Zero-shot mono-to-binaural speech synthesis
January 16, 2025
Alon Levkovitch, Software Engineer, and Eliya Nachmani, Research Scientist
We present a neural method to synthesize binaural audio from monaural audio recordings and positional information without training on any binaural data.
Quick links
Humans possess a remarkable ability to localize sound sources and perceive the surrounding environment through auditory cues alone. This sensory ability, known as spatial hearing, plays a critical role in numerous everyday tasks, including identifying speakers in crowded conversations and navigating complex environments. Hence, emulating a coherent sense of space via listening devices like headphones becomes paramount to creating truly immersive artificial experiences. Due to the lack of multi-channel and positional data for most acoustic and room conditions, the robust and low- or zero-resource synthesis of binaural audio from single-source, single-channel (mono) recordings is a crucial step towards advancing augmented reality (AR) and virtual reality (VR) technologies.
Conventional mono-to-binaural synthesis techniques leverage a digital signal processing (DSP) framework. Within this framework, the way sound is scattered across the room to the listener’s ears is formally described by the head-related transfer function and the room impulse response. These functions, along with the ambient noise, are modeled as linear time-invariant systems and are obtained in a meticulous process for each simulated room. Such DSP-based approaches are prevalent in commercial applications due to their established theoretical foundation and their ability to generate perceptually realistic audio experiences.
Considering these limitations in conventional approaches, the possibility of using machine learning to synthesize binaural audio from monophonic sources is very appealing. However, doing so using standard supervised learning models is still very difficult. This is due to two primary challenges: (1) the scarcity of position-annotated binaural audio datasets, and (2) the inherent variability of real-world environments, characterized by diverse room acoustics and background noise conditions. Moreover, supervised models are susceptible to overfitting to the specific rooms, speaker characteristics, and languages in the training data, especially when their training dataset is small.
To address these limitations, we present ZeroBAS, the first zero-shot method for neural mono-to-binaural audio synthesis, which leverages geometric time warping, amplitude scaling, and a (monaural) denoising vocoder. Notably, we achieve natural binaural audio generation that is perceptually on par with existing supervised methods, despite never seeing binaural data. We further present a novel dataset-building approach and dataset, TUT Mono-to-Binaural, derived from the location-annotated ambisonic recordings of speech events in the TUT Sound Events 2018 dataset. When evaluated on this out-of-distribution data, prior supervised methods exhibit degraded performance, while ZeroBAS continues to perform well.
Architecture
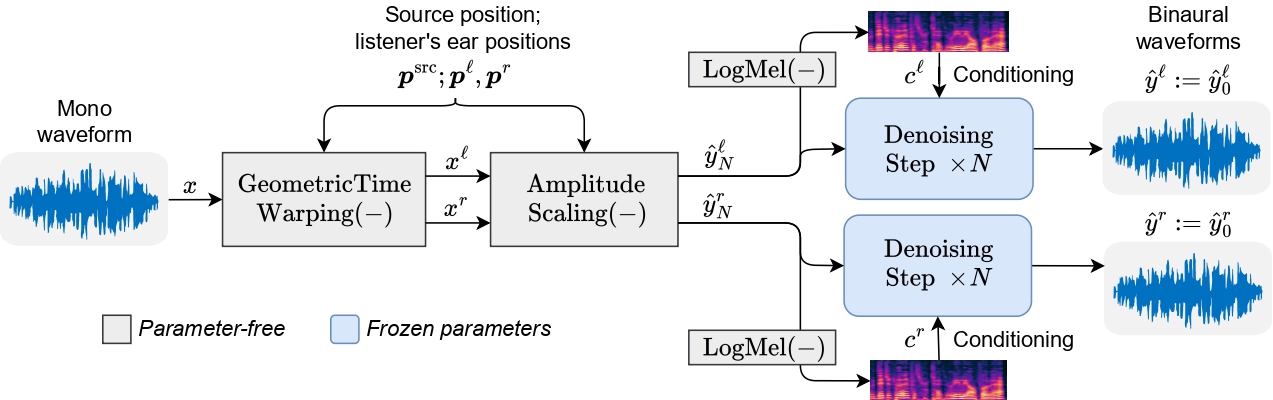
Our proposed zero-shot mono-to-binaural synthesis method utilizes a three-stage architecture. The first stage follows previous work, performing geometric time warping (GTW) to manipulate the input mono waveform into two channels based on the provided position of the speaker relative to the listener. Subsequently, our proposed amplitude scaling (AS) module adjusts the amplitude of the warped signal according to the relative position information. Finally, an existing denoising vocoder iteratively refines the processed signal to generate the binaural output composed of two channels.
