Large-scale optimization
Our mission is to develop large-scale optimization techniques and use them to improve the efficiency and robustness of infrastructure at Google.
About the team
We apply techniques from large-scale combinatorial optimization, online algorithms, and control theory to make Google’s computing infrastructure do more with less. We combine online and offline optimizations to achieve goals such as reducing search query latency, increasing model inference throughput and prediction quality, minimizing resource contention, maximizing the efficacy of caches, and eliminating unnecessary work in distributed systems. Our research is used in critical infrastructure that supports Search, Ads, Gemini, YouTube, and Cloud products.
Team focus summaries
We developed and deployed load balancing tools based on the power-of-d-choices paradigm for Google’s distributed serving systems. Our tools drive most of the YouTube serving stack and have also found success in Search Ads, logs processing, and serving ML models, where they have greatly improved tail latencies and error rates while saving resources by allowing our systems to run at higher utilizations.
We developed a linear programming (LP) solver that can solve instances with 100 billion non-zeros, which is about 1000x larger than the previous state-of-the-art. To achieve this scale, we rely on first-order methods where the bottleneck operations are matrix-vector multiplications, so we can avoid factoring matrices. This allows us to circumvent the memory scaling bottleneck faced by traditional LP solvers. The in-memory, multi-core version of our solver is open-sourced as PDLP, within Google's OR-Tools library.
Optimizing ML model structures (e.g., feature selection, embedding table optimization, matrix sparsification, and neural architecture search) is a core problem with a significant impact on prediction quality, resource efficiency, and ultimately revenue. These are often NP-hard combinatorial optimization problems, so we developed efficient differentiable search techniques (e.g., Sequential Attention) to tackle these problems at scale, while offering provable guarantees.
Several of our projects have partnered with product teams to help improve the efficiency of Google's search infrastructure. In the backend for web search, we introduced a distributed feedback control loop to govern the way queries are fanned out to worker machines, in order to balance load better by taking advantage of real-time load information on the workers. We also improved the efficacy of caching by increasing the homogeneity of the stream of queries seen by any single worker machine. To accomplish this, we clustered query terms, used these clusters to define voting weights, and assigned queries to workers on the basis of votes cast by the terms in the query. In a pub-sub system that powers some of our display ads, we saved computation by clustering some components of subscriptions in a way that lets us take advantage of bitwise-parallel CPU operations.
