KeyPose: Estimating the 3D Pose of Transparent Objects from Stereo
September 2, 2020
Posted by Kurt Konolige, Software Engineer, Robotics at Google
Quick links
Estimating the position and orientation of 3D objects is one of the core problems in computer vision applications that involve object-level perception, such as augmented reality and robotic manipulation. In these applications, it is important to know the 3D position of objects in the world, either to directly affect them, or to place simulated objects correctly around them. While there has been much research on this topic using machine learning (ML) techniques, especially Deep Nets, most have relied on the use of depth sensing devices, such as the Kinect, which give direct measurements of the distance to an object. For objects that are shiny or transparent, direct depth sensing does not work well. For example, the figure below includes a number of objects (left), two of which are transparent stars. A depth device does not find good depth values for the stars, and gives a very poor reconstruction of the actual 3D points (right).
 |
| Left: RGB image of transparent objects. Right: A four-panel image showing the reconstructed depth for the scene on the left.The top row includes depth images and the bottom row presents the 3D point cloud. The left panels were reconstructed using a depth camera and the right panels are output from the ClearGrasp model. Note that although ClearGrasp inpaints the depth of the stars, it mistakes the actual depth of the rightmost one. |
One solution to this problem, such as that proposed by ClearGrasp, is to use a deep neural network to inpaint the corrupted depth map of the transparent objects. Given a single RGB-D image of transparent objects, ClearGrasp uses deep convolutional networks to infer surface normals, masks of transparent surfaces, and occlusion boundaries, which it uses to refine the initial depth estimates for all transparent surfaces in the scene (far right in the figure above). This approach is very promising, and allows scenes with transparent objects to be processed by pose-estimation methods that rely on depth. But inpainting can be tricky, especially when trained completely with synthetic images, and can still result in errors in depth.
In “KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects”, presented at CVPR 2020 in collaboration with the Stanford AI Lab, we describe an ML system that estimates the depth of transparent objects by directly predicting 3D keypoints. To train the system we gather a large real-world dataset of images of transparent objects in a semi-automated way, and efficiently label their pose using 3D keypoints selected by hand. We then train deep models (called KeyPose) to estimate the 3D keypoints end-to-end from monocular or stereo images, without explicitly computing depth. The models work on objects both seen and unseen during training, for both individual objects and categories of objects. While KeyPose can work with monocular images, the extra information available from stereo images allows it to improve its results by a factor of two over monocular image input, with typical errors from 5 mm to 10 mm, depending on the objects. It substantially improves over state-of-the-art in pose estimation for these objects, even when competing methods are provided with ground truth depth. We are releasing the dataset of keypoint-labeled transparent objects for use by the research community.
Real-World Transparent Object Dataset with 3D Keypoint Labels
To facilitate gathering large quantities of real-world images, we set up a robotic data-gathering system in which a robot arm moves through a trajectory while taking video with two devices, a stereo camera and the Kinect Azure depth camera.
 |
| Automated image sequence capture using a robot arm with a stereo camera and an Azure Kinect device. |
The AprilTags on the target enable accurate tracing of the pose of the cameras. By hand-labelling only a few images in each video with 2D keypoints, we can extract 3D keypoints for all frames of the video using multi-view geometry, thus increasing the labelling efficiency by a factor of 100.
We captured imagery for 15 different transparent objects in five categories, using 10 different background textures and four different poses for each object, yielding a total of 600 video sequences comprising 48k stereo and depth images. We also captured the same images with an opaque version of the object, to provide accurate ground truth depth images. All the images are labelled with 3D keypoints. We are releasing this dataset of real-world images publicly, complementing the synthetic ClearGrasp dataset with which it shares similar objects.
KeyPose Algorithm Using Early Fusion Stereo
The idea of using stereo images directly for keypoint estimation was developed independently for this project; it has also appeared recently in the context of hand-tracking. The diagram below shows the basic idea: the two images from a stereo camera are cropped around the object and fed to the KeyPose network, which predicts a sparse set of 3D keypoints that represent the 3D pose of the object. The network is trained using supervision from the labelled 3D keypoints.

One of the key aspects of stereo KeyPose is the use of early fusion to intermix the stereo images, and allow the network to implicitly compute disparity, in contrast to late fusion, in which keypoints are predicted for each image separately, and then combined. As shown in the diagram below, the output of KeyPose is a 2D keypoint heatmap in the image plane along with a disparity (i.e., inverse depth) heatmap for each keypoint. The combination of these two heatmaps yields the 3D coordinate of the keypoint, for each keypoint.
 |
| Keypose system diagram. Stereo images are passed to a CNN model to produce a probability heatmap for each keypoint. This heatmap yields 2D image coordinates U,V for the keypoint. The CNN model also produces a disparity (inverse depth) heatmap for each keypoint, which when combined with the U,V coordinates, gives a 3D position (X,Y,Z). |
When compared to late fusion or to monocular input, early fusion stereo typically is twice as accurate.
Results
The images below show qualitative results of KeyPose on individual objects. On the left is one of the original stereo images; in the middle are the predicted 3D keypoints projected onto the image. On the right, we visualize points from a 3D model of the bottle, placed at the pose determined by the predicted 3D keypoints. The network is efficient and accurate, predicting keypoints with an MAE of 5.2 mm for the bottle and 10.1 mm for the mug using just 5 ms on a standard GPU.
 |
 |
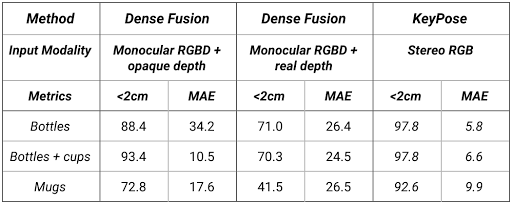
The following table shows results for KeyPose on category-level estimation. The test set used a background texture not seen by the training set. Note that the MAE varies from 5.8 mm to 9.9 mm, showing the accuracy of the method.
 |
| Quantitative comparison of KeyPose with the state-of-the-art DenseFusion system, on category-level data. We provide DenseFusion with two versions of depth, one from the transparent objects, and one from opaque objects. <2cm is the percent of estimates with errors less than 2 cm. MAE is the mean absolute error of the keypoints, in mm. |
For a complete accounting of quantitative results, as well as, ablation studies, please see the paper and supplementary materials and the KeyPose website.
Conclusion
This work shows that it is possible to accurately estimate the 3D pose of transparent objects from RGB images without reliance on depth images. It validates the use of stereo images as input to an early fusion deep net, where the network is trained to extract sparse 3D keypoints directly from the stereo pair. We hope the availability of an extensive, labelled dataset of transparent objects will help to advance the field. Finally, while we used semi-automatic methods to efficiently label the dataset, we hope to employ self-supervision methods in future work to do away with manual labelling.
Acknowledgements
I want to thank my co-authors, Xingyu Liu of Stanford University, and Rico Jonschkowski and Anelia Angelova; as well the many who helped us through discussions during the project and paper writing, including Andy Zheng, Shuran Song, Vincent Vanhoucke, Pete Florence, and Jonathan Tompson.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence