Agile and Intelligent Locomotion via Deep Reinforcement Learning
May 6, 2020
Posted by Yuxiang Yang and Deepali Jain, AI Residents, Robotics at Google
Quick links
Recent advancements in deep reinforcement learning (deep RL) has enabled legged robots to learn many agile skills through automated environment interactions. In the past few years, researchers have greatly improved sample efficiency by using off-policy data, imitating animal behaviors, or performing meta learning. However, sample efficiency remains a bottleneck for most deep reinforcement learning algorithms, especially in the legged locomotion domain. Moreover, most existing works focus on simple, low-level skills only, such as walking forward, backward and turning. In order to operate autonomously in the real world, robots still need to combine these skills to generate more advanced behaviors.
Today we present two projects that aim to address the above problems and help close the perception-actuation loop for legged robots. In “Data Efficient Reinforcement Learning for Legged Robots”, we present an efficient way to learn low level motion control policies. By fitting a dynamics model to the robot and planning for actions in real time, the robot learns multiple locomotion skills using less than 5 minutes of data. Going beyond simple behaviors, we explore automatic path navigation in “Hierarchical Reinforcement Learning for Quadruped Locomotion”. With a policy architecture designed for end-to-end training, the robot learns to combine a high-level planning policy with a low-level motion controller, in order to navigate autonomously through a curved path.
Data Efficient Reinforcement Learning for Legged Robots
A major roadblock in RL is the lack of sample efficiency. Even with a state-of-the-art sample-efficient learning algorithm like Soft Actor-Critic (SAC), it would still require more than an hour of data to learn a reasonable walking policy, which is difficult to collect in the real world.
In a continued effort to learn walking skills using minimal interaction with the real-world environment, we present another, more sample-efficient model-based method for learning basic walking skills that dramatically reduces the training data needed. Instead of directly learning a policy that maps from environment state to robot action, we learn a dynamics model of the robot that estimates future states given its current state and action. Since the entire learning process requires less than 5 minutes of data, it could be performed directly on the real robot.
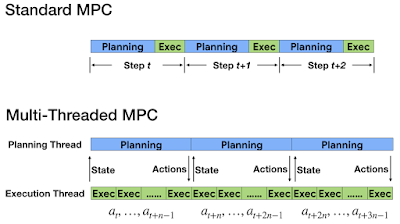
We start by executing random actions on the robot, and fit the model to the data collected. With the model fitted, we control the robot using a model predictive control (MPC) planner. We iterate between collecting more data with MPC and re-training the model to better fit the dynamics of the environment.
 |
| Overview of the model-based learning pipeline. The system alternates between fitting the dynamics model and collecting trajectories using model predictive control (MPC). |
 |
| We separate action planning and execution on different threads. |
Safety is another concern for learning on the real robot. For legged robots, a small mistake, such as missing a foot step, could lead to catastrophic failures, from the robot falling to the motor overheating. To ensure safe exploration, we embed a stable, in-place stepping gait prior, that is modulated by a trajectory generator. With the stable walking prior, MPC can then safely explore the action space.
Combining an accurate dynamics model with an online, asynchronous MPC controller, the robot successfully learned to walk using only 4.5 minutes of data (36 episodes). The learned dynamics model is also generalizable: by simply changing the reward function of MPC, the controller is able to optimize for different behaviors, such as walking backwards, or turning, without re-training. As an extension, we use a similar framework to enable even more agile behaviors. For example, in simulation the robot learns to backflip and walk on its rear legs, though these behaviors are yet to be learned by the real robot.
 |
| The robot learns to walk using only 4.5 minutes of data. |
 |
| The robot learns to backflip and walk with rear legs using the same framework. |
Although model-based RL has allowed the robot to learn simple locomotion skills efficiently, such skills are insufficient for handling complex, real-world tasks. For example, in order to navigate through an office space, the robot may have to adjust its speed, direction and height multiple times, instead of following a pre-defined speed profile. Traditionally, people solve such complex tasks by breaking them down into multiple hierarchical sub-problems, such as a high-level trajectory planner and a low-level trajectory-following controller. However, manually defining a suitable hierarchy is typically a tedious task, as it requires careful engineering for each sub-problem.
