Discovering new words with confidential federated analytics
March 4, 2025
Timon Van Overveldt, Software Engineer, and Daniel Ramage, Research Director
We announce a new technique, called confidential federated analytics, which offers strong transparency in exactly how user data is handled and analyzed when applying federated analytics.
Quick links
Introduced by Google Research in 2020, federated analytics allows for the application of data science methods to the analysis of raw data stored locally on users’ devices so that only the aggregated results — and not data from any particular device — are made available to product engineers. This keeps users' data private, while enabling applications from on-device intelligence features, to keyboard modeling, to estimating carbon emissions.
In traditional federated analytics, devices respond to queries by sending minimized messages. Raw data stays on the device while updates that focus on a particular purpose are sent to the server for immediate aggregation (either ephemerally, where the raw data are immediately deleted after aggregation, or via cryptographic secure aggregation). But today, users cannot inspect how their data is being aggregated, which may undermine their confidence that their sensitive data will be managed securely.
To address this, we created confidential federated analytics, a technique that leverages confidential computing to improve data privacy by publicizing the analyses that will be performed using device data before the data are uploaded, and by restricting data access to only those analyses. With this approach, no other analyses can be performed on the data and no human can access data from individual devices. The resulting aggregated output of the analyses can offer strong anonymization guarantees to individuals. Any subversion of these properties, accidental or malicious, would be discoverable by third parties. These properties are made possible by (and subject to the correctness of) trusted execution environments (TEEs) built into modern CPUs from AMD, Intel, and others.
With confidential federated analytics, for the first time ever, all privacy-relevant server-side software is now inspectable. This means that any organization using confidential federated analytics can now be completely transparent about the privacy properties of their data processing. This approach is an application of confidential federated computations, a more general framework that also applies to machine learning. The source code for confidential federated analytics is available now as part of Google Parfait, in the confidential federated compute and trusted computations platform repositories. In our recent paper, “Federated Learning in Practice: Reflections and Projections”, we describe the relationship between confidential federated computation and traditional federated learning and analytics.
How confidential federated analytics works
To illustrate how confidential federated analytics works, we describe its successful implementation in Gboard, the popular Android keyboard app. Language evolves continuously, with new words and phrases gaining popularity as technological, cultural, and other changes shape the world. Users of phone keyboards like Gboard expect to easily type common words, even new ones that were unknown just a few months ago. This means that Gboard must have a way of discovering new common words to incorporate them into the typing model, without revealing any uncommon private words. Further, these new words should be discoverable across the 900+ languages that people type in Gboard every day, a problem we’ve previously studied with federated analytics.
Our previous use of federated analytics for the problem used the LDP-TrieHH algorithm, which uses local differential privacy (LDP) that applies noise before upload to protect against a server peeking at individual device data. While LDP-TrieHH achieved a strong anonymization guarantee if the server does not peek, it achieves only a weak local DP guarantee (ε= 10 per device, per day) against servers that do. It requires weeks to run, and often fails to discover new words in languages with low volumes of users.
With confidential federated analytics we can reach more devices, more languages, and discover more words. For example, we discovered 3,600 previously missing Indonesian words in just two days. And, because this approach allows the DP algorithm to be externally verified, it also offers a substantially improved DP guarantee (ε = ln(3) per device, per week).
