Extracting Skill-Centric State Abstractions from Value Functions
April 29, 2022
Posted by Dhruv Shah, Intern, and Brian Ichter, Research Scientist, Robotics at Google
Quick links
Advances in reinforcement learning (RL) for robotics have enabled robotic agents to perform increasingly complex tasks in challenging environments. Recent results show that robots can learn to fold clothes, dexterously manipulate a rubik’s cube, sort objects by color, navigate complex environments and walk on difficult, uneven terrain. But "short-horizon" tasks such as these, which require very little long-term planning and provide immediate failure feedback, are relatively easy to train compared to many tasks that may confront a robot in a real-world setting. Unfortunately, scaling such short-horizon skills to the abstract, long horizons of real-world tasks is difficult. For example, how would one train a robot capable of picking up objects to rearrange a room?
Hierarchical reinforcement learning (HRL), a popular way of solving this problem, has achieved some success in a variety of long-horizon RL tasks. HRL aims to solve such problems by reasoning over a bank of low-level skills, thus providing an abstraction for actions. However, the high-level planning problem can be further simplified by abstracting both states and actions. For example, consider a tabletop rearrangement task, where a robot is tasked with interacting with objects on a desk. Using recent advances in RL, imitation learning, and unsupervised skill discovery, it is possible to obtain a set of primitive manipulation skills such as opening or closing drawers, picking or placing objects, etc. However, even for the simple task of putting a block into the drawer, chaining these skills together is not straightforward. This may be attributed to a combination of (i) challenges with planning and reasoning over long horizons, and (ii) dealing with high dimensional observations while parsing the semantics and affordances of the scene, i.e., where and when the skill can be used.
In “Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning”, presented at ICLR 2022, we address the task of learning suitable state and action abstractions for long-range problems. We posit that a minimal, but complete, representation for a higher-level policy in HRL must depend on the capabilities of the skills available to it. We present a simple mechanism to obtain such a representation using skill value functions and show that such an approach improves long-horizon performance in both model-based and model-free RL and enables better zero-shot generalization.
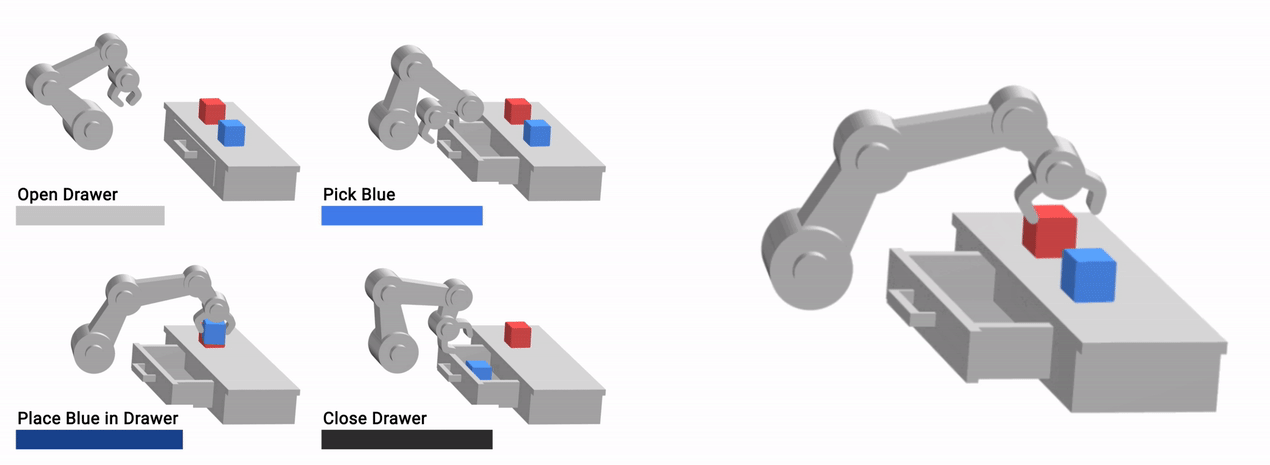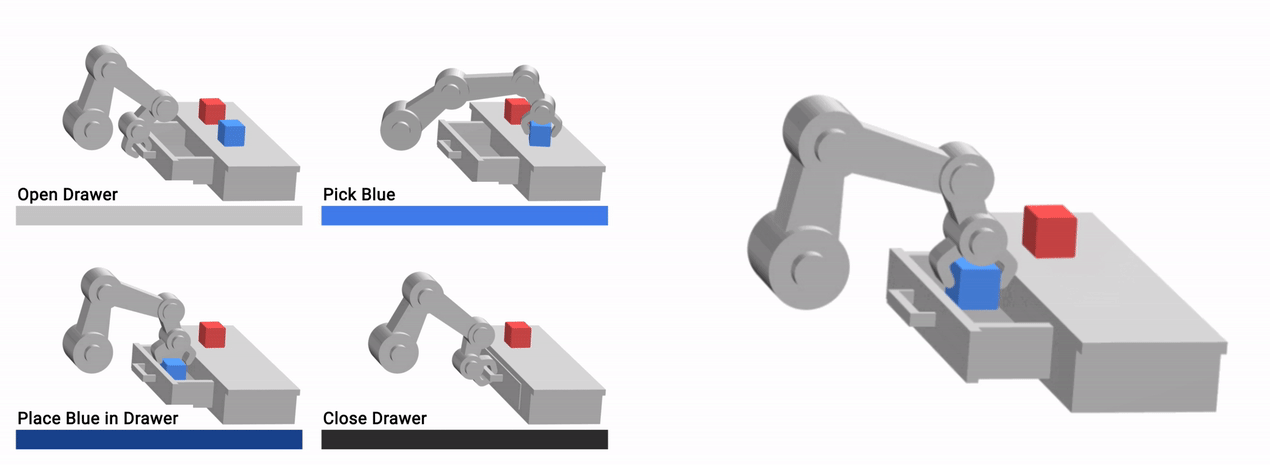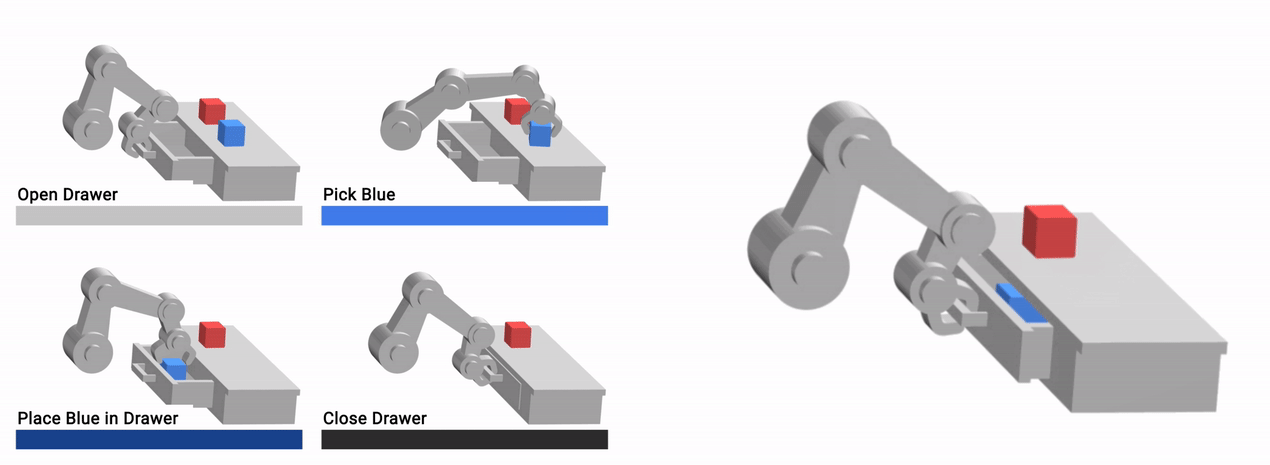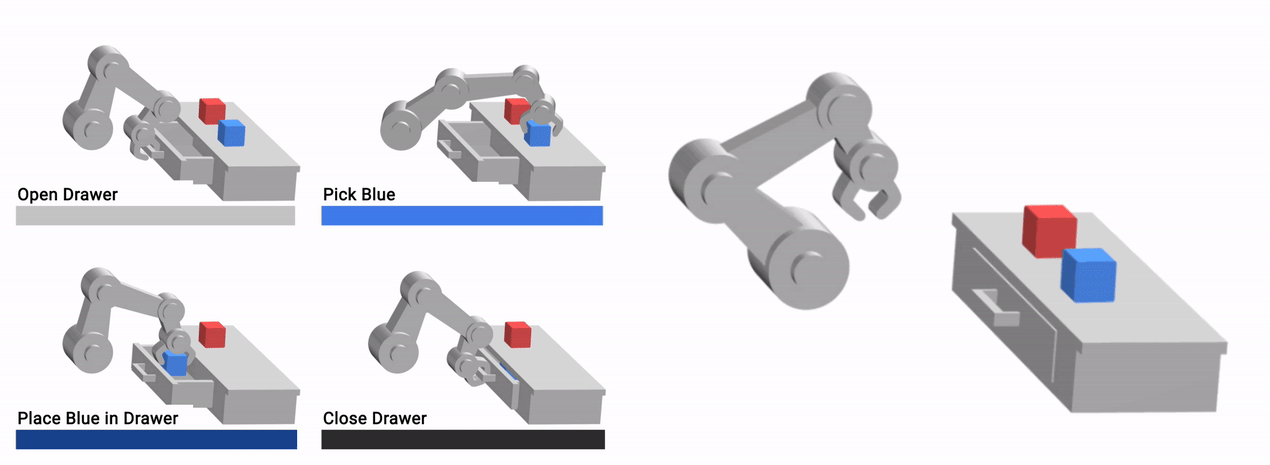
 |
| Our method, VFS, can compose low-level primitives (left) to learn complex long-horizon behaviors (right). |
Building a Value Function Space
The key insight motivating this work is that the abstract representation of actions and states is readily available from trained policies via their value functions. The notion of “value” in RL is intrinsically linked to affordances, in that the value of a state for skill reflects the probability of receiving a reward for successfully executing the skill. For any skill, its value function captures two key properties: 1) the preconditions and affordances of the scene, i.e., where and when the skill can be used, and 2) the outcome, which indicates whether the skill executed successfully when it was used.
Given a decision process with a finite set of k skills trained with sparse outcome rewards and their corresponding value functions, we construct an embedding space by stacking these skill value functions. This gives us an abstract representation that maps a state to a k-dimensional representation that we call the Value Function Space, or VFS for short. This representation captures functional information about the exhaustive set of interactions that the agent can have with the environment, and is thus a suitable state abstraction for downstream tasks.
Consider a toy example of the tabletop rearrangement setup discussed earlier, with the task of placing the blue object in the drawer. There are eight elementary actions in this environment. The bar plot on the right shows the values of each skill at any given time, and the graph at the bottom shows the evolution of these values over the course of the task.
 |
| Value functions corresponding to each skill (top-right; aggregated in bottom) capture functional information about the scene (top-left) and aid decision-making. |
At the beginning, the values corresponding to the “Place on Counter” skill are high since the objects are already on the counter; likewise, the values corresponding to “Close Drawer” are high. Through the trajectory, when the robot picks up the blue cube, the corresponding skill value peaks. Similarly, the values corresponding to placing the objects in the drawer increase when the drawer is open and peak when the blue cube is placed inside it. All the functional information required to affect each transition and predict its outcome (success or failure) is captured by the VFS representation, and in principle, allows a high-level agent to reason over all the skills and chain them together — resulting in an effective representation of the observations.
Additionally, since VFS learns a skill-centric representation of the scene, it is robust to exogenous factors of variation, such as background distractors and appearances of task-irrelevant components of the scene. All configurations shown below are functionally equivalent — an open drawer with the blue cube in it, a red cube on the countertop, and an empty gripper — and can be interacted with identically, despite apparent differences.
 |
| The learned VFS representation can ignore task-irrelevant factors such as arm pose, distractor objects (green cube) and background appearance (brown desk). |
Robotic Manipulation with VFS
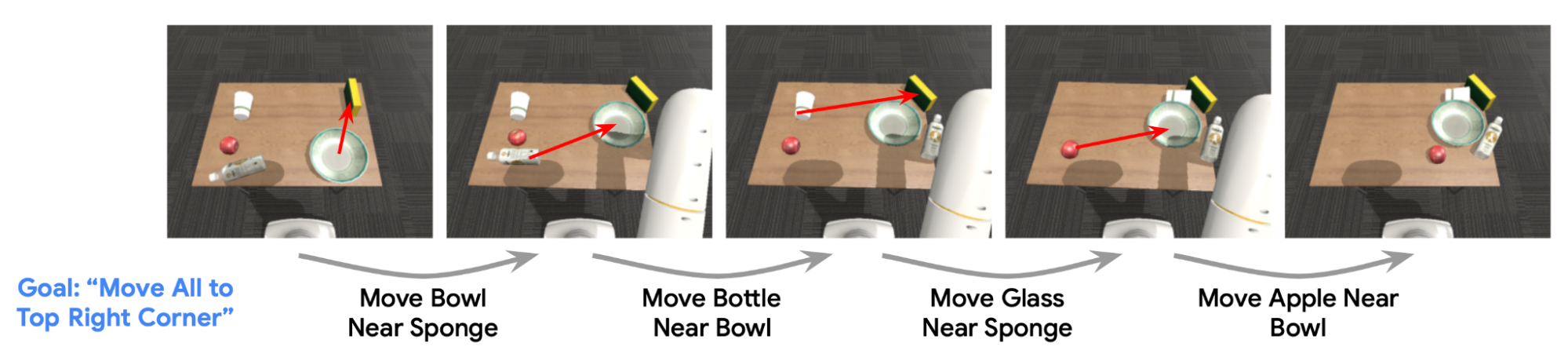
This approach enables VFS to plan out complex robotic manipulation tasks. Take, for example, a simple model-based reinforcement learning (MBRL) algorithm that uses a simple one-step predictive model of the transition dynamics in value function space and randomly samples candidate skill sequences to select and execute the best one in a manner similar to the model-predictive control. Given a set of primitive pushing skills of the form “move Object A near Object B” and a high-level rearrangement task, we find that VFS can use MBRL to reliably find skill sequences that solve the high-level task.
 |
| A rollout of VFS performing a tabletop rearrangement task using a robotic arm. VFS can reason over a sequence of low-level primitives to achieve the desired goal configuration. |
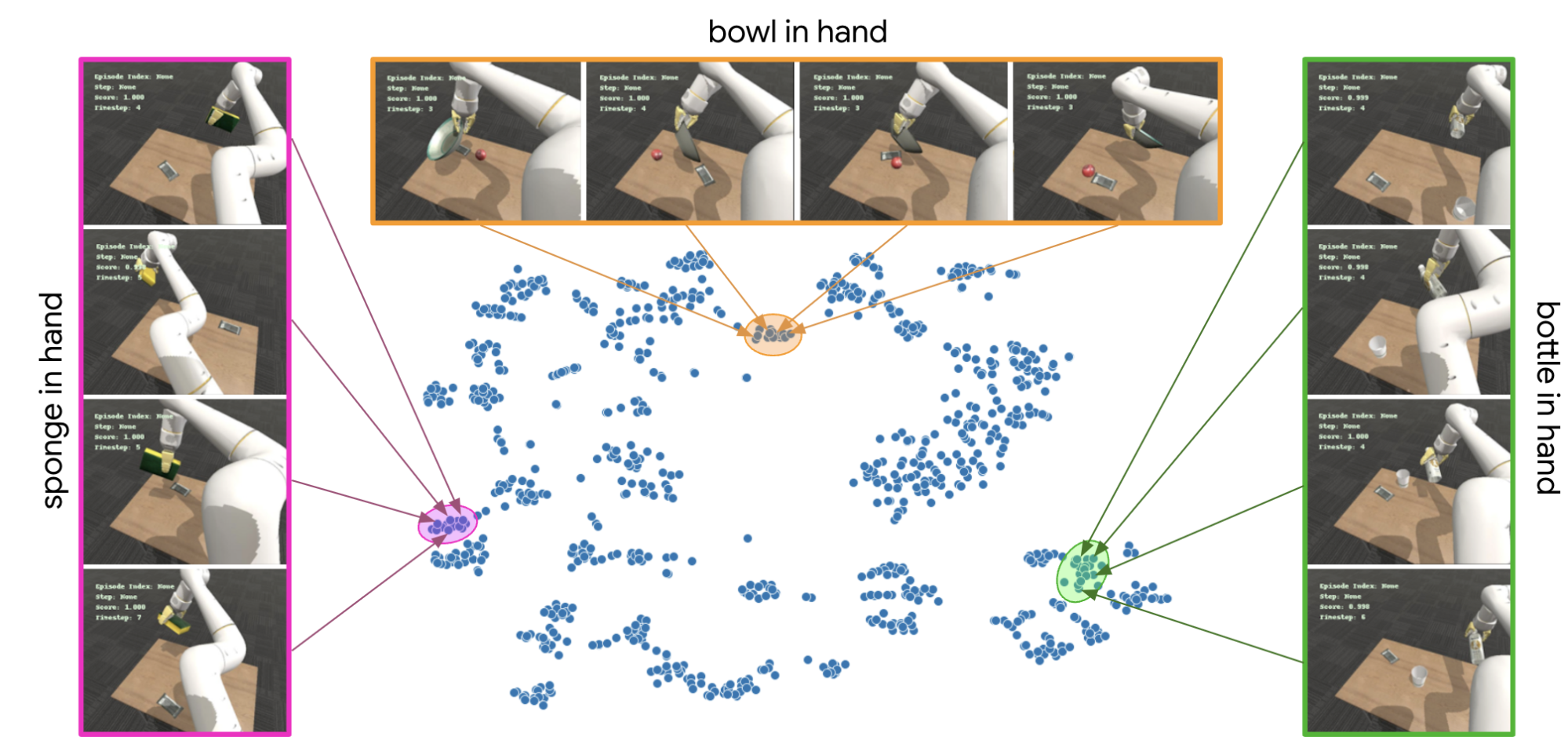
To better understand the attributes of the environment captured by VFS, we sample the VFS-encoded observations from a large number of independent trajectories in the robotic manipulation task and project them onto a two-dimensional axis using the t-SNE technique, which is useful for visualizing clusters in high-dimensional data. These t-SNE embeddings reveal interesting patterns identified and modeled by VFS. Looking at some of these clusters closely, we find that VFS can successfully capture information about the contents (objects) in the scene and affordances (e.g., a sponge can be manipulated when held by the robot’s gripper), while ignoring distractors like the relative positions of the objects on the table and the pose of the robotic arm. While these factors are certainly important to solve the task, the low-level primitives available to the robot abstract them away and hence, make them functionally irrelevant to the high-level controller.
 |
| Visualizing the 2D t-SNE projections of VFS embeddings show emergent clustering of equivalent configurations of the environment while ignoring task-irrelevant factors like arm pose. |
Conclusions and Connections to Future Work
Value function spaces are representations built on value functions of underlying skills, enabling long-horizon reasoning and planning over skills. VFS is a compact representation that captures the affordances of the scene and task-relevant information while robustly ignoring distractors. Empirical experiments reveal that such a representation improves planning for model-based and model-free methods and enables zero-shot generalization. Going forward, this representation has the promise to continue improving along with the field of multitask reinforcement learning. The interpretability of VFS further enables integration into fields such as safe planning and grounding language models.
Acknowledgements
We thank our co-authors Sergey Levine, Ted Xiao, Alex Toshev, Peng Xu and Yao Lu for their contributions to the paper and feedback on this blog post. We also thank Tom Small for creating the informative visualizations used in this blog post.
-
Labels:
- Conferences & Events
- Robotics
Quick links
Other posts of interest
-

December 12, 2025
Spotlight on innovation: Google-sponsored Data Science for Health Ideathon across Africa- Conferences & Events ·
- Generative AI ·
- Global ·
- Health & Bioscience
-

May 30, 2024
CodecLM: Aligning language models with tailored synthetic data- Conferences & Events ·
- Machine Intelligence ·
- Natural Language Processing
-
May 24, 2024
Google Research at Google I/O 2024- Conferences & Events ·
- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence ·
- Product ·
- Quantum ·
- Responsible AI