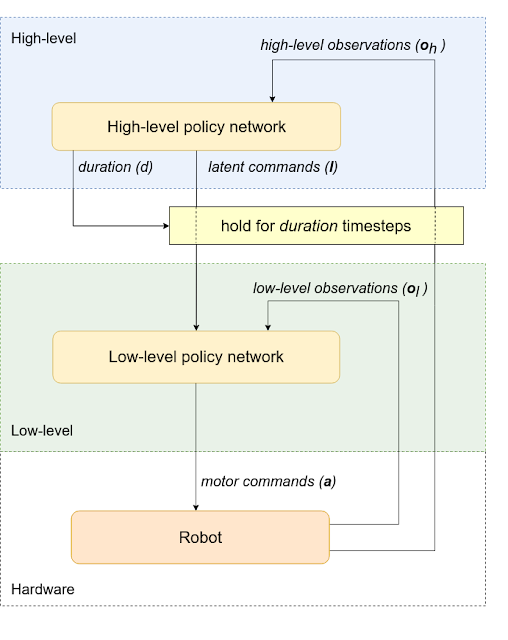
In our second paper, we introduce a hierarchical reinforcement learning (HRL) framework that can be trained to automatically decompose complex reinforcement learning tasks. We break down our policy structure into a high-level and a low-level policy. Instead of designing each policy manually, we only define a simple communication protocol between the policy levels. In this framework, the high-level policy (e.g., a trajectory planner) commands the low-level policy (such as the motion control policy) through a latent command, and decides for how long to hold that command constant before issuing a new one. The low-level policy then interprets the latent command from the high-level policy, and gives motor commands to the robot.
To facilitate learning, we also split the observation space into high-level (e.g., robot position and orientation) and low-level (IMU, motor positions) observations, which are fed to their corresponding policies. This architecture naturally allows the high-level policy to operate at a slower timescale than the low-level policy, which saves computation resources and reduces training complexity.
 |
| Framework of Hierarchical Policy: The policy gets observations from the robot and sends motor commands to execute desired actions. It is split into two levels (high and low). The high-level policy gives a latent command to the low-level policy and also decides the duration for which low-level will run. |
We test our framework on a path-following task using the same quadruped robot. In addition to straight walking, the robot needs to steer in different directions to complete the task. Note that as the low-level policy does not know the robot’s position in the path, it does not have sufficient information to complete the entire task on its own. However, with the coordination between the high-level and low-level policies, steering behavior emerges automatically in the latent command space, which allows the robot to efficiently complete the path. After successful training in a simulated environment, we validate our results on hardware by transferring an HRL policy to a real robot and recording the resulting trajectories.
 |
| Successful trajectory of a robot on a curved path. Left: A plot of the trajectory traversed by the robot with dots along the trajectory marking the positions where the high-level policy sent a new latent command to the low-level policy. Middle: The robot walking along the path in the simulated environment. Right: The robot walking around the path in the real world. |
 |
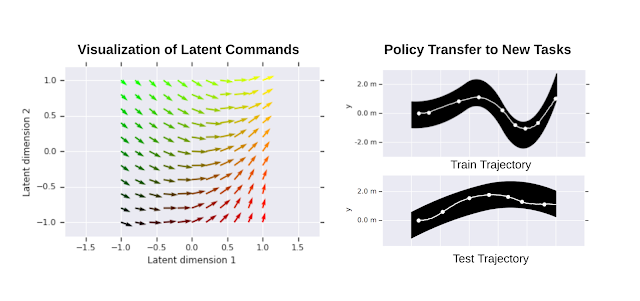
| Left: Visualization of a learned 2D latent command space. Vector directions correspond to the movement direction of the robot. Vector length is proportional to the distance covered. Right: Transfer of low level policy: An HRL policy was trained on a single path (right, top). The learned low-level policy was then reused when training the high-level policy on other paths (e.g., right, bottom). |
Reinforcement learning poses a promising future for robotics by automating the controller design process. With model-based RL, we enabled efficient learning of generalizable locomotion behaviors directly on the real robot. With hierarchical RL, the robot learned to coordinate policies at different levels to achieve more complex tasks. In the future, we plan to bring perception into the loop, so that robots can operate truly autonomously in the real world.
Acknowledgements
Both Deepali Jain and Yuxiang Yang are residents in the AI Residency program, mentored by Ken Caluwaerts and Atil Iscen. We would also like to thank Jie Tan and Vikas Sindhwani for support of the research, and Noah Broestl for managing the New York AI Residency Program.
-
Labels:
- Machine Intelligence
- Robotics
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