Google Research at Google I/O 2024
May 24, 2024
Yossi Matias, VP, Head of Google Research, and James Manyika, SVP, Research, Technology & Society
Each year at Google I/O, we share some of Google’s most cutting-edge technologies, and show how developers and other communities can use them to innovate and make progress in their own domains. It’s worth noting how many of these new technologies emerged from years of work within Google Research, many in collaboration with other teams, building on multiple successive breakthroughs in AI and other areas of computer science. Without deep research driving innovation within Google and beyond, we wouldn’t have these incredible new experiences. In addition to Google Research’s contributions on the Gemini program, here are some of our favorites this year, tapping into years-long efforts from Google Research.
Ask Photos
Last week at Google I/O 2024, we previewed Ask Photos, an experimental new feature that takes Google Photos to the next level with the help of multiple Gemini models working together to deliver helpful responses. Soon, instead of searching by typing keywords and then scrolling through thousands of results, users will be able to just ask for something — whether that's a specific memory or a specific piece of information within a photo — and Ask Photos will find it. Not only is this a helpful addition to Google Photos, it's also a powerful example of how Gemini models can act as agents via function calling and memory capabilities.
First, the query is passed to an agent model that uses Gemini to determine the best retrieval augmented generation (RAG) tool for the task. Typically, the agent model begins by understanding the user’s intent and formulates a search through their photos using an updated vector-based retrieval system, which extends the already powerful metadata search built into Photos. The vector-based retrieval allows understanding of natural language concepts (like "a person smiling while riding a bike") far better than traditional keyword search.
The search returns relevant photos, which are then analyzed by an answer model that leverages Gemini’s long context window and multimodal capabilities. This model considers visual content, text, and metadata, like dates and locations, to identify the most relevant information. Finally, the answer model crafts a helpful response grounded in the photos and videos it has studied.
If a user corrects Ask Photos, they can instruct it to remember the updated information for future conversations, making it more helpful over time and avoiding the need to repeat instructions. Users can view and manage remembered details at any time.
Ask Photos is an experimental optional feature that we're starting to roll out soon, with more capabilities to come. Check out the Ask Photos announcement for additional details about the feature, how we’re protecting user privacy and ensuring safety, and more.
StyleDrop: Infinite Wonderland
StyleDrop is a technology that transforms a generalist text-to-image generation model into a specialist model tailored to generate images in specific visual style based on reference images provided by the user. StyleDrop allows a significantly higher level of stylized text-to-image generation by fine-tuning, while circumventing the burden of text prompt engineering.
In a collaboration between several artists, Google Research, Google DeepMind, and Creative Lab, we conducted an experiment to explore the potential of visual storytelling with this generative AI imagery technology. In this project, named “Infinite Wonderland”, we worked with artists to re-imagine visual illustrations of Lewis Carroll’s classic Alice’s Adventures in Wonderland. Originally illustrated by Sir John Tenniel, for this experiment we used StyleDrop to generate new illustrations in various styles, directed by four modern artists, Shawna X, Eric Hu, Erik Carter and Haruko Hayakawa. You can read more about how StyleDrop was used in Infinite Wonderland here.
Consistency in visual styles and presentation of characters are two important aspects for coherent and engaging visual storytelling. To achieve this, each artist created artworks representing a few main characters in their own visual styles. By fine-tuning our generative image model, Imagen 2, on images provided by each artist, StyleDrop models brought the story of Alice’s Adventures in Wonderland to life.

Images in the first row are original illustrations by Sir John Tenniel. The first image in the second row is the style image provided by each artist. Those following are the reimagined images created by StyleDrop (second to fifth columns).
LearnLM
We introduced LearnLM, our new family of models that are based on Gemini and fine-tuned for learning. Grounded in educational research and tailored to how people learn, LearnLM represents an effort across Google Research, Google DeepMind, and our product teams to help make learning experiences more engaging, personal and useful.
One of the experiences powered by LearnLM is QuizMe, an evaluative practice flow with Gemini that can walk users through a structured quiz about any topic. QuizMe guides users through the learning process by combining multiple capabilities of large language models (LLMs), including question generation, hints, answer assessment, feedback, summarization, and managing the structured multi-turn conversational flow. With these capabilities baked in, QuizMe is designed to help students build understanding rather than just to provide the answer.