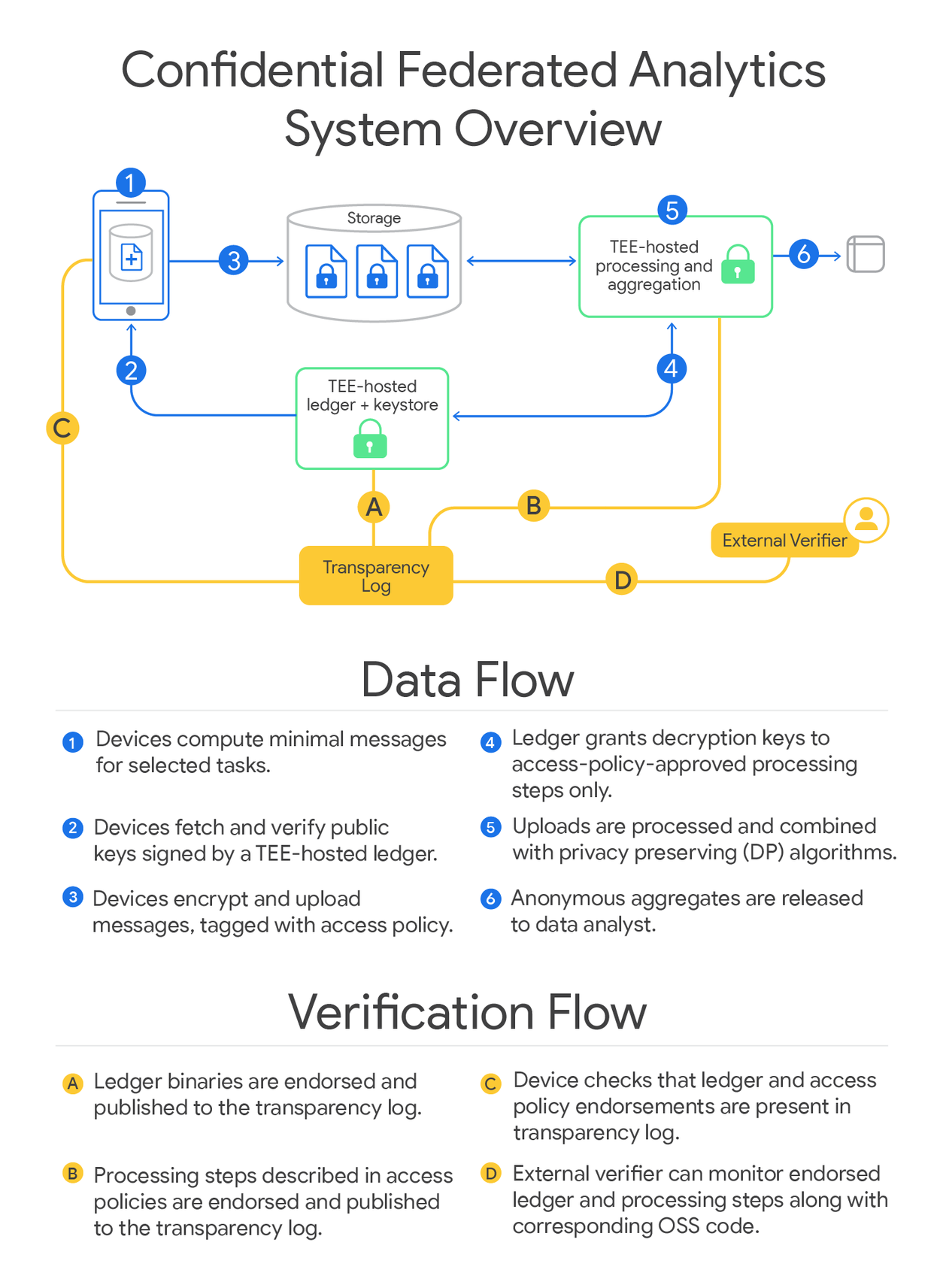
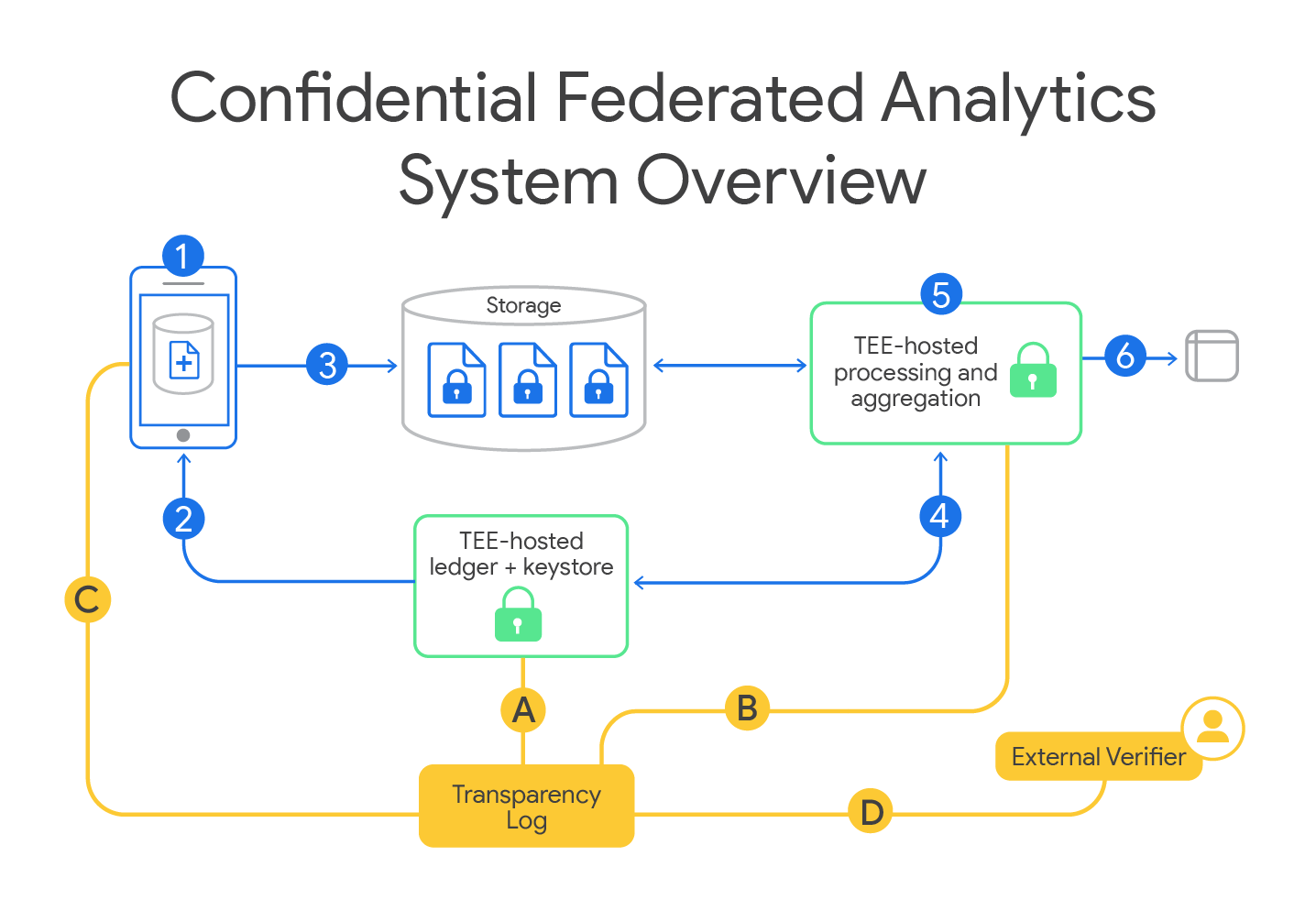
Like other federated analytics applications, the first step in confidential federated analytics consists of devices securely storing locally potential new words that have been typed but are not present in the on-device dictionary. Devices then encrypt their data and upload it to the server along with a set of processing steps that the server is authorized to use for decryption. For this, the devices use encryption keys managed by a central service, called a ledger. The ledger releases decryption keys only to those device-approved processing steps that must also run in a properly configured TEE.
In this case, the data processing steps implement a differentially private algorithm designed to identify the most frequently occurring items within a dataset while simultaneously protecting the privacy of individual data points by adding noise. The differential privacy (DP) guarantee ensures that the algorithm’s top words list cannot be too heavily influenced by any one device, and is considered a gold standard for formal data anonymization.
For a device to know that the decryption keys are protected by a ledger, it must leverage multiple TEE properties (in our case, via Google’s Project Oak attestation stack running on AMD SEV-SNP). When an application runs in a TEE, it gains confidentiality (i.e., its internal state is secret, even from system administrators) and integrity (system administrators cannot force the application to deviate from its correct operation). The TEE also provides cryptographic identity unique to each chip, which can be used to attest to the exact state of the firmware, operating system, and software running on the CPU. The ledger creates public–private key pairs, signing the public key with a signing key tied to the TEE's attestation. This signature, along with the TEE properties listed above, allows devices to verify that they are using a public key managed by our ledger implementation.