Composable core-sets provide an effective method for solving optimization problems on massive datasets. The main idea is to partition data among some number of machines, and use each machine to compute some small summary/sketch of the data. After gathering all summaries on one machine, we solve the original optimization problem on the combined sketch.
Maximum coverage and minimum set-cover problems are among the fundamental problems in combinatorial optimization and have a variety of applications in machine learning and data mining. We study these problems in the streaming and MapReduce models of computation, and develop practical algorithms with tight theoretical bounds for runtime, space and approximation guarantee. Our main idea is a novel sketching technique that compresses the input into a small space, independent of the size of the ground set, without hurting the quality by much.
We design memoryless balanced allocation algorithms to assign a dynamic set of tasks to a dynamic set of servers such that the load (the number of assigned tasks) on each server is bounded, and the allocation does not change by much for every update operation.
Featured publications
Highlighted work
-
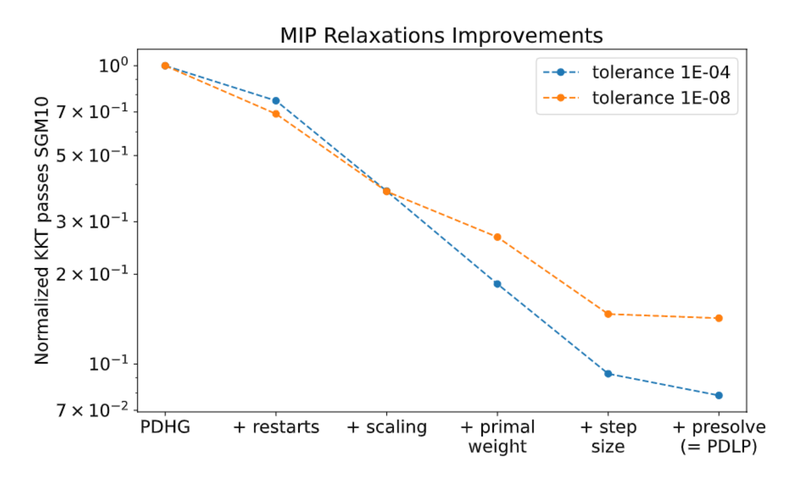 Practical Large-Scale Linear Programming using Primal-Dual Hybrid GradientMathematical background for developers and advanced users of PDLP, a linear and quadratic programming solver available in OR-Tools.
Practical Large-Scale Linear Programming using Primal-Dual Hybrid GradientMathematical background for developers and advanced users of PDLP, a linear and quadratic programming solver available in OR-Tools. -
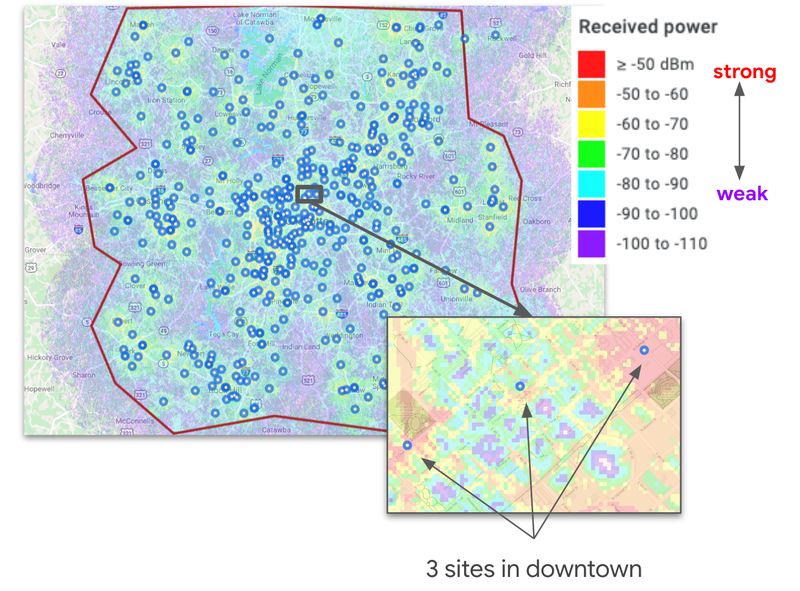 Challenges in Multi-objective Optimization for Automatic Wireless Network PlanningThis blog post describes our efforts to address the most vexing challenges facing telecom network operators, including how we built a scalable auto-planner for wireless telecommunication networks using combinatorial optimization in concert with geospatial and radio propagation modeling.
Challenges in Multi-objective Optimization for Automatic Wireless Network PlanningThis blog post describes our efforts to address the most vexing challenges facing telecom network operators, including how we built a scalable auto-planner for wireless telecommunication networks using combinatorial optimization in concert with geospatial and radio propagation modeling. -
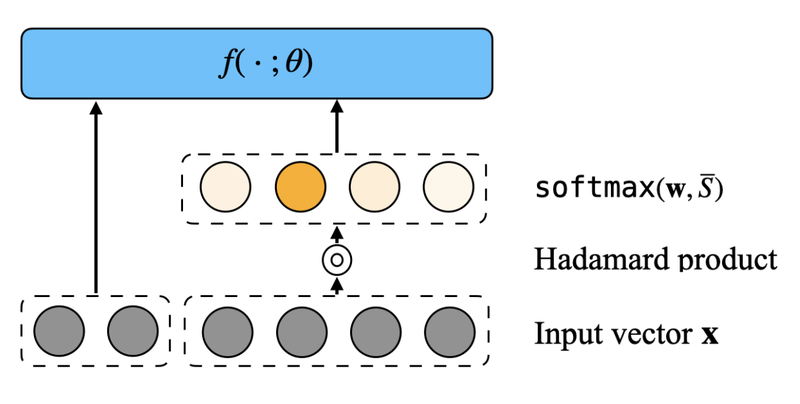 Sequential AttentionWe propose a feature selection algorithm called Sequential Attention (ICLR 2023) that achieves state-of-the-art empirical results for neural networks. This algorithm is an efficient one-pass implementation of greedy forward selection and uses attention weights at each step as a proxy for feature importance.