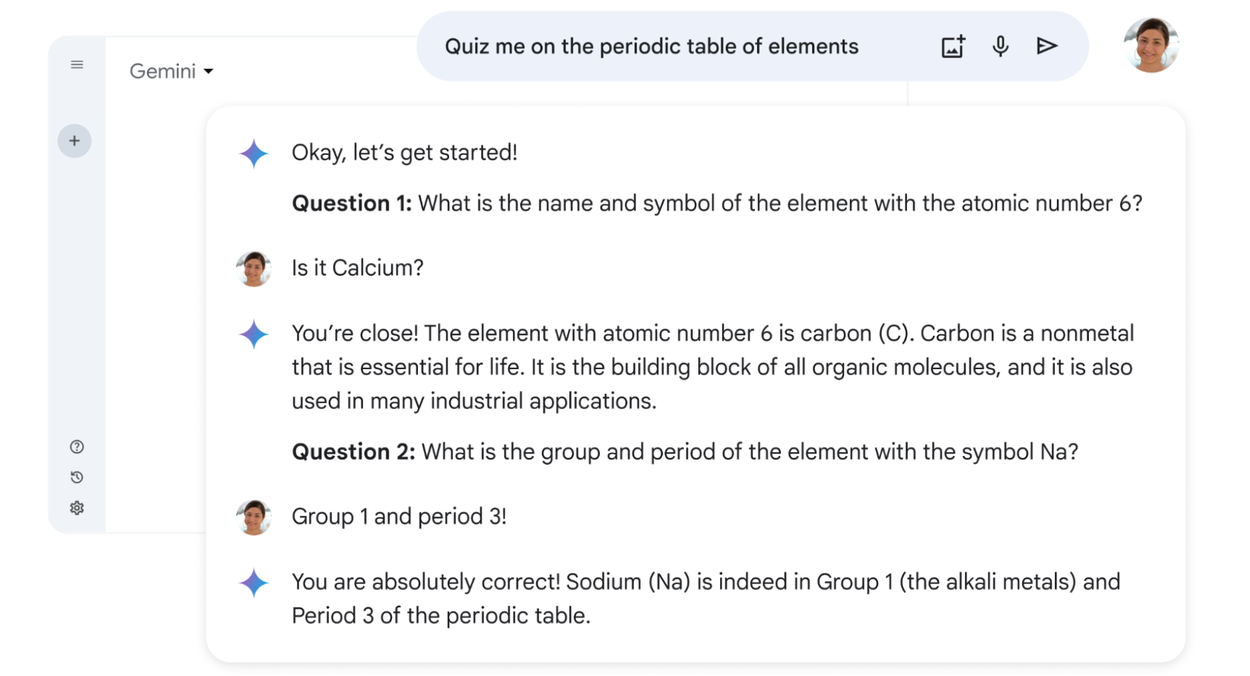
Accomplishing this required that we address several core challenges:
Proactivity and adaptivity: The goal was a system that could proactively guide users while adapting to their diverse responses and knowledge gaps. This required balancing a proactive model capable of guiding users with established UX practices for assessment tools.
Feedback accuracy: When users provide the incorrect answer to a practice question, the base model tends to avoid telling them that they are wrong, because LLMs are trained to mostly follow along with the user’s initiatives and claims. By using focused fine-tuning data, we were able to shift the model’s behavior in the evaluative practice scenario to better identify incorrect answers and effectively guide users in their learning experience.
Evaluation: Ensuring the quality of the overall experience is critical and is a challenge on its own. We addressed this by using a combination of automated metrics and human evaluations across a variety of aspects involved to assess the quality of the questions asked, the feedback provided, and the overall pedagogical quality.
You can read more about LearnLM here, and about more Google Learning features on Gemini here.