Geometric time warping
GTW aims to estimate a warpfield that separates the left and right binaural signals by applying the interaural time delay based on the relative positions of the sound source and the listener's ears. GTW generates an initial estimate of the perceived signals by using the speed of sound, the distances between the listener’s ears and the speaker. This approach offers a simple and parameter-free solution for a warpfield which can be applied to the mono signal.
Amplitude scaling
In addition to manipulating the time-delay of the signal, we also manipulate the amplitude of the signal based on the position of the speaker. Human spatial perception of sound relies on various factors, including the interaural time delay, the interaural level difference, and spectral cues due to head-related transfer functions. While prior works suggest that the interaural level difference is mostly caused by scattering off of the head and is dominant in human spatial perception for sounds with high frequencies, we find that amplitude scaling based on the inverse square law has a positive effect on the perceived spatial accuracy of the processed signal. Our approach aims to leverage this amplitude manipulation to enhance the spatial realism of the generated binaural audio.
Denoising vocoder
GTW and AS are simple, parameter-free operations that only roughly approximate binaural audio; using the warped and scaled speech signals as-is results in acoustic artifacts and inconsistencies. Hence, there is a need for further refinement to generate natural-sounding binaural audio. To this end, we propose that a sufficiently well-trained denoising vocoder could be used on each signal — we use a WaveFit neural vocoder. It is a fixed-point iteration vocoder that takes the denoising perspective of Denoising Diffusion Probabilistic Models (DDPMs) and the discriminator of generative adversarial networks to learn to generate natural speech from a degraded input speech signal. As a vocoder, it takes log-mel spectrogram features and noise as input and produces clean waveform output. The WaveFit variant used was trained on the LibriLight dataset.
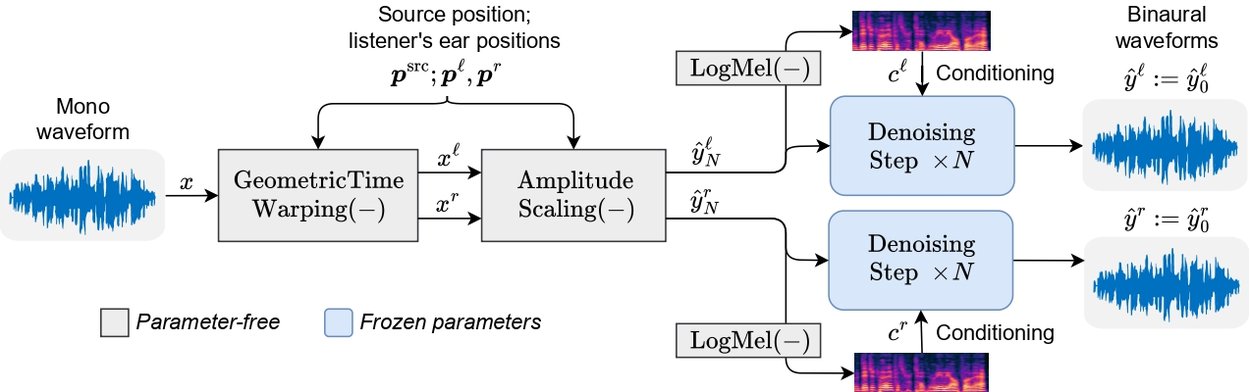
Our proposed ZeroBAS method. Mono waveform is binauralized with geometric time warping conditional on the speaker’s position, then the two channels’ amplitudes are scaled. Each channel is then denoised N = 3 times by a low noise-level step of a monaural denoising vocoder.
Audio samples
Binaural speech dataset
| Subject 1 | Subject 2 | |
| Ground Truth | ||
| Mono | ||
| ZeroBAS | ||
| WarpNet | ||
| BinauralGrad | ||
| NFS |
TUT mono to binaural dataset
| Subject 50 | Subject 73 | |
| Ground Truth | ||
| Mono | ||
| ZeroBAS | ||
| WarpNet | ||
| BinauralGrad | ||
| NFS |
Additional samples can be heard on our demo page.
