Health AI
AI has the potential to accelerate innovation and unlock new solutions to global health challenges, to help billions of people live longer, healthier lives.

AI has the potential to accelerate innovation and unlock new solutions to global health challenges, to help billions of people live longer, healthier lives.
Addressing critical healthcare challenges
From genomics and diagnostics to public health, we’re advancing AI research to address real-world healthcare challenges. Today’s powerful models and tools have the potential to make healthcare more personalized, diseases more detectable and treatable and public health ecosystems more resilient.
Partnering with the ecosystem
We collaborate with world-class academic and scientific institutions, along with healthcare providers, to research cutting-edge AI solutions responsibly and ensure that our innovations are safe and helpful in clinical settings.
-
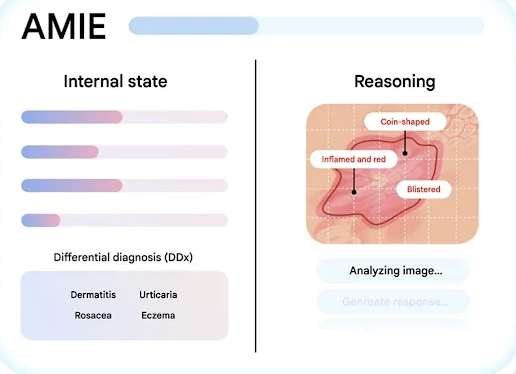 Conversational AI for clinicians and patients
Conversational AI for clinicians and patientsAMIE (Articulate Medical Intelligence Explorer) is a research-grade AI system with diagnostic reasoning. It’s designed to act as a conversational partner capable of conducting complex medical interviews and clinical history-taking.
-
 AI for cancer diagnosis
AI for cancer diagnosisEarly breast cancer detection can save lives. Our experimental research with Imperial College London and the UK’s National Health Service demonstrates AI’s potential to detect 25% of the interval cancers previously missed, and reduce radiologists’ workloads.
-
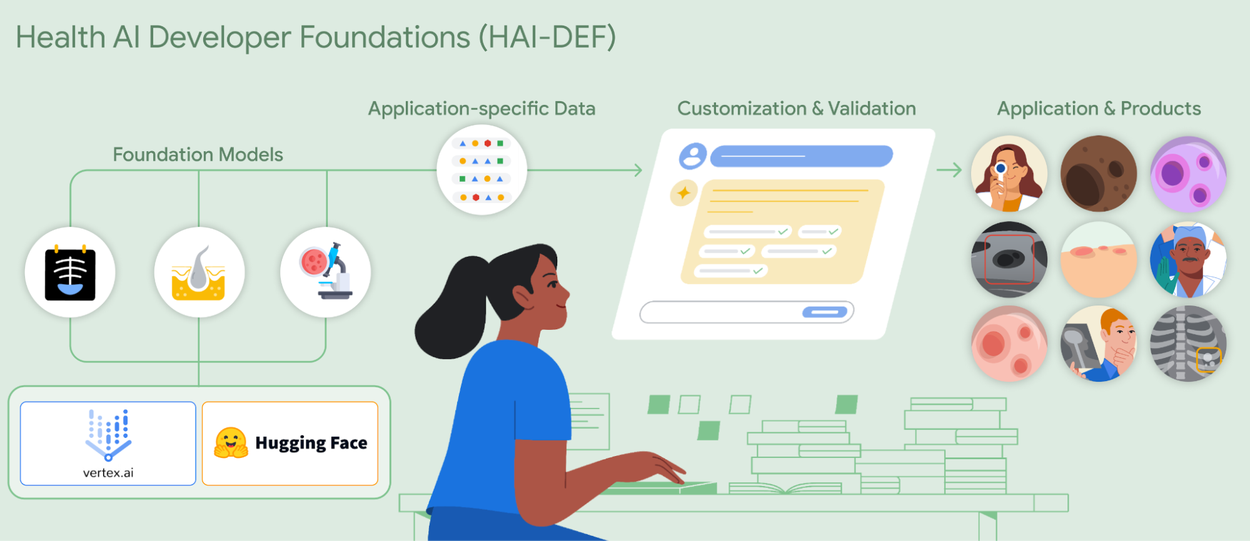 AI building blocks for developers
AI building blocks for developersOur Health AI Developer Foundations (HAI-DEF), including our open MedGemma models, provide a launchpad for developers to build and fine-tune AI-enabled, next generation healthcare applications.
-
 Google Earth AI for public health
Google Earth AI for public healthWe’re harnessing our advanced geospatial models to provide insights on population behaviors and environmental factors. This can empower the global public health community to predict outbreaks, identify local vulnerabilities and deliver proactive care where it’s needed most.
-
 Genomics research powered by AI
Genomics research powered by AIOur deep learning tools in genomics are routinely run by scientists worldwide to accelerate scientific discovery and healthcare. Tools like DeepSomatic, DeepVariant and DeepConsensus help the genomics community get the most out of their data.

