
SOAR: New algorithms for even faster vector search with ScaNN
April 10, 2024
Philip Sun and Ruiqi Guo, Software Engineers, Google Research
Quick links
Efficient vector similarity search is critical for many machine learning (ML) applications at Google. It’s commonly used to search over embeddings, which are vector representations of real-world entities, such as images, websites, or other media. These vector representations allow computers to mathematically compare and find similarities between objects, for example grouping together portraits of the same subject. Once the dataset of embeddings becomes too large for the brute-force approach of comparing the query to every embedding in the dataset, more efficient vector similarity search methods become necessary for further scaling.
The desire to highlight Google’s innovations in vector search algorithms are what led to the open-sourcing of the ScaNN vector search library in 2020 (more in this prior Research Blog post). Since then, larger datasets and the popularization of vector search in novel use cases (such as retrieval-augmented generation) have both driven demand for more scalable vector search algorithms.
ScaNN has been actively maintained and improved since its release, but today we are particularly excited to announce a major algorithmic advancement to ScaNN: Spilling with Orthogonality-Amplified Residuals (SOAR). In “SOAR: Improved Indexing for Approximate Nearest Neighbor Search,” presented at NeurIPS 2023, we describe how introducing some redundancy to ScaNN’s vector index leads to improved vector search efficiency, all while minimally impacting index size and other key vector index metrics. SOAR helps ScaNN step up to meet the ever-growing scaling and performance demands placed upon vector search libraries.
Originally featured in the 2020 ScaNN open-source release blog post, the above illustration shows how vector search over embeddings can help answer natural-language queries over a hypothetical literary database. Today we are showcasing research that allows ScaNN to perform vector search even faster.
SOAR and redundancy
The key intuition to SOAR is to introduce some mathematically crafted and implementation-optimized redundancy to ScaNN’s approximate vector search routine. Redundancy is the concept of using multiple replicas, which can each function as backup when another replica fails, to decrease the chance of total failure of a given system. Redundancy is used in many engineering disciplines, from having multiple systems that can adjust wing flaps to ensure an airplane’s stability, to storing copies of data across multiple physical drives to protect against data loss. On the other hand, redundancy may provide a false sense of security when its replicas are vulnerable to common, correlated failures — for example, storing multiple copies of data in the same datacenter still exposes them to the common threat of natural disaster in the area, and is therefore less robust than geographically distributed replicas of that data.
One common example of redundancy is replicating data across multiple datacenters around the world to decrease the chance of data loss. SOAR uses redundancy to decrease the risk of failing to find a nearest-neighbor vector.
In the context of approximate vector search, “failure” means failing to find the true nearest neighbors for a query, and instead retrieving less similar vectors. In accordance with the above themes, SOAR’s redundancy makes it less likely for ScaNN to miss the nearest neighbors, and SOAR’s specific mathematical formulation, discussed below, minimizes correlated failures that would otherwise harm search efficiency. As a result, SOAR improves the search accuracy achievable at a fixed search cost, or equivalently decreases search cost needed to achieve the same search accuracy.
SOAR: Mathematical details
We first describe ScaNN’s approximate search paradigm without SOAR in order to highlight SOAR’s differences. We focus on how ScaNN solves the maximum inner product search (MIPS) variant of vector similarity search, which defines vector similarity as the query’s inner product with a database vector. This is both because SOAR targets MIPS and because MIPS is adaptable to a variety of other similarities, including cosine and Euclidean distance.
Before ScaNN can answer vector search queries, it first goes through an indexing phase, where the input dataset is pre-processed to construct data structures that facilitate efficient vector search. A crucial part of this indexing step is clustering via k-means; before SOAR, the clustering was performed such that each vector in the dataset was assigned to exactly one k-means cluster. Each cluster has a cluster center, which acts as a coarse approximation for the vectors assigned to the cluster; the vectors in a cluster are only evaluated if their cluster center is among the N closest centers to the query vector (with N a parameter; higher N gives greater search accuracy at the expense of greater computational cost).
An animation demonstrating how clustering was performed prior to SOAR to perform efficient vector search in ScaNN.