Performance
We evaluated the performance of ZeroBAS on two datasets. The first is the binaural speech dataset, which contains paired mono and binaural audio with tracking information, jointly collected in an echo-free (i.e., non-anechoic) room. The second dataset is an adapted version of TUT Sound Events 2018, which we name "TUT Mono-to-Binaural". Adaptation was done by converting coordinates from azimuth, distance and elevation to cartesian format, extracting monaural audio and speech segments by using available metadata, and rendering ambisonic recordings into binaural recordings.
For evaluations, similar to prior work, we use:
- Wave L2: The mean squared error (MSE) between the ground truth and synthesized per-channel waveforms (scaled by 103).
- Amplitude L2: MSE between the short-time Fourier transforms (STFT) of the ground truth and synthesized audio, with respect to amplitude (multiplied by 10).
- Phase L2: MSE between the left–right phase angle of the ground truth and synthesized audio computed from the STFT.
- MRSTFT: The multi-resolution spectral loss.
- Mean opinion score (MOS): Human evaluators are tasked with assigning a rating on a five-point scale to denote the perceived naturalness of a given speech utterance.
- Multiple Stimuli with Hidden Reference and Anchor score (MUSHRA): Human raters are asked to rate how similar each model output is to the reference on a scale from 0 to 100.
Binaural speech dataset
Subjective evaluation results show that ZeroBAS sounds slightly more natural to human raters than the supervised methods while being on par in quantitative evaluations. In MOS, ZeroBAS improves over WarpNet, and is comparable to BinauralGrad and NFS, while MUSHRA results show that human raters do not have a statistically significant preference for any of the methods.
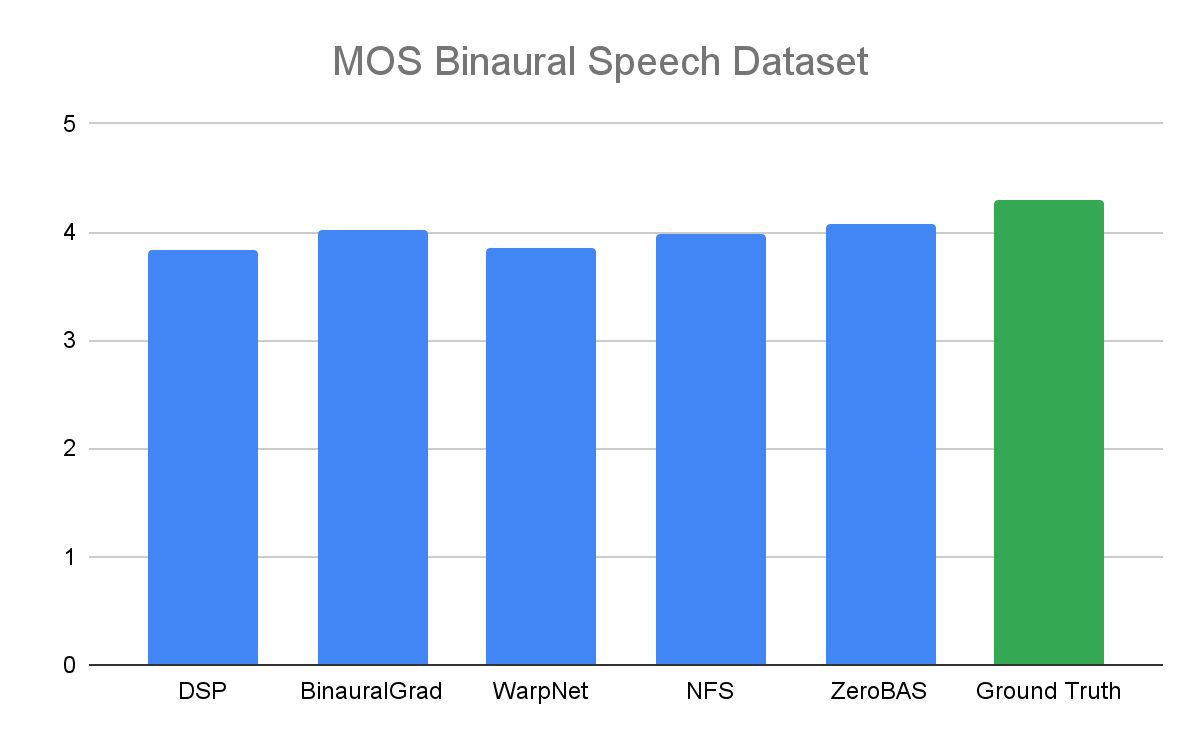
Mean opinion score (MOS) on the Binaural Speech dataset computed by ratings from human evaluators.
