Consistent Hashing with Bounded Loads
April 3, 2017
Posted by Vahab Mirrokni, Principal Scientist, Morteza Zadimoghaddam, Research Scientist, NYC Algorithms Team
Quick links
Running a large-scale web service, such as content hosting, necessarily requires load balancing — distributing clients uniformly across multiple servers such that none get overloaded. Further, it is desirable to find an allocation that does not change very much over time in a dynamic environment in which both clients and servers can be added or removed at any time. In other words, we need the allocation of clients to servers to be consistent over time.
In collaboration with Mikkel Thorup, a visiting researcher from university of Copenhagen, we developed a new efficient allocation algorithm for this problem with tight guarantees on the maximum load of each server, and studied it theoretically and empirically. We then worked with our Cloud team to implement it in Google Cloud Pub/Sub, a scalable event streaming service, and observed substantial improvement on uniformity of the load allocation (in terms of the maximum load assigned to servers) while maintaining consistency and stability objectives. In August 2016 we described our algorithm in the paper “Consistent Hashing with Bounded Loads”, and shared it on ArXiv for potential use by the broader research community.
Three months later, Andrew Rodland from Vimeo informed us that he had found the paper, implemented it in haproxy (a widely-used piece of open source software), and used it for their load balancing project at Vimeo. The results were dramatic: applying these algorithmic ideas helped them decrease the cache bandwidth by a factor of almost 8, eliminating a scaling bottleneck. He recently summarized this story in a blog post detailing his use case. Needless to say, we were excited to learn that our theoretical research was not only put into application, but also that it was useful and open-sourced.
Background
While the concept of consistent hashing has been developed in the past to deal with load balancing in dynamic environments, a fundamental issue with all the previously developed schemes is that, in certain scenarios, they may result in sub-optimal load balancing on many servers.
Additionally, both clients and servers may be added or removed periodically, and with such changes, we do not want to move too many clients. Thus, while the dynamic allocation algorithm has to always ensure a proper load balancing, it should also aim to minimize the number of clients moved after each change to the system. Such allocation problems become even more challenging when we face hard constraints on the capacity of each server - that is, each server has a capacity that the load may not exceed. Typically, we want capacities close to the average loads.
In other words, we want to simultaneously achieve both uniformity and consistency in the resulting allocations. There is a vast amount of literature on solutions in the much simpler case where the set of servers is fixed and only the client set is updated, but in this post we discuss solutions that are relevant in the fully dynamic case where both clients and servers can be added and removed.
The Algorithm
We can think about the servers as bins and clients as balls to have a similar notation with well-studied balls-to-bins stochastic processes. The uniformity objective encourages all bins to have a load roughly equal to the average density (the number of balls divided by the number of bins). For some parameter ε, we set the capacity of each bin to either floor or ceiling of the average load times (1+ε). This extra capacity allows us to design an allocation algorithm that meets the consistency objective in addition to the uniformity property.
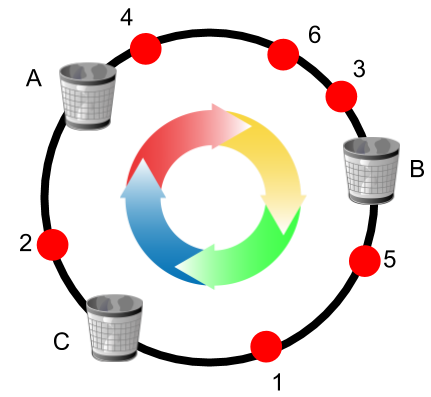
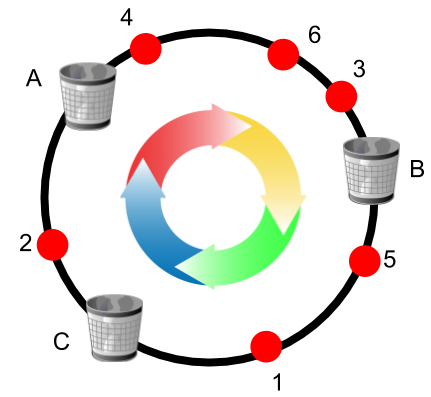
Imagine a given range of numbers overlaid on a circle. We apply a hash function to balls and a separate hash function to bins to obtain numbers in that range that correspond to positions on that circle. We then start allocating balls in a specific order independent of their hash values (let’s say based on their ID). Then each ball is moved clockwise and is assigned to the first bin with spare capacity.