To illustrate when such an algorithm has difficulty finding the nearest neighbors, consider a vector x assigned to a cluster with center c. Denote the difference between x and c as the residual, or r. For a query q, the difference between the query-vector similarity ⟨q, x⟩ and the estimated similarity ⟨q, c⟩ is ⟨q, x⟩ - ⟨q, c⟩ = ⟨q, x - c⟩ = ⟨q, r⟩, which is maximized when r is parallel to q, as illustrated below:
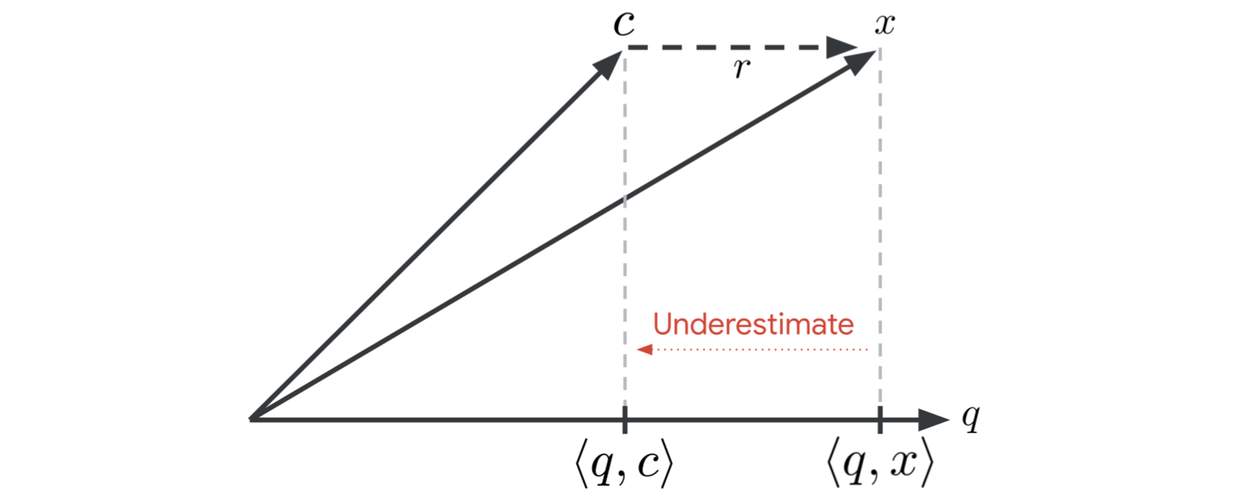
When the query q is parallel to r, the estimated inner product ⟨q, c⟩ greatly underestimates the true inner product ⟨q, x⟩. SOAR helps find the nearest neighbors in these cases, which otherwise tend to diminish vector search accuracy.
In such situations, if x is a nearest neighbor to q, x is typically hard to find, because even though ⟨q, x⟩ is high, ⟨q, r⟩ is also high, resulting in the query-center similarity ⟨q, c⟩ being low, so this particular cluster is likely to be pruned and not searched further. There are a number of ways to mitigate this problem. For example, computing a higher-quality clustering tends to decrease the magnitude of r, which lowers the average estimation error, while anisotropic vector quantization (AVQ) “shapes” the error such that it tends to be largest when the query is dissimilar to x, and therefore less likely to impact results.
SOAR addresses this issue by taking a completely different approach: allowing vectors to be assigned to more than one cluster. Intuitively, this is effective by the principle of redundancy: secondary assignments may act as “backup clusters” that facilitate efficient, accurate vector search when the primary assignment performs poorly (when q is highly parallel with r of the primary assignment).
This redundancy arises from the fact that the second assignment provides a new vector-center difference r’. As long as this r’ isn’t near-parallel with q when r is near-parallel with q, this secondary center should help ScaNN locate the nearest neighbors to q. However, SOAR goes a step further than this naïve redundancy, and modifies the assignment loss function for secondary assignments to explicitly optimize for independent, effective redundancy: it aims to find secondary clusters whose r’ are perpendicular to r, so that when q is near-parallel to r and the primary center has high error, q will be near-orthogonal to r’ and the secondary center will have low error. The effect of SOAR’s modified loss is visualized below:
SOAR not only introduces redundancy via secondary assignments, but does so via a modified loss to maximize the effectiveness of redundancy. Unmodified loss (shown first) often leads to ineffective secondary assignments like c’ with high error. SOAR’s modified loss (later) selects c’’, a much better choice.
There are additional details to SOAR’s implementation and theoretical analysis, but the core idea behind SOAR is as simple as described above: assign vectors to multiple clusters with a modified loss. This technique is named SOAR because prior research has described multiple-assignment as “spilling,” and the modified loss encourages orthogonal (perpendicular) residuals, leading to the name Spilling with Orthogonality-Amplified Residuals.