Med-Gemini
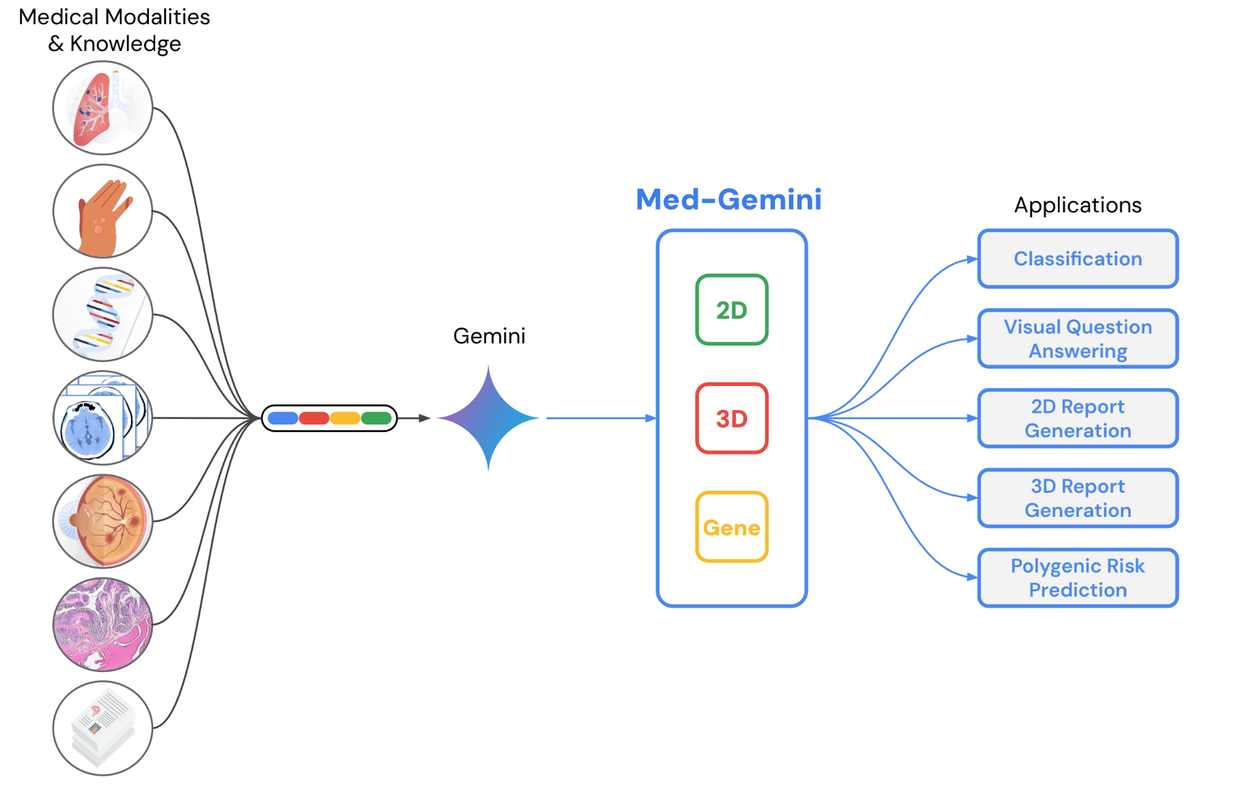
As part of our journey to pursue the potential of Generative AI for Health, we’re researching how fine-tuning Gemini can unlock transformative capabilities in medicine. Med-Gemini, is our family of research models fine-tuned for the medical domain. It inherits Gemini’s native reasoning, multimodal, and long-context abilities, achieving state-of-the-art performance on a variety of benchmarks. This includes achieving 91.1% accuracy on the popular MedQA benchmark, an industry best that surpasses our prior best set by Med-PaLM 2. Med-Gemini also showed state-of-the-art performance on a range of multimodal and long-context benchmarks.
Beyond accurately answering medical questions, Med-Gemini also demonstrated novel capabilities in generating radiology reports. We show how a multimodal model can accurately interpret complex 3D brain CT scans. We also demonstrated a new mechanism to predict health outcomes from genomic data converted to polygenic risk scores. Further research is needed before real world application is considered, and we’re excited by our research with Med-Gemini which shows the potential of Gemini to eventually assist in clinician, researcher, and patient workflows.
You can learn more about Med-Gemini here and in two recent papers, “Capabilities of Gemini Models in Medicine” and “Advancing Multimodal Medical Capabilities of Gemini”.
Illuminate
Illuminate is an experimental product in which we explore ways to transform academic papers into audio dialogue that discuss the key points in a friendly and accessible, yet accurate exchange. The system combines our latest AI technologies to understand complex and long content and adapt it to our individual learning needs and preferences, while grounding it in the input.
Here’s how it works. A user starts by either (a) searching for research papers of interest or (b) providing links to one or multiple research papers. The model leverages Gemini 1.5 Pro, taking advantage of its long context and multimodal capabilities to perform a deep read of the paper(s). It then generates a dialogue script, which provides an overview of the paper(s) and discusses key insights, and uses AudioLM to render the dialogue into a two-person voice conversation. The resulting audio uses our watermarking technology, SynthID, to make it easier to identify that the content is AI-generated.
Visit labs.google/illuminate to check out a library of available audio conversations and join the waitlist to generate your own.
Google Quantum AI
We’re excited about what quantum computing means for the future of Google and the world. Our quantum computers are state-of-the-art, and we’re making steady progress on our roadmap to build a large-scale quantum computer that will enable us to solve problems that are otherwise unsolvable.