Sequential AttentionWe propose a feature selection algorithm called Sequential Attention (ICLR 2023) that achieves state-of-the-art empirical results for neural networks. This algorithm is an efficient one-pass implementation of greedy forward selection and uses attention weights at each step as a proxy for feature importance. -
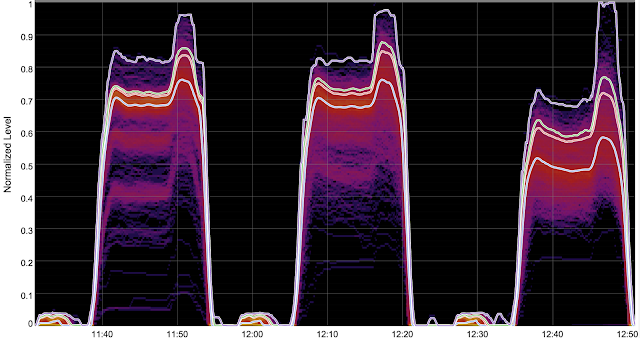 Cache-Aware Load Balancing of Data Center ApplicationsThis paper proposes a method of affinitizing multi-key lookups to minimize cache misses in replicated key-value stores. The method uses offline graph clustering to create a lookup table, paired with a voting scheme to select replicas at serving time. Google web search applied this technique to postings list retrieval, where the improved caching efficiency increased throughput by nearly 50%.
Cache-Aware Load Balancing of Data Center ApplicationsThis paper proposes a method of affinitizing multi-key lookups to minimize cache misses in replicated key-value stores. The method uses offline graph clustering to create a lookup table, paired with a voting scheme to select replicas at serving time. Google web search applied this technique to postings list retrieval, where the improved caching efficiency increased throughput by nearly 50%. -
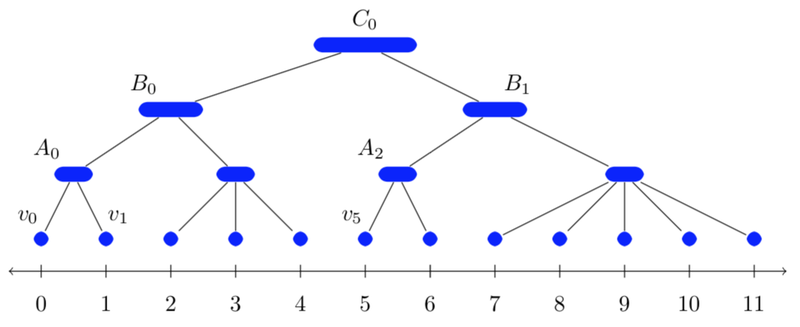 Balanced Partitioning and Hierarchical Clustering at ScaleThis blog post covers our efforts on balanced partitioning and hierarchical clustering at scale. Specifically, it discusses solving large-scale optimization problems and introduces an algorithm for partitioning graphs into clusters to be processed on different machines.
Balanced Partitioning and Hierarchical Clustering at ScaleThis blog post covers our efforts on balanced partitioning and hierarchical clustering at scale. Specifically, it discusses solving large-scale optimization problems and introduces an algorithm for partitioning graphs into clusters to be processed on different machines. -
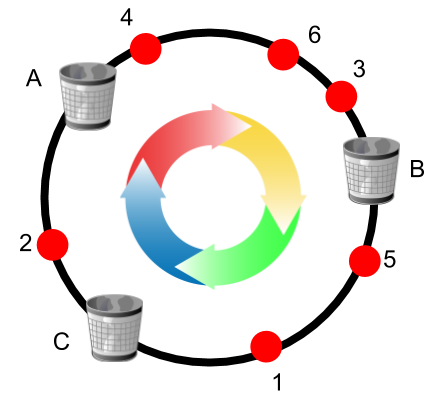 Consistent Hashing with Bounded LoadsThis blog post is about consistent hashing with bounded loads. It discusses balancing loads across servers while allowing servers and clients to be added or removed. We also limit the change to the solution in this dynamic environment. We proposed a novel algorithm that achieves both uniformity and consistency (SODA 2018). Applications of this work have also been discussed in a popular Vimeo engineering blog post.
Consistent Hashing with Bounded LoadsThis blog post is about consistent hashing with bounded loads. It discusses balancing loads across servers while allowing servers and clients to be added or removed. We also limit the change to the solution in this dynamic environment. We proposed a novel algorithm that achieves both uniformity and consistency (SODA 2018). Applications of this work have also been discussed in a popular Vimeo engineering blog post. -
