Sound & Accoustics
- Algorithms & Theory
- Climate & Sustainability
- Conferences & Events
- Data Management
- Data Mining & Modeling
- Distributed Systems & Parallel Computing
- Earth AI
- Economics & Electronic Commerce
- Education Innovation
- General Science
- Generative AI
- Global
- Hardware & Architecture
- Health & Bioscience
- Human-Computer Interaction and Visualization
- Machine Intelligence
- Machine Perception
- Machine Translation
- Mobile Systems
- Natural Language Processing
- Networking
- Open Source Models & Datasets
- Photography
- Product
- Programs
- Quantum
- RAI-HCT Highlights
- Responsible AI
- Robotics
- Security, Privacy and Abuse Prevention
- Software Systems & Engineering
- Sound & Accoustics
- Speech Processing
- Year in Review
-

February 9, 2026
How AI trained on birds is surfacing underwater mysteries- Climate & Sustainability ·
- Open Source Models & Datasets ·
- Sound & Accoustics
-

December 3, 2025
From Waveforms to Wisdom: The New Benchmark for Auditory Intelligence- Machine Intelligence ·
- Sound & Accoustics ·
- Speech Processing
-

July 2, 2025
Making group conversations more accessible with sound localization- Human-Computer Interaction and Visualization ·
- Sound & Accoustics ·
- Speech Processing
-
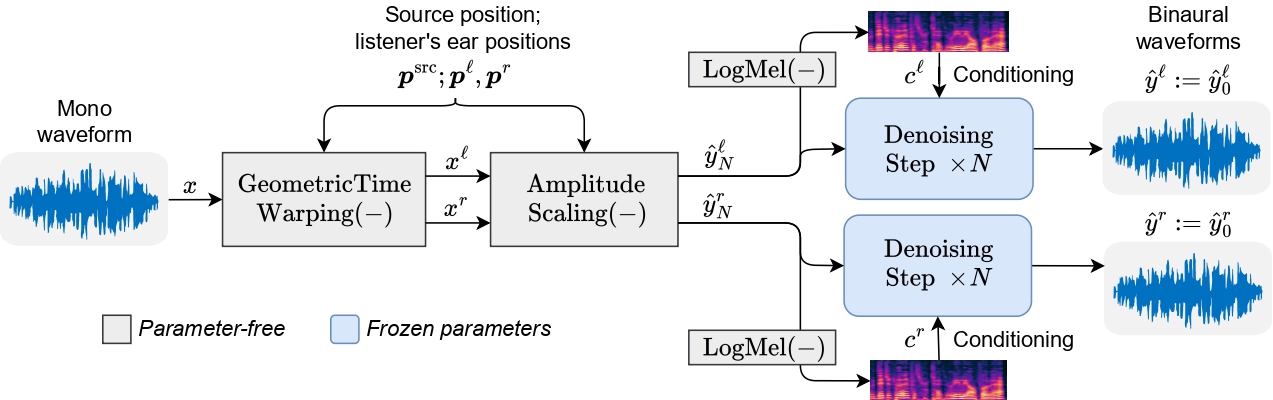
January 16, 2025
Zero-shot mono-to-binaural speech synthesis- Sound & Accoustics ·
- Speech Processing
-

September 18, 2024
Whistles, songs, boings, and biotwangs: Recognizing whale vocalizations with AI- Climate & Sustainability ·
- Open Source Models & Datasets ·
- Sound & Accoustics
-

April 12, 2024
Contrastive neural audio separation- Machine Intelligence ·
- Sound & Accoustics
-

July 26, 2023
In search of a generalizable method for source-free domain adaptation- Sound & Accoustics
-

June 22, 2023
SoundStorm: Efficient parallel audio generation- Sound & Accoustics ·
- Speech Processing
-

March 9, 2023
The BirdCLEF 2023 Challenge: Pushing the frontiers of biodiversity monitoring- Climate & Sustainability ·
- Sound & Accoustics
-

December 14, 2022
Who said what? Recorder's on-device solution for labeling speakers- Mobile Systems ·
- Sound & Accoustics ·
- Speech Processing
-
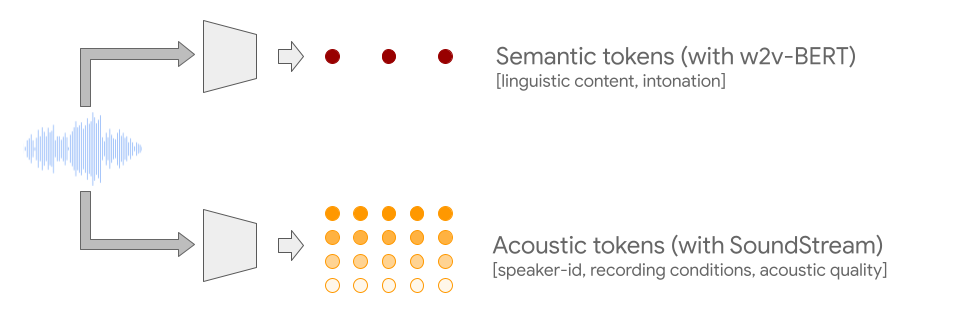
October 6, 2022
AudioLM: a Language Modeling Approach to Audio Generation- Machine Intelligence ·
- Sound & Accoustics
-
March 3, 2022
TRILLsson: Small, Universal Speech Representations for Paralinguistic Tasks- Machine Intelligence ·
- Mobile Systems ·
- Sound & Accoustics ·
- Speech Processing