Perception
We design systems that enable computers to "understand" the world, via a range of modalities including audio, image, and video understanding.

We design systems that enable computers to "understand" the world, via a range of modalities including audio, image, and video understanding.
About the team
The Perception team is a group focused on building systems that can interpret sensory data such as image, sound, video, and more. Our research helps power many products across Google; image and video understanding in Search and Google Photos, computational photography for Pixel phones and Google Maps, machine learning APIs for Google Cloud and Youtube, accessibility technologies like Live Transcribe, applications in Nest Hub Max, mobile augmented reality experiences in Duo video calls and more.
We actively contribute to open source and research communities, providing media processing technologies (e.g. Mediapipe) to enable the building of computer vision applications with TensorFlow. Further, we have released several large-scale datasets for machine learning, including AudioSet, AVA, Open Images, and YouTube-8M.
In doing all this, we adhere to AI principles to ensure that these technologies work well for everyone. We value innovation, collaboration, respect, and building an inclusive and diverse team and research community, and we work closely with the PAIR team to build ML Fairness frameworks.
Featured publications
Highlighted projects
-
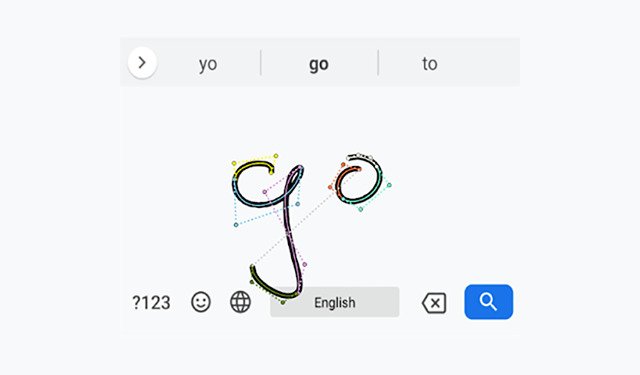 Handwriting Input in GBoardHandwriting recognition in GBoard allows users to input text through freeform strokes, which is particularly helpful for stylus users and languages with more characters than can easily fit on a keyboard.
Handwriting Input in GBoardHandwriting recognition in GBoard allows users to input text through freeform strokes, which is particularly helpful for stylus users and languages with more characters than can easily fit on a keyboard. -
 Optical Character Recognition: Scan All The Books!OCR enables the Google Books project to digitize the world's books and make them searchable.
Optical Character Recognition: Scan All The Books!OCR enables the Google Books project to digitize the world's books and make them searchable. -
 Learning the Depths of Moving PeopleApplying a deep learning-based approach, we can generate depth maps from an ordinary video, where both the camera and subjects are freely moving, which can be used to produce a range of 3D-aware video effects, such synthetic defocus, inserting synthetic CG objects into the scene, or filling in holes and disoccluded regions with the content exposed in other frames of the video.
Learning the Depths of Moving PeopleApplying a deep learning-based approach, we can generate depth maps from an ordinary video, where both the camera and subjects are freely moving, which can be used to produce a range of 3D-aware video effects, such synthetic defocus, inserting synthetic CG objects into the scene, or filling in holes and disoccluded regions with the content exposed in other frames of the video. -
 MediaPipe: Open Source cross platform multimodal applied machine learning pipelinesMediaPipe is an open source framework for building cross platform multimodal (eg. video, audio, any time series data) applied ML pipelines that consist of fast machine learning inference, classic computer vision, and media processing. MediaPipe was open sourced at CVPR in June 2019 as v0.5.0. Since our first open source version, we have released various ML pipeline examples like Object Detection and Tracking, Face Detection, Multi-hand Tracking, Hair Segmentation.
MediaPipe: Open Source cross platform multimodal applied machine learning pipelinesMediaPipe is an open source framework for building cross platform multimodal (eg. video, audio, any time series data) applied ML pipelines that consist of fast machine learning inference, classic computer vision, and media processing. MediaPipe was open sourced at CVPR in June 2019 as v0.5.0. Since our first open source version, we have released various ML pipeline examples like Object Detection and Tracking, Face Detection, Multi-hand Tracking, Hair Segmentation. -
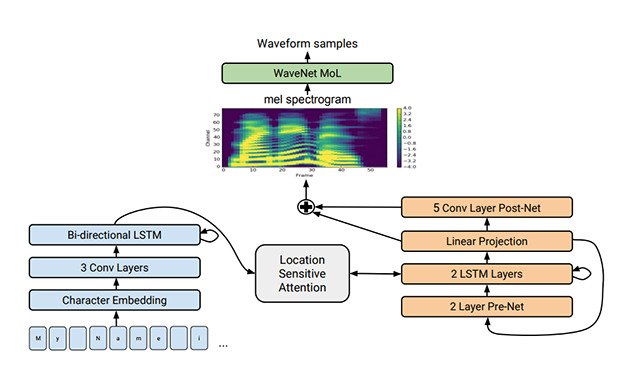 Tacotron 2: Generating Human-like Speech from TextTacotron 2 generates human-like speech from text using neural networks trained using only speech examples and corresponding text transcripts.
Tacotron 2: Generating Human-like Speech from TextTacotron 2 generates human-like speech from text using neural networks trained using only speech examples and corresponding text transcripts. -
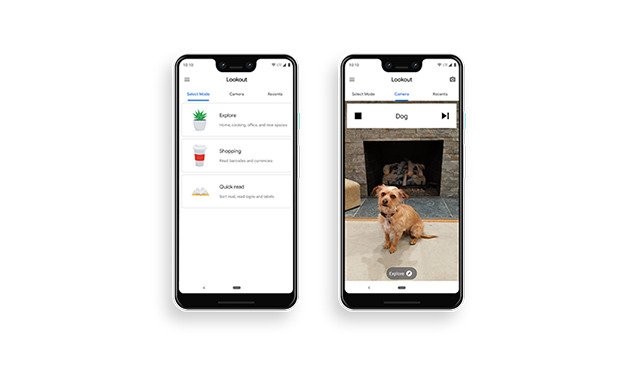 Lookout: Discover your surroundings with the help of AILookout helps those who are blind or have low vision identify information about their surroundings as they move through a space by recognizing the people, text, and objects.
Lookout: Discover your surroundings with the help of AILookout helps those who are blind or have low vision identify information about their surroundings as they move through a space by recognizing the people, text, and objects. -
 Night: Seeing in the dark with Pixel CameraNight Sight uses computational photography on Pixel to capture vibrant and detailed low-light images, and, with a tripod, it can even enable astrophotography.
Night: Seeing in the dark with Pixel CameraNight Sight uses computational photography on Pixel to capture vibrant and detailed low-light images, and, with a tripod, it can even enable astrophotography. -
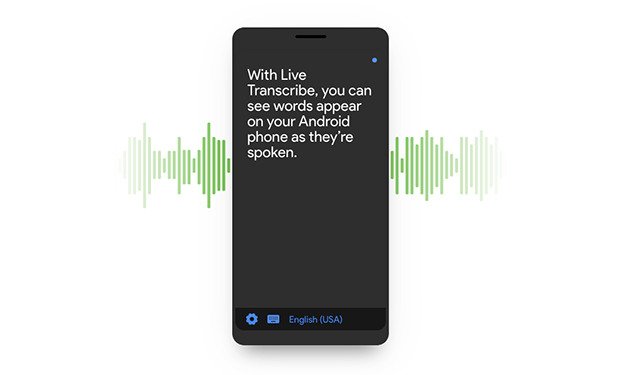 Live Transcribe: Realtime captions for the deaf and hard of hearingLive Transcribe provides free realtime captions in 75+ languages, and sound events detection, across 2 billion Android devices for the deaf and hard of hearing.
Live Transcribe: Realtime captions for the deaf and hard of hearingLive Transcribe provides free realtime captions in 75+ languages, and sound events detection, across 2 billion Android devices for the deaf and hard of hearing. -
 Nest Hub Max: Ambient computing with on-device face and gesture recognition in your homeNest Hub Max has Computer Vision powering face recognition, gesture recognition and auto-framing and zooming for Duo video calls.
Nest Hub Max: Ambient computing with on-device face and gesture recognition in your homeNest Hub Max has Computer Vision powering face recognition, gesture recognition and auto-framing and zooming for Duo video calls.
Some of our locations