Experimental results
SOAR enables ScaNN to maintain its existing advantages, including low memory consumption, fast indexing speed, and hardware-friendly memory access patterns, while endowing ScaNN with an additional algorithmic edge. As a result, ScaNN makes the best tradeoff among the three major metrics for vector search performance, as highlighted below for the ann-benchmarks glove-100 dataset. The only libraries to come near ScaNN’s querying speed require over 10× the memory and 50× the indexing time. Meanwhile, ScaNN achieves querying throughputs several times higher than libraries of comparable indexing time.
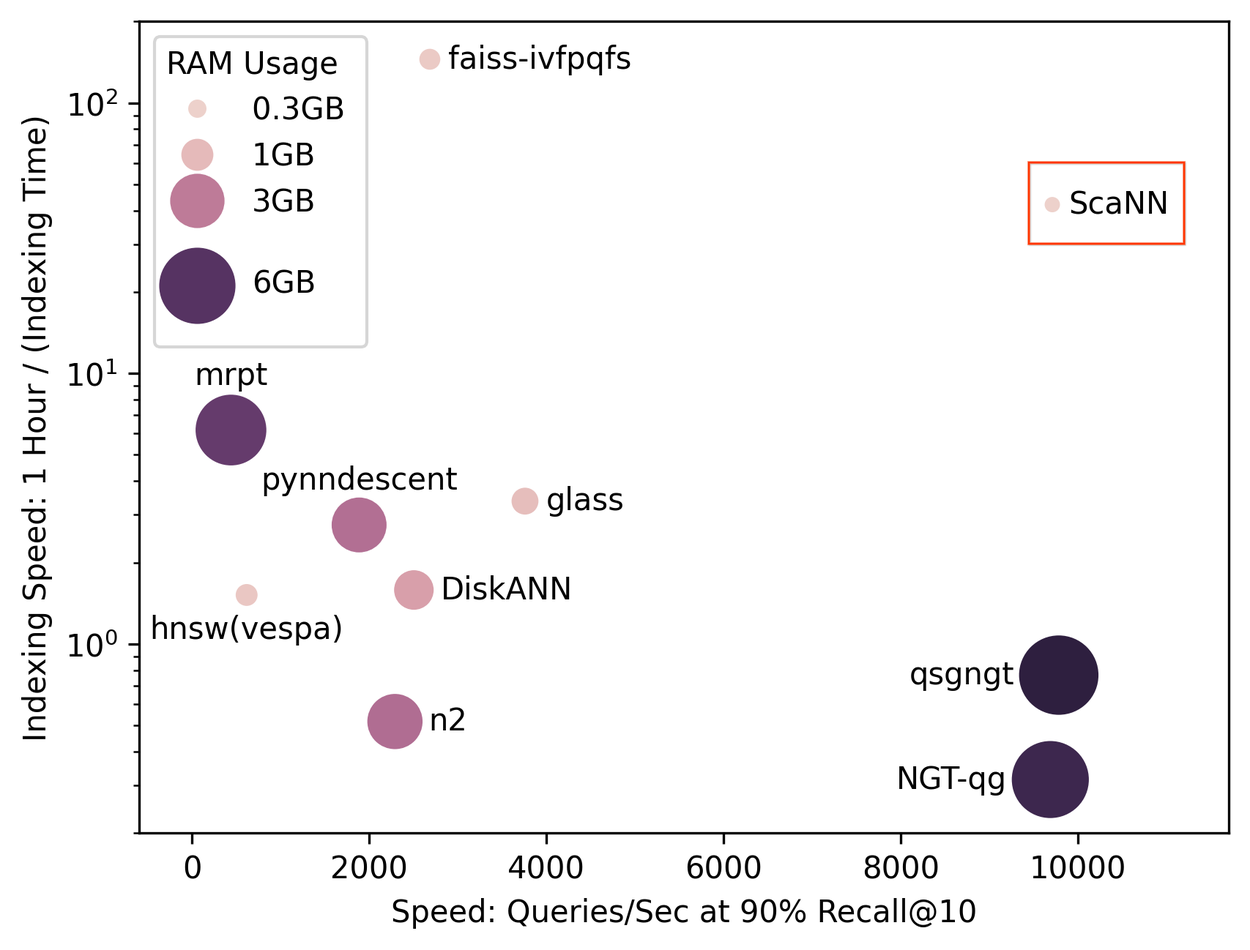
ScaNN with SOAR makes by far the best query speed / indexing speed trade-off among all libraries benchmarked, all while having the smallest memory footprint.
ScaNN also achieves state-of-the-art performance in the two tracks of Big-ANN 2023 benchmarks to which it’s applicable. These benchmarks involve larger datasets, which, in fact, further increase SOAR’s efficacy. The effect of dataset size on SOAR, as well as benchmarks on up to billion-vector datasets, are all discussed further in the paper.
