Resources
We believe in an open, collaborative research ecosystem. To support the next generation of breakthroughs, we share our tools, datasets, and models with the global community. These resources can serve as the building blocks for shared innovation, enabling us to solve complex challenges more effectively, together.

We believe in an open, collaborative research ecosystem. To support the next generation of breakthroughs, we share our tools, datasets, and models with the global community. These resources can serve as the building blocks for shared innovation, enabling us to solve complex challenges more effectively, together.
Resources
Datasets
Explore foundational data to power your next discovery. We offer a diverse range of high-quality, benchmark-ready datasets and partner with global platforms to ensure our resources remain open and accessible to the entire research community.
-
 Google Research Datasets
Google Research DatasetsDive into curated datasets across diverse computer science disciplines, released to help you validate theories and advance the state of the art.
-
 Kaggle x Google
Kaggle x GoogleExplore, analyze, and compete using Google datasets within a premier global community of data scientists.
-
 Hugging Face x Google
Hugging Face x GoogleAccess and collaborate on Google’s open-source models and datasets to build and scale your AI applications.
-
 Dataset Search
Dataset SearchDiscover thousands of datasets hosted across the web using a simple, unified search interface.
-
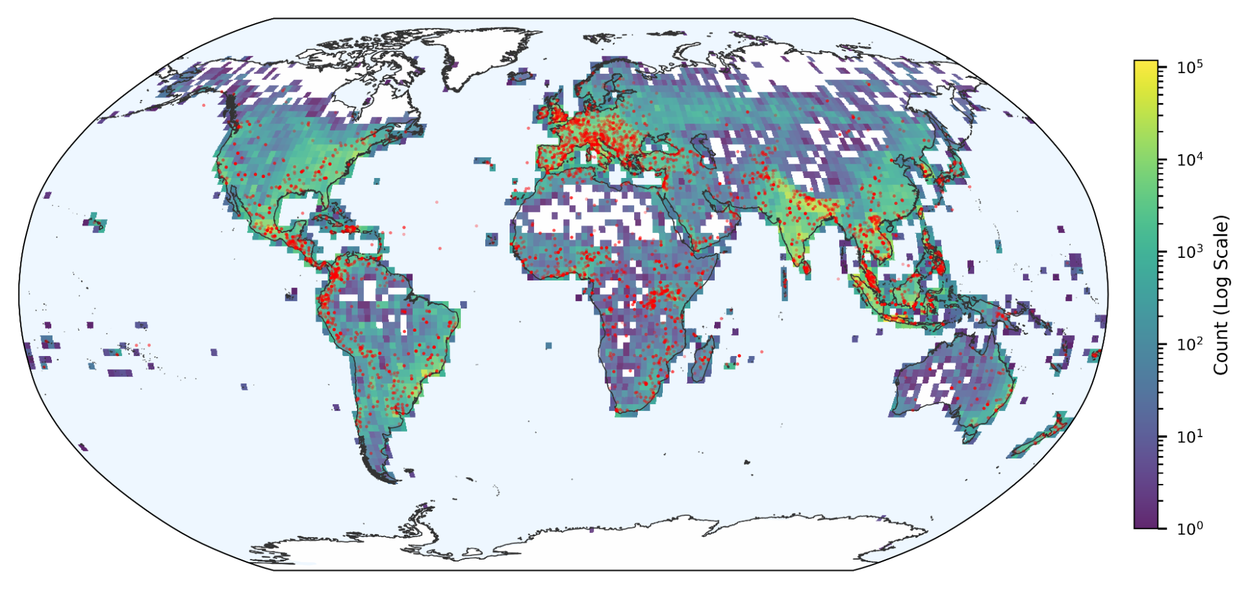 Groundsource
GroundsourceAn open global dataset of 2.6 million historical flood events derived from news articles spanning more than 150 countries for hydrologic research.
-
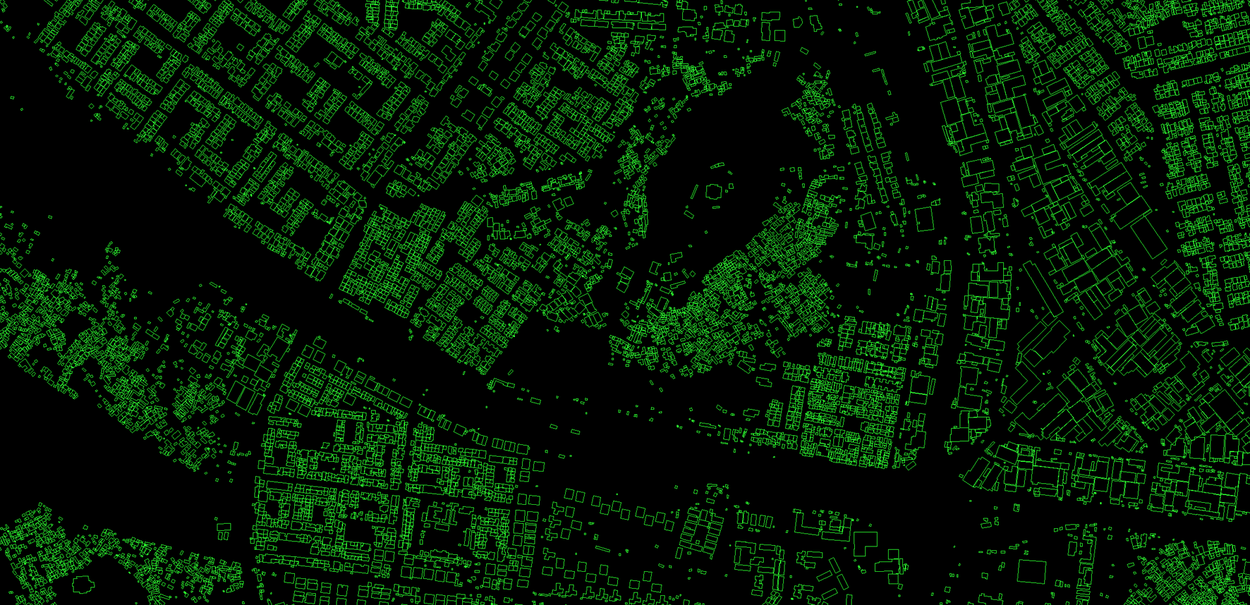 Open Buildings
Open BuildingsBuilding outlines derived from satellite imagery to support urban planning and humanitarian research.
Tools & services
Access the foundational infrastructure and tools used by Google Research to build, train, and deploy next-generation models and scientific applications.
Development Foundations


