALM attempts to make early predictions. Once confident enough (darker blue tones), it skips ahead and saves time. |
One popular adaptive compute mechanism is a cascade of two or more base models. A key issue in using cascades is deciding whether to simply use the current model’s predictions, or whether to defer prediction to a downstream model. Learning when to defer requires designing a suitable loss function, which can leverage appropriate signals to act as supervision for the deferral decision. We formally studied existing loss functions for this goal, demonstrating that they may underfit the training sample owing to an implicit application of label smoothing. We showed that one can mitigate this with post-hoc training of a deferral rule, which does not require modifying the model internals in any way.
For the retrieval applications, standard semantic search techniques use a fixed representation for each embedding generated by a large model. That is, irrespective of downstream task and its associated compute environment or constraints, the representation size and capability is mostly fixed. Matryoshka representation learning introduces flexibility to adapt representations according to the deployment environment. That is, it forces representations to have a natural ordering within its coordinates such that for resource constrained environments, we can use only the top few coordinates of the representation, while for richer and precision-critical settings, we can use more coordinates of the representation. When combined with standard approximate nearest neighbor search techniques like ScaNN, MRL is able to provide up to 16x lower compute with the same recall and accuracy metrics.
Concluding thoughts
Large ML models are showing transformational outcomes in several domains but efficiency in both training and inference is emerging as a critical need to make these models practical in the real-world. Google Research has been investing significantly in making large ML models efficient by developing new foundational techniques. This is an on-going effort and over the next several months we will continue to explore core challenges to make ML models even more robust and efficient.
Acknowledgements
The work in efficient deep learning is a collaboration among many researchers from Google Research, including Amr Ahmed, Ehsan Amid, Rohan Anil, Mohammad Hossein Bateni, Gantavya Bhatt, Srinadh Bhojanapalli, Zhifeng Chen, Felix Chern, Gui Citovsky, Andrew Dai, Andy Davis, Zihao Deng, Giulia DeSalvo, Nan Du, Avi Dubey, Matthew Fahrbach, Ruiqi Guo, Blake Hechtman, Yanping Huang, Prateek Jain, Wittawat Jitkrittum, Seungyeon Kim, Ravi Kumar, Aditya Kusupati, James Laudon, Quoc Le, Daliang Li, Zonglin Li, Lovish Madaan, David Majnemer, Aditya Menon, Don Metzler, Vahab Mirrokni, Vaishnavh Nagarajan, Harikrishna Narasimhan, Rina Panigrahy, Srikumar Ramalingam, Ankit Singh Rawat, Sashank Reddi, Aniket Rege, Afshin Rostamizadeh, Tal Schuster, Si Si, Apurv Suman, Phil Sun, Erik Vee, Ke Ye, Chong You, Felix Yu, Manzil Zaheer, and Yanqi Zhou.
Google Research, 2022 & beyond
This was the fourth blog post in the “Google Research, 2022 & Beyond” series. Other posts in this series are listed in the table below:
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

July 7, 2026
The power of collaboration: How we can reduce traffic congestion- Algorithms & Theory ·
- Climate & Sustainability ·
- Data Mining & Modeling