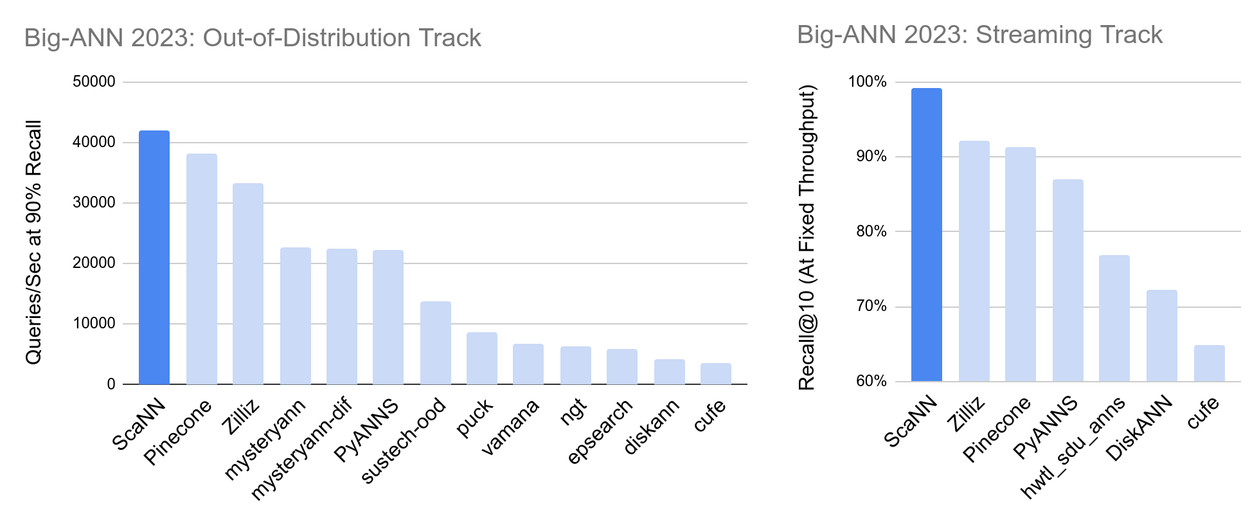
For both the out-of-distribution and streaming tracks of Big-ANN 2023, SOAR allows ScaNN to achieve the highest result in each track’s respective ranking metric. The website’s leaderboard is pending update here.
Conclusion
SOAR provides ScaNN a robust “backup” route to identify nearest neighbors when ScaNN’s traditional clustering-based approach has the most difficulty. This allows ScaNN to perform even faster vector search, all while maintaining low index size and indexing time, leading to the all-around best set of tradeoffs among vector search algorithms.
We invite the community to use ScaNN to solve its vector search challenges. ScaNN is open-sourced on GitHub and can be easily installed via Pip. In addition, ScaNN vector search technology is available in Google Cloud products: Vertex AI Vector Search leverages ScaNN to offer a fully managed, high-scale, low-latency, vector similarity matching service, and AlloyDB recently launched ScaNN for AlloyDB index — a vector database on top of the popular PostgreSQL-compatible database. We are excited to see how more efficient vector search enables the next generation of machine learning applications.
Acknowledgements
This post reflects the work of the entire ScaNN team: David Simcha, Felix Chern, Philip Sun, Ruiqi Guo, Sanjiv Kumar and Zonglin Li. We’d also like to thank Apurv Suman, Dave Dopson, John Guilyard, Rasto Lenhardt, Susie Flynn, and Yannis Papakonstantinou.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 7, 2026
The power of collaboration: How we can reduce traffic congestion- Algorithms & Theory ·
- Climate & Sustainability ·
- Data Mining & Modeling
-

June 25, 2026
Optimizing cloud economics with linear elastic caching- Algorithms & Theory ·
- Data Management
ScaNN with SOAR makes by far the best query speed / indexing speed trade-off among all libraries benchmarked, all while having the smallest memory footprint.

When the query q is parallel to r, the estimated inner product ⟨q, c⟩ greatly underestimates the true inner product ⟨q, x⟩. SOAR helps find the nearest neighbors in these cases, which otherwise tend to diminish vector search accuracy.

For both the out-of-distribution and streaming tracks of Big-ANN 2023, SOAR allows ScaNN to achieve the highest result in each track’s respective ranking metric. The website’s leaderboard is pending update here.

One common example of redundancy is replicating data across multiple datacenters around the world to decrease the chance of data loss. SOAR uses redundancy to decrease the risk of failing to find a nearest-neighbor vector.