Improving End-to-End Models For Speech Recognition
December 14, 2017
Posted by Tara N. Sainath, Research Scientist, Speech Team and Yonghui Wu, Software Engineer, Google Brain Team
Quick links
Traditional automatic speech recognition (ASR) systems, used for a variety of voice search applications at Google, are comprised of an acoustic model (AM), a pronunciation model (PM) and a language model (LM), all of which are independently trained, and often manually designed, on different datasets [1]. AMs take acoustic features and predict a set of subword units, typically context-dependent or context-independent phonemes. Next, a hand-designed lexicon (the PM) maps a sequence of phonemes produced by the acoustic model to words. Finally, the LM assigns probabilities to word sequences. Training independent components creates added complexities and is suboptimal compared to training all components jointly. Over the last several years, there has been a growing popularity in developing end-to-end systems, which attempt to learn these separate components jointly as a single system. While these end-to-end models have shown promising results in the literature [2, 3], it is not yet clear if such approaches can improve on current state-of-the-art conventional systems.
Today we are excited to share “State-of-the-art Speech Recognition With Sequence-to-Sequence Models [4],” which describes a new end-to-end model that surpasses the performance of a conventional production system [1]. We show that our end-to-end system achieves a word error rate (WER) of 5.6%, which corresponds to a 16% relative improvement over a strong conventional system which achieves a 6.7% WER. Additionally, the end-to-end model used to output the initial word hypothesis, before any hypothesis rescoring, is 18 times smaller than the conventional model, as it contains no separate LM and PM.
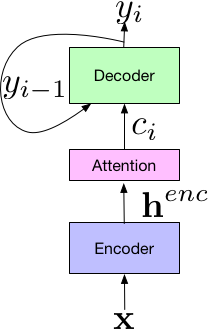
Our system builds on the Listen-Attend-Spell (LAS) end-to-end architecture, first presented in [2]. The LAS architecture consists of 3 components. The listener encoder component, which is similar to a standard AM, takes the a time-frequency representation of the input speech signal, x, and uses a set of neural network layers to map the input to a higher-level feature representation, henc. The output of the encoder is passed to an attender, which uses henc to learn an alignment between input features x and predicted subword units {yn, … y0}, where each subword is typically a grapheme or wordpiece. Finally, the output of the attention module is passed to the speller (i.e., decoder), similar to an LM, that produces a probability distribution over a set of hypothesized words.
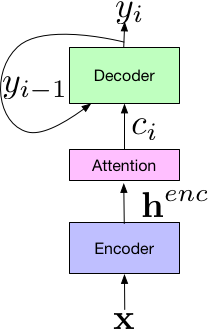 |
| Components of the LAS End-to-End Model. |
Additionally, because the LAS model is fully neural, there is no need for external, manually designed components such as finite state transducers, a lexicon, or text normalization modules. Finally, unlike conventional models, training end-to-end models does not require bootstrapping from decision trees or time alignments generated from a separate system, and can be trained given pairs of text transcripts and the corresponding acoustics.
In [4], we introduce a variety of novel structural improvements, including improving the attention vectors passed to the decoder and training with longer subword units (i.e., wordpieces). In addition, we also introduce numerous optimization improvements for training, including the use of minimum word error rate training [5]. These structural and optimization improvements are what accounts for obtaining the 16% relative improvement over the conventional model.
Another exciting potential application for this research is multi-dialect and multi-lingual systems, where the simplicity of optimizing a single neural network makes such a model very attractive. Here data for all dialects/languages can be combined to train one network, without the need for a separate AM, PM and LM for each dialect/language. We find that these models work well on 7 english dialects [6] and 9 Indian languages [7], while outperforming a model trained separately on each individual language/dialect.