Frontier Models & Prototyping
-

API
Gemini APIIntegrate our most capable AI models into your applications and research workflows.
-

PLATFORM
AI StudioUse natural language to generate fully functional apps with cutting-edge AI models and tools.
-

SERVICE
Vertex AIExplore 200+ models on our enterprise platform with tools and features for AI development.
AI & Society
-
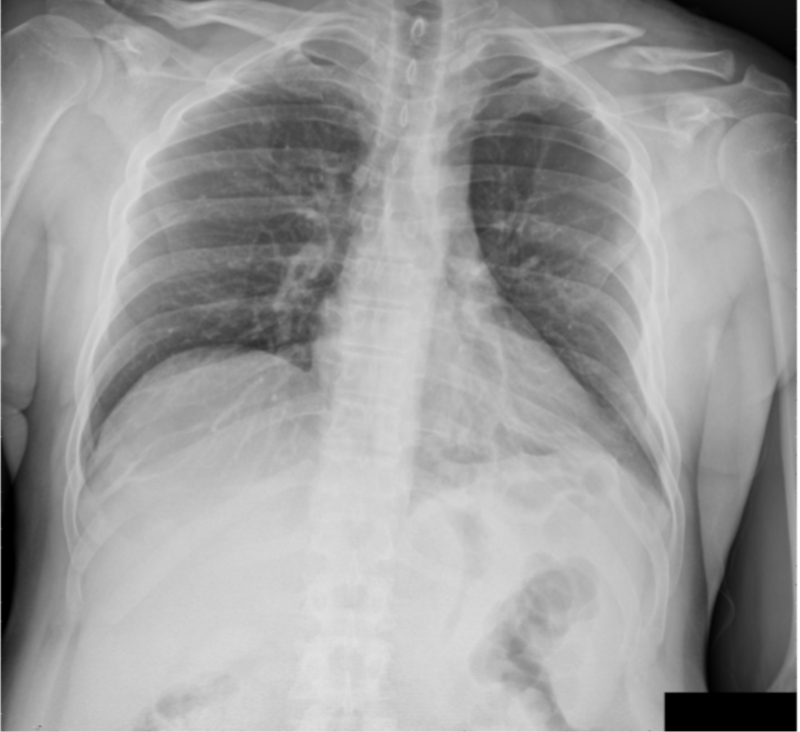
MODELS
Medical AIAccess a suite of domain-specific foundation models and specialized tools designed to accelerate clinical research and medical applications.
-
API
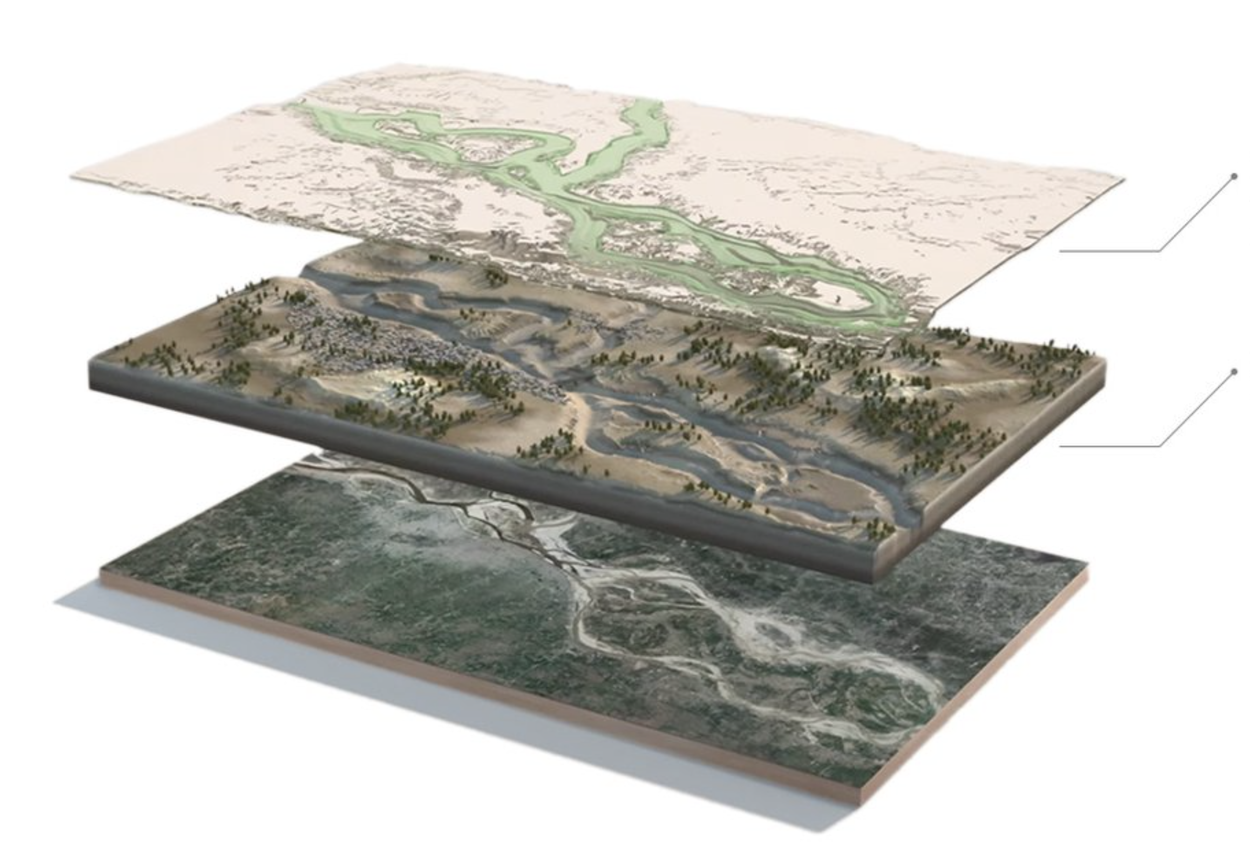
Flood ForecastingAccess real-time river status and hydrologic forecasts through our research pilot program.
-
LIBRARY
Differential PrivacyEnable privacy-preserving machine learning and analytics with our open-source libraries.
Infrastructure & Scale
-
LIBRARY
OR-ToolsSolve complex combinatorial optimization problems with our fast and portable software suite.
-

PROGRAM
TPU Research CloudApply for access to a cluster of over 1,000 Cloud TPUs to accelerate the next wave of breakthroughs.
-

PRODUCT
Cloud TPU ML AcceleratorsTrain and run machine learning models faster than ever before with purpose-built hardware.
Open source
Innovation thrives through open exchange. We share our code, toolkits, and model weights to provide the research community with flexible building blocks for the next wave of scientific discovery.
-

MODEL
GemmaBuild responsible AI applications at scale with our most capable open models.
-

TOOLKIT
The Data Cards PlaybookA toolkit for transparency in AI dataset documentation.
-

REPOSITORY
Google Research GitHubExplore open-source implementations and codebases released by our research teams.
-
PORTAL
Google Open SourceAccess Google’s broader initiatives and projects that support the open-source ecosystem.
-
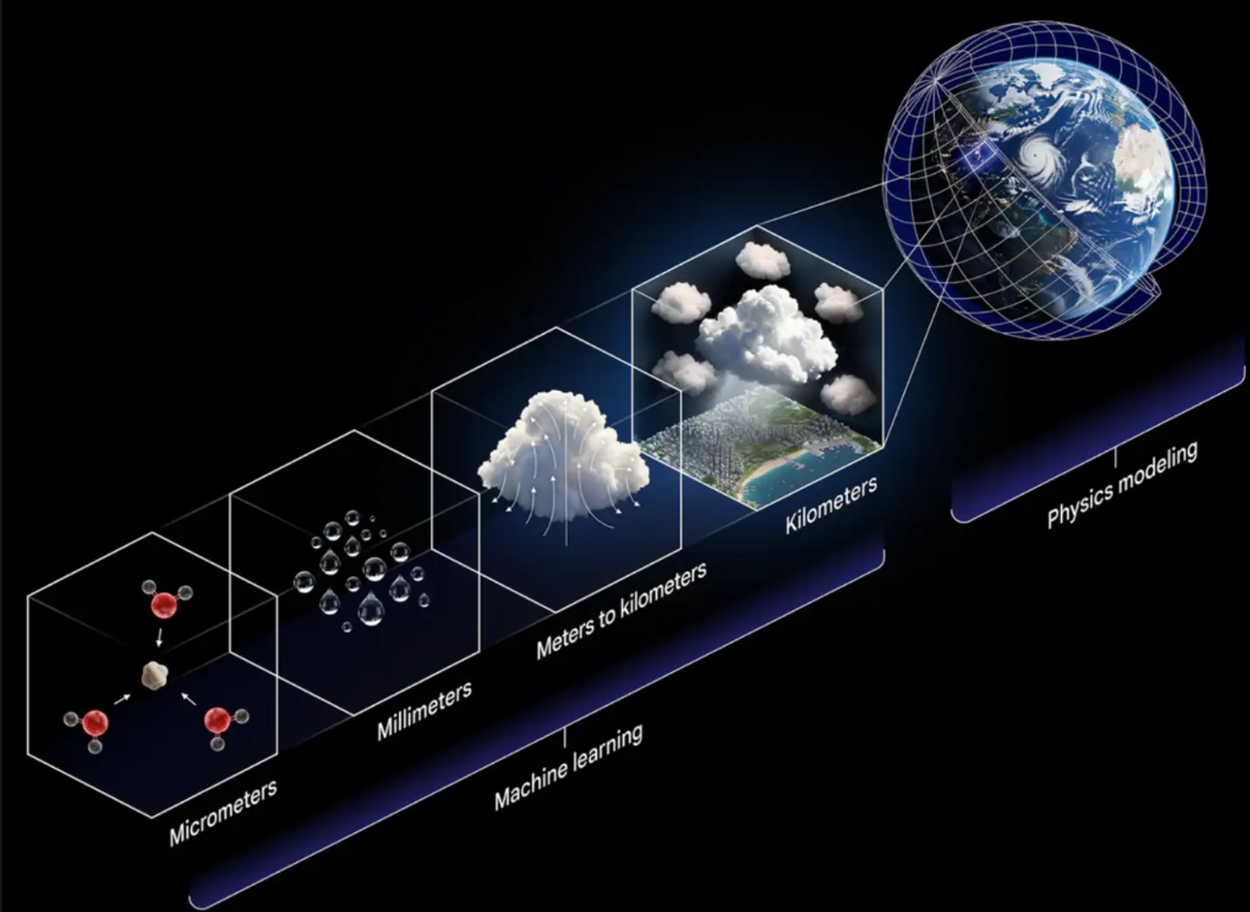
MODEL
NeuralGCMExplore hybrid AI-atmospheric models designed for high-fidelity weather and climate simulation.
-
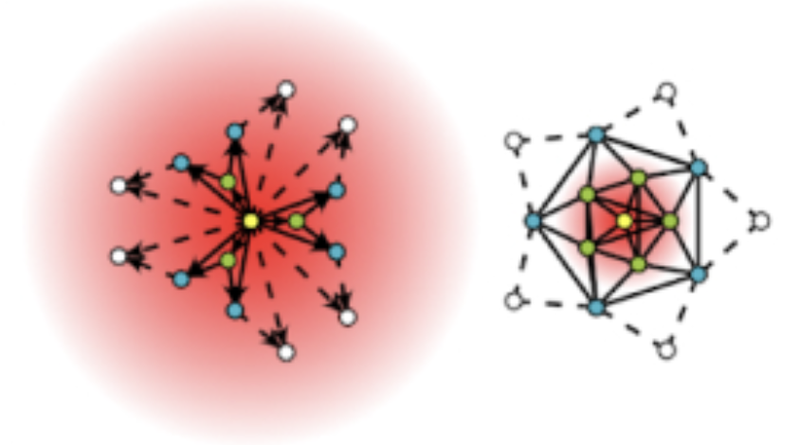
REPOSITORY
Graph MiningScalable algorithms and frameworks for solving data mining and ML problems with graph structures.
-

REPOSITORY
DeepVariantAn open-source analysis pipeline using deep learning to call genetic variants from DNA sequencing data.