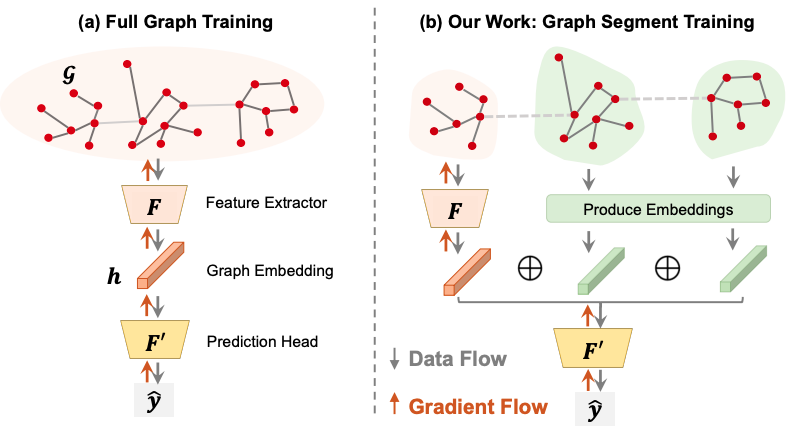 Advancements in Machine Learning for Machine LearningThis blog post presents exciting advancements in ML for ML. In particular, how we use ML to improve efficiency of ML workloads.
Advancements in Machine Learning for Machine LearningThis blog post presents exciting advancements in ML for ML. In particular, how we use ML to improve efficiency of ML workloads. -
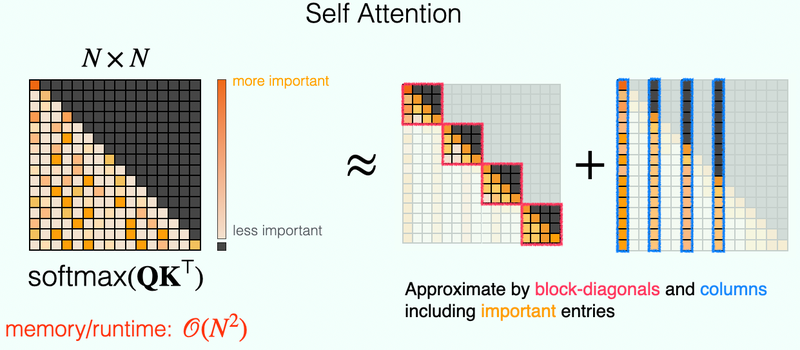 HyperAttention: Large-Scale Attention in Linear TimeThis work introduces a novel approximate self-attention mechanism dubbed "HyperAttention", offering provable linear time complexity in the size of the context while only incurring a negligible loss in downstream quality.
HyperAttention: Large-Scale Attention in Linear TimeThis work introduces a novel approximate self-attention mechanism dubbed "HyperAttention", offering provable linear time complexity in the size of the context while only incurring a negligible loss in downstream quality. -
 Randomized Experimental Design via Geographic ClusteringThis work studies experimental design in the presence of interference where the treatment of one group may affect the outcomes of others. It shows how to define units or clusters of units with limited interference while maintaining experimental power.
Randomized Experimental Design via Geographic ClusteringThis work studies experimental design in the presence of interference where the treatment of one group may affect the outcomes of others. It shows how to define units or clusters of units with limited interference while maintaining experimental power.
Some of our locations




Some of our people
-

David Applegate
- Algorithms and Theory
-

Aaron Archer
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +3 more
-

Kevin Aydin
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +3 more
-

Mohammadhossein Bateni
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-

Lin Chen
- Algorithms and Theory
- Machine Intelligence
-

David Eisenstat
- Algorithms and Theory
-

Matthew Fahrbach
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-
Gang (Thomas) Fu
- Machine Learning
-

Joey Huchette
- Algorithms and Theory
- Machine Intelligence
-

Siddhartha Visveswara Jayanti
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +3 more
-

Rajesh Jayaram
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-

Vahab S. Mirrokni
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +4 more
-

Jon Orwant
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Information Retrieval and the Web
- +3 more
-
Jon Schneider
- Algorithms and Theory
- Economics and Electronic Commerce
-

Morteza Zadimoghaddam
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Economics and Electronic Commerce
- +1 more
-
Pratik Worah
- Algorithms and Theory
- Machine Intelligence