Our on-stage talk at I/O, Quantum computing: Facts, fiction and the future, explains what quantum computing is, delves into some common misconceptions, and outlines useful, societally beneficial applications we expect to see in the future — better drug discovery, better batteries to power electric cars, and new solutions for practical fusion energy.
In-person attendees had the unique opportunity to program a quantum computer with our AI sandbox quantum computing lab demo. They were able to explore how these systems are built and programmed end-to-end, from fabrication of individual qubit chips, to integration into our advanced quantum computing architecture. Experience it for yourself at https://quantumai.google/learn/lab!
Veo
Generative AI played a prominent role across announcements at I/O this year. One such announcement was Veo, Google’s latest video generation model to date, which is able to generate high-resolution videos across a range of cinematic styles with lengths longer than a minute. Announced by Google DeepMind, this project was built on a foundation of work with close ties to Google Research. In much the same way that Gemini evolved out of earlier advances like PaLM 2, Bard and others, Veo leverages training data, innovations in scaled modeling infrastructure, and advances in parallel model architecture, from video generation modeling efforts that came before it.
The data used by Veo for training was curated and annotated with the latest models and carefully evaluated to be responsible and safe. Google Research teams have accumulated years of experience on curating data for ML training, and are driving a cross-Google effort to curate a large-scale, high-quality responsible dataset in order to generate videos. This data effort helps enable Veo to perform well across a variety of tasks.
Multiple Google Research teams worked together with Google DeepMind to develop modeling infrastructure to better scale model training, necessary for Veo’s large model size. Veo also benefited from the modeling work and architecture exploration from LLM-based models, like MAGVIT, Phenaki and VideoPoet, and diffusion techniques from Lumiere, and WALT. Those efforts explored parallel model architectures, some of which Veo has adapted and refined for its debut. This included using the MAGVIT tokenizer and exploring architectures for a dIffusion transformer from WALT. These efforts from Google Research helped expand the video generation space and continue to pave the way for the next generations of model architectures and model recipes.
People-centered AI: Creating responsible generative AI products
At I/O, we presented our product principles that cover end-to-end safety and practical guidance to help user experience, product, engineering, and AI teams to build responsible generative AI products.
While unlocking various new capabilities for people, generative AI has also introduced new challenges for which we must ensure that we provide safe and responsible product experiences. This has created opportunities to more tightly integrate the model development process with user experience design. To ensure a successful product experience, it's critical to build and fine-tune models while simultaneously designing experiences that aim to reduce the impact of potential risks. To do this successfully, we follow five actionable best practices that help teams working on Generative AI experiences lead with a user-centered and responsible mindset. These are:
- Designing for user autonomy by providing controls and affordances to empower users. One simple example is the customization of AI agents. Users could tailor the AI's tone and output style to align with their preferences, and even define the conditions under which the agent is authorized to act on their behalf.
- Aligning AI with real user needs through understanding cultural contexts and tailoring AI accordingly. By engaging with users during the model design process, developers can surface prototypical data that reflect the needs and tasks of real people. This data can be used to inform the product experience: interactions, affordances, and even safety policies.
- Preparing for safety by treating it as an ongoing and evolving endeavor.
- Adapting AI to user feedback after deployment by utilizing meaningful user signals to refine the system.
- Creating helpful AI experiences by integrating AI technologies into thoughtful interaction paradigms. It should be simple and low effort for people to craft inputs. Rather than relying solely on a text box, it may be better to support other input methods, such as uploading an image, since not all people find it easy to express themselves in written language. And by creating these affordances, we leverage the full potential of generative AI’s natural language and multi-modal capabilities.
By focusing on AI with people in mind, the recently updated People + AI Guidebook explores data, design, and AI development best practices that span the full product lifecycle.

Through product examples, we identify affordances, strategies, and interventions that optimize AI's impact. Ultimately, our goal is to ensure that AI remains useful and helpful to people.
Other posts of interest
-

July 30, 2026
Science One Framework: A verifiable autonomous research framework via Chain-of-Evidence- General Science ·
- Machine Intelligence ·
- Natural Language Processing
-

July 22, 2026
SymptomAI: Towards a conversational AI agent for everyday symptom assessment- General Science ·
- Health & Bioscience ·
- Natural Language Processing ·
- Responsible AI
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum



Images in the first row are original illustrations by Sir John Tenniel. The first image in the second row is the style image provided by each artist. Those following are the reimagined images created by StyleDrop (second to fifth columns).