The processing steps that a device approves at the time of upload are named in a structured access policy associated with the uploaded data and enforced by the ledger. For our use case above, the goal is to run a differentially private discovery algorithm. Specifically, we use a stability-based histogram algorithm for the discovery of frequently typed words and their approximate counts. The algorithm works by adding noise to the counts of words in the aggregated histogram, keeping only the words with counts above a target threshold, illustrated below. The algorithm implementation is published as open source software.
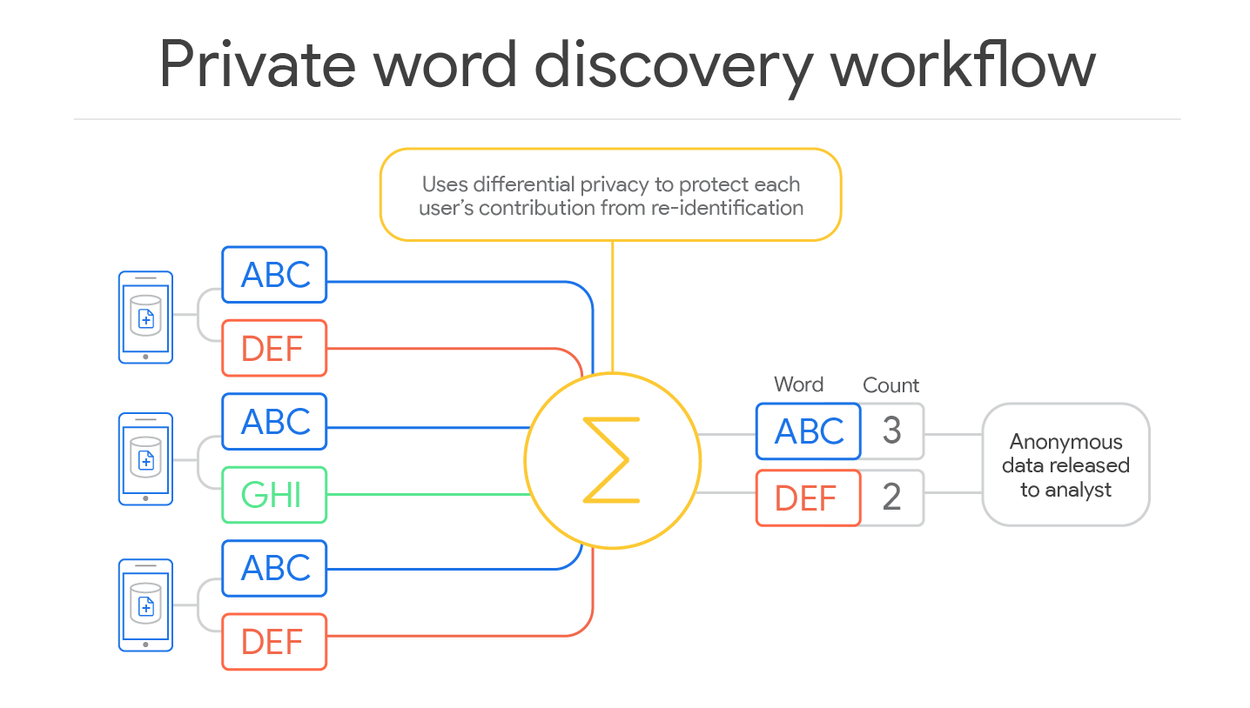
The access policy that corresponds to the implementation of this algorithm authorizes a two-stage data processing pipeline. The first stage pre-processes each client's data using per-client SQL queries to limit the number of words a client can contribute before performing a partial aggregation. The second performs final aggregation, DP noising, and thresholding. Only when the pipeline's differentially private output has been fully computed is an un-encrypted and fully anonymous result released to the data analyst.
