Operations research
Operations Research groups solve the toughest optimization problems both inside and outside Google.

Operations Research groups solve the toughest optimization problems both inside and outside Google.
About the team
Operations Research groups are involved in many areas throughout Google, running the gamut from fundamental research to enterprise-grade engineering. We are software engineers, research scientists, and data scientists who use integer programming, linear programming, constraint programming, and graph algorithms to solve problems at scale.
Across Google, Operations Research tackles challenges in areas as diverse as transportation, search, natural language understanding, machine vision, datacenter design, and robotics. With a strong commitment to open source, we're actively involved in helping solve problems outside Google as well in areas such as aviation and health care.
Team focus summaries
Given a fleet of vehicles and a set of tasks to be performed, what are good routes to take? Such problems crop up frequently in government, logistics, manufacturing, and retail.
Networks are at the core of many engineering problems. How can you maximize the throughput of a computer network? How can you load-balance scarce resources? Algorithms like max flow and min-cost flow provide the starting points for systems that need to move items through a complex network.
Operations Research began with a seemingly simple question: how can you solve a large set of linear inequalities as efficiently as possible? Research continues to this day.
Many optimization problems involve discrete variables: people, places, and things. A mixed-integer programming problem generalizes linear programming to include discrete variables, with applications to supply chain management, scheduling, bin-packing problems, and much more.
It's often convenient to express optimization problems simply as a set of constraints, variables, and a function to be minimized or maximized. Constraint propagation, aided by heuristics and local search, are used to manage exponentially large search trees.
Featured publications
Highlighted work
-
 Operations Research at GoogleAdvanced analytics permeates work at Google, making the multitechnology giant a "candy store for O.R. practitioners".
Operations Research at GoogleAdvanced analytics permeates work at Google, making the multitechnology giant a "candy store for O.R. practitioners". -
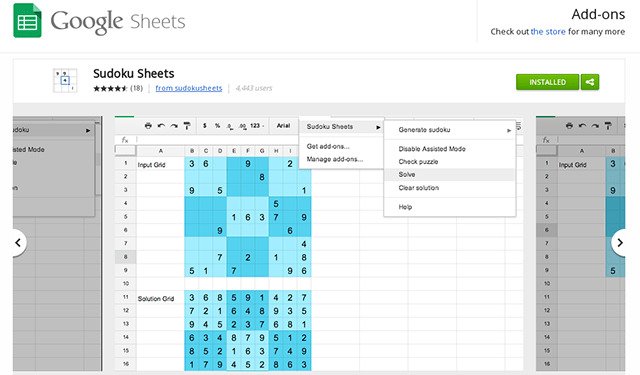 Sudoku, Linear Optimization, and the Ten Cent DietGoogle's open source linear programming solver was used to solve a storied problem faster than ever before, culminating in lunch.
Sudoku, Linear Optimization, and the Ten Cent DietGoogle's open source linear programming solver was used to solve a storied problem faster than ever before, culminating in lunch. -
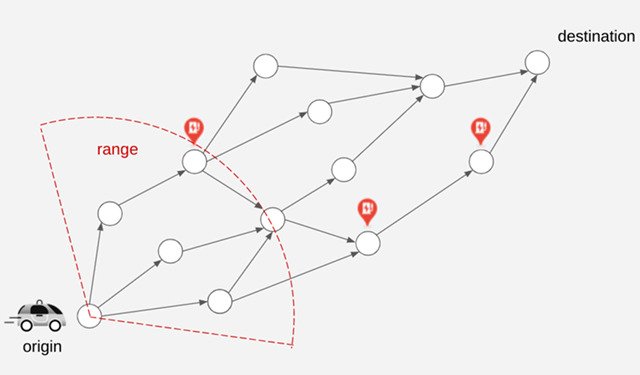 Addressing Range Anxiety with Smart Electric Vehicle RoutingGoogle presents a new approach for routing of EVs integrated into the latest release of Google Maps built into your car for participating EVs that reduces range anxiety by integrating recharging stations into the navigational route.
Addressing Range Anxiety with Smart Electric Vehicle RoutingGoogle presents a new approach for routing of EVs integrated into the latest release of Google Maps built into your car for participating EVs that reduces range anxiety by integrating recharging stations into the navigational route.
Some of our locations




Some of our people
-

David Applegate
- Algorithms and Theory
-

Aaron Archer
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +3 more
-

Bruno De Backer
- Algorithms and Theory
- Hardware and Architecture
-

Frederic Didier
- Algorithms and Theory
- Machine Intelligence
-

Alejandra Estanislao
- Algorithms and Theory
-

Vincent Furnon
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
- +1 more
-

Sreenivas Gollapudi
- Algorithms and Theory
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Emmanuel Guere
- Algorithms and Theory
- Machine Intelligence
- Software Engineering
-

Anne-Claire Haury
- Machine Intelligence
-
Ravi Kumar
- Algorithms and Theory
- Data Mining and Modeling
- Information Retrieval and the Web
-

bertrand Le cun
- Algorithms and Theory
-

Pawel Lichocki
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- General Science
- +1 more
-

Jon Orwant
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Information Retrieval and the Web
- +3 more
-

Erik Vee
- Algorithms and Theory
- Economics and Electronic Commerce
- Information Retrieval and the Web
- +2 more
-
Manish Purohit
- Algorithms and Theory
- Machine Intelligence
-

Stéphane Soppera
- Algorithms and Theory
- Machine Intelligence
- Software Engineering
-

Sara Ahmadian
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +3 more
-

Fabien Viger
- Algorithms and Theory
- Machine Intelligence
-

Rich Washington
- Algorithms and Theory
- Machine Intelligence
-

Juan Pablo Vielma
- Algorithms and Theory
- Machine Intelligence
-

Vahab S. Mirrokni
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +4 more
-

Ana Radovanovic
- Algorithms and Theory
- Economics and Electronic Commerce
- General Science
- +1 more
-

Mohammadhossein Bateni
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-

Hossein Esfandiari
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Economics and Electronic Commerce
- +2 more
-

Matthew Fahrbach
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-

Morteza Zadimoghaddam
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Economics and Electronic Commerce
- +1 more