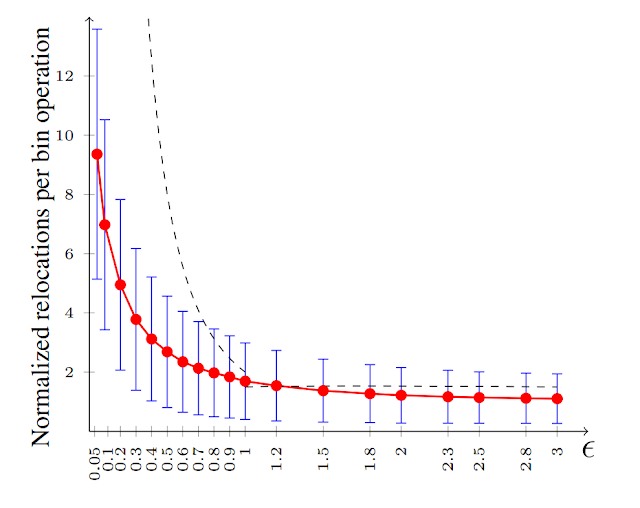
Upon any update in the system (ball or bin insertion/deletion), the allocation is recomputed to keep the uniformity objective. The art of the analysis is to show that a small update (a few number of insertions and deletions) results in minor changes in the state of the allocation and therefore the consistency objective is met. In our paper we show that every ball removal or insertion in the system results in O(1/ε2) movements of other balls. The most important thing about this upper bound is that it is independent of the total number of balls or bins in the system. So if the number of balls or bins are doubled, this bound will not change. Having an upper bound independent of the number of balls or bins introduces room for scalability as the consistency objective is not violated if we move to bigger instances. Simulations for the number of movements (relocations) per update is shown below when an update occurs on a bin/server.

 |
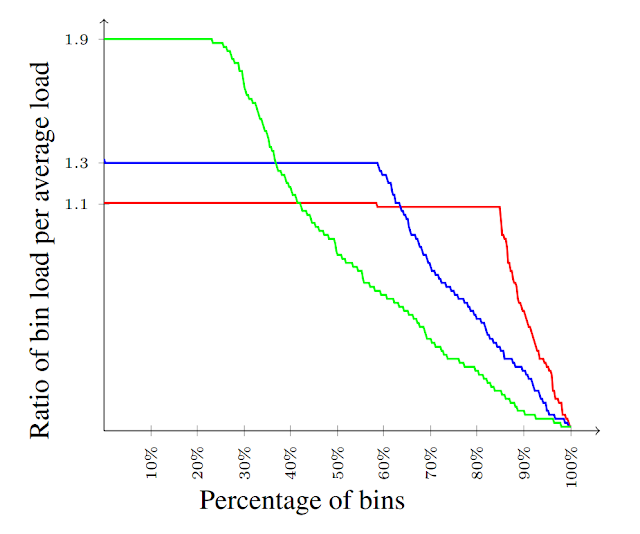
| The distribution of loads for several values of ε. The load distribution is nearly uniform covering all ranges of loads from 0 to (1+ε) times average, and many bins with load equal to (1+ε) times average. |
When providing content hosting services, one must be ready to face a variety of instances with different characteristics. This consistent hashing scheme is ideal for such scenarios as it performs well even for worst-case instances.
While our internal results are exciting, we are even more pleased that the broader community found our solution useful enough to open-source, allowing anyone to use this algorithm. If you are interested in further details of this research, please see the paper on ArXiv, and stay tuned for more research from the NYC Algorithms Team!
Acknowledgements:
We would like to thank Alex Totok, Matt Gruskin, Sergey Kondratyev and Haakon Ringberg from the Google Cloud Pub/Sub team, and of course Mikkel Thorup for his invaluable contributions to this paper.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 7, 2026
The power of collaboration: How we can reduce traffic congestion- Algorithms & Theory ·
- Climate & Sustainability ·
- Data Mining & Modeling
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product
×
❮
❯