Thus, with correctly implemented ledger and data processing steps, devices can upload data to be processed only as part of a device-approved, privacy-preserving pipeline, and have confidence that it cannot be used for any other purpose. Of course, these guarantees are subject to the strengths and limitations of current generation TEEs, an area with risks that include side-channel attacks. Further, attacks and algorithmic defenses against them are ongoing areas of research.
Scaling confidential federated analytics
Applying confidential federated computations to many applications and many devices over long periods of time requires additional design considerations. For example, if the ledger TEE crashes, all datasets and intermediate results protected by that ledger will be lost (no decryption keys).
To mitigate this single-point-of-failure, we implement our ledger as a replicated state machine via code hosted in our Trusted Computations Platform repository, using an industry-proven consensus protocol (Raft) for fault-tolerance. By modeling the ledger as a replicated state machine, we also guarantee that uploaded data cannot be analyzed repeatedly by the same data processing pipeline. Such re-analyses can undermine an algorithm’s differential privacy guarantee, for example, by averaging out noise across multiple runs.
By publishing the access policies and the TEE binaries they reference, and by publishing the ledger binaries that enforce these policies, we hope to set a new standard for external verifiability for our privacy-preserving technologies. We publish signatures to a publicly readable, immutable, and tamper-resistant transparency log (Rekor), and before uploading any data, devices check that the ledger attestation evidence and applicable access policy have a Rekor inclusion proof. This ensures that uploaded device data can only ever be processed by binaries for which the source code and configuration are externally inspectable. We've published a step-by-step guide to inspecting attestation verification records, and we invite external researchers to join us in evaluating and improving these claims.
Conclusion
We’re excited to have shared these initial steps toward scalable and privacy-preserving confidential federated computations by describing systems running in production on real devices today and providing more external verifiability of the end-to-end system than ever before.
Going beyond analytics use cases, we expect to soon apply the confidential federated computations technique to Gboard's model learning use cases as well. Furthermore, confidential federated computations promise to further strengthen the privacy guarantees offered by federated learning and analytics in many Google apps and systems, including those in Android Private Compute Core and Android’s approach to private AI.
Acknowledgements
The authors would like to thank Dzmitry Huba, Hubert Eichner, Kallista Bonawitz, Mark Simborg, Peter Kairouz, Prem Eruvbetine, Sarah de Haas for their extensive feedback and editing on the blog post itself, and the teams at Google that helped with algorithm design, infrastructure implementation, and production maintenance. In particular, we would like to thank the collaborators who directly contributed to this effort: Adria Gascon, Albert Cheu, Allie Culp, Andri Saar, Artem Lagzdin, Brendan McMahan, Brett McLarnon, Chloé Kiddon, Chunxiang Zheng, Conrad Grobler, Edo Roth, Emily Glanz, Ernesto Ocampo, Grace Ni, Haicheng Sun, Ivan Petrov, Jeremy Gillula, Jianpeng Hou, Joe Woodworth, Juliette Pluto, Katharine Daly, Katsiaryna Naliuka, Marco Gruteser, Maya Spivak, Mira Holford, Nova Fallen, Octavian Suciu, Rakshita Tandon, Shumin Zhai, Stanislav Chiknavaryan, Stefan Dierauf, Steve He, Tiziano Santoro, Tom Binder, Ulyana Kurylo, Wei Huang, Yanxiang Zhang, Yu Xiao, Yuanbo Zhang, Zachary Charles, Zheng Xu, Zhimin Yao, and Zoe Gong. This work was supported by Corinna Cortes, Four Flynn, Blaise Aguera y Arcas, and Yossi Matias.
Quick links
Other posts of interest
-

January 22, 2026
Small models, big results: Achieving superior intent extraction through decomposition- Generative AI ·
- Machine Perception ·
- Mobile Systems
-
December 10, 2025
A differentially private framework for gaining insights into AI chatbot use- Generative AI ·
- Responsible AI ·
- Security, Privacy and Abuse Prevention
-

November 12, 2025
Differentially private machine learning at scale with JAX-Privacy- Algorithms & Theory ·
- Responsible AI ·
- Security, Privacy and Abuse Prevention