Some of our people
-

Chris Bregler
- Machine Intelligence
- Machine Learning
- Audio Processing
-

William T. Freeman
- Human-Computer Interaction and Visualization
- Machine Perception
-

Richard F. Lyon
- Data Mining and Modeling
- Human-Computer Interaction and Visualization
- Machine Intelligence
-

Peyman Milanfar
- Machine Intelligence
- Machine Perception
-

Kevin P. Murphy
- Machine Intelligence
- Machine Learning
- Machine Perception
-

Apostol (Paul) Natsev
- Data Mining and Modeling
- Machine Perception
-

Peter Norvig
- Education Innovation
- Information Retrieval and the Web
- Data Mining and Modeling
-

Caroline Pantofaru
- Machine Perception
- Robotics
-

Ashok Popat
- Machine Perception
- Machine Translation
- Natural Language Processing
-

Rif A. Saurous
- Machine Intelligence
- Machine Perception
- Software Engineering
-

Cordelia Schmid
- Machine Intelligence
- Machine Perception
-

Rahul Sukthankar
- Algorithms and Theory
- Machine Intelligence
- Machine Perception
-

Tomáš Ižo
- Machine Intelligence
- Machine Perception
-

Jay Yagnik
- Data Mining and Modeling
- General Science
- Algorithms and Theory
-

Inbar Mosseri
- Machine Intelligence
- Machine Perception