While we are excited by our results, our work is not done. Currently, these models cannot process speech in real time [8, 9, 10], which is a strong requirement for latency-sensitive applications such as voice search. In addition, these models still compare negatively to production when evaluated on live production data. Furthermore, our end-to-end model is learned on 22 million audio-text pair utterances compared to a conventional system that is typically trained on significantly larger corpora. In addition, our proposed model is not able to learn proper spellings for rarely used words such as proper nouns, which is normally performed with a hand-designed PM. Our ongoing efforts are focused now on addressing these challenges.
Acknowledgements
This work was done as a strong collaborative effort between Google Brain and Speech teams. Contributors include Tara Sainath, Rohit Prabhavalkar, Bo Li, Kanishka Rao, Shankar Kumar, Shubham Toshniwal, Michiel Bacchiani and Johan Schalkwyk from the Speech team; as well as Yonghui Wu, Patrick Nguyen, Zhifeng Chen, Chung-cheng Chiu, Anjuli Kannan, Ron Weiss, Navdeep Jaitly, William Chan, Yu Zhang and Jan Chorowski from the Google Brain team. The work is described in more detail in papers [4-12].
References
[1] G. Pundak and T. N. Sainath, “Lower Frame Rate Neural Network Acoustic Models," in Proc. Interspeech, 2016.
[2] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, attend and spell,” CoRR, vol. abs/1508.01211, 2015
[3] R. Prabhavalkar, K. Rao, T. N. Sainath, B. Li, L. Johnson, and N. Jaitly, “A Comparison of Sequence-to-sequence Models for Speech Recognition,” in Proc. Interspeech, 2017.
[4] C.C. Chiu, T.N. Sainath, Y. Wu, R. Prabhavalkar, P. Nguyen, Z. Chen, A. Kannan, R.J. Weiss, K. Rao, K. Gonina, N. Jaitly, B. Li, J. Chorowski and M. Bacchiani, “State-of-the-art Speech Recognition With Sequence-to-Sequence Models,” submitted to ICASSP 2018.
[5] R. Prabhavalkar, T.N. Sainath, Y. Wu, P. Nguyen, Z. Chen, C.C. Chiu and A. Kannan, “Minimum Word Error Rate Training for Attention-based Sequence-to-Sequence Models,” submitted to ICASSP 2018.
[6] B. Li, T.N. Sainath, K. Sim, M. Bacchiani, E. Weinstein, P. Nguyen, Z. Chen, Y. Wu and K. Rao, “Multi-Dialect Speech Recognition With a Single Sequence-to-Sequence Model” submitted to ICASSP 2018.
[7] S. Toshniwal, T.N. Sainath, R.J. Weiss, B. Li, P. Moreno, E. Weinstein and K. Rao, “End-to-End Multilingual Speech Recognition using Encoder-Decoder Models”, submitted to ICASSP 2018.
[8] T.N. Sainath, C.C. Chiu, R. Prabhavalkar, A. Kannan, Y. Wu, P. Nguyen and Z. Chen, “Improving the Performance of Online Neural Transducer Models”, submitted to ICASSP 2018.
[9] C.C. Chiu* and C. Raffel*, “Monotonic Chunkwise Attention,” submitted to ICLR 2018.
[10] D. Lawson*, C.C. Chiu*, G. Tucker*, C. Raffel, K. Swersky, N. Jaitly. “Learning Hard Alignments with Variational Inference”, submitted to ICASSP 2018.
[11] T.N. Sainath, R. Prabhavalkar, S. Kumar, S. Lee, A. Kannan, D. Rybach, V. Schogol, P. Nguyen, B. Li, Y. Wu, Z. Chen and C.C. Chiu, “No Need for a Lexicon? Evaluating the Value of the Pronunciation Lexica in End-to-End Models,” submitted to ICASSP 2018.
[12] A. Kannan, Y. Wu, P. Nguyen, T.N. Sainath, Z. Chen and R. Prabhavalkar. “An Analysis of Incorporating an External Language Model into a Sequence-to-Sequence Model,” submitted to ICASSP 2018.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯