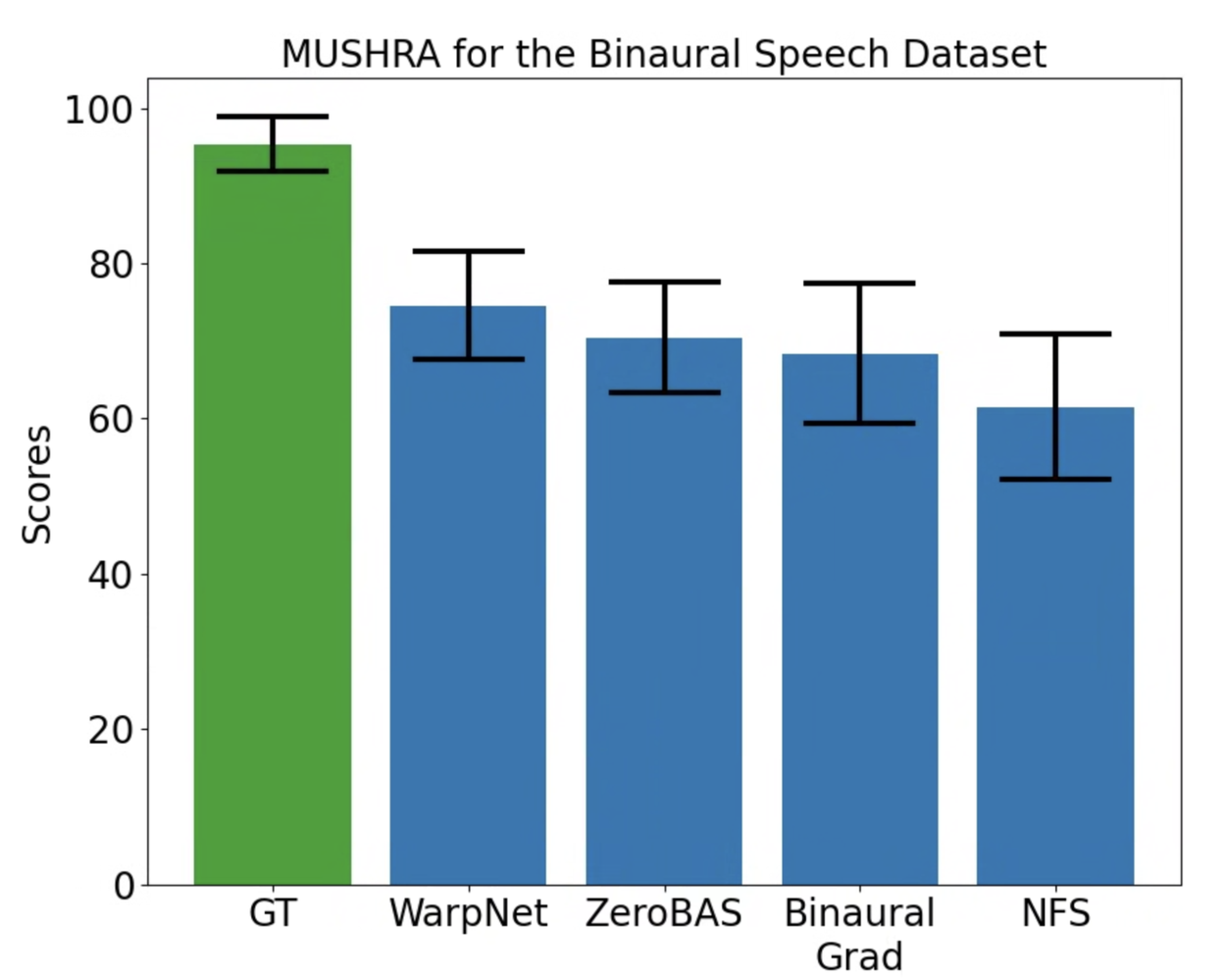
Multiple Stimuli with Hidden Reference and Anchor score (MUSHRA) results on the Binaural Speech dataset. Human raters are asked to rate how similar each model output is to the reference.
In the objective evaluation, we observe that ZeroBAS achieves significant objective improvements over the DSP baseline, despite not modeling additional interactions between the two generated channel streams or the room impulse response and head-related transfer function. Furthermore, the performance of the ZeroBAS method approaches that of the supervised methods, even though ZeroBAS has not been trained on the binaural speech dataset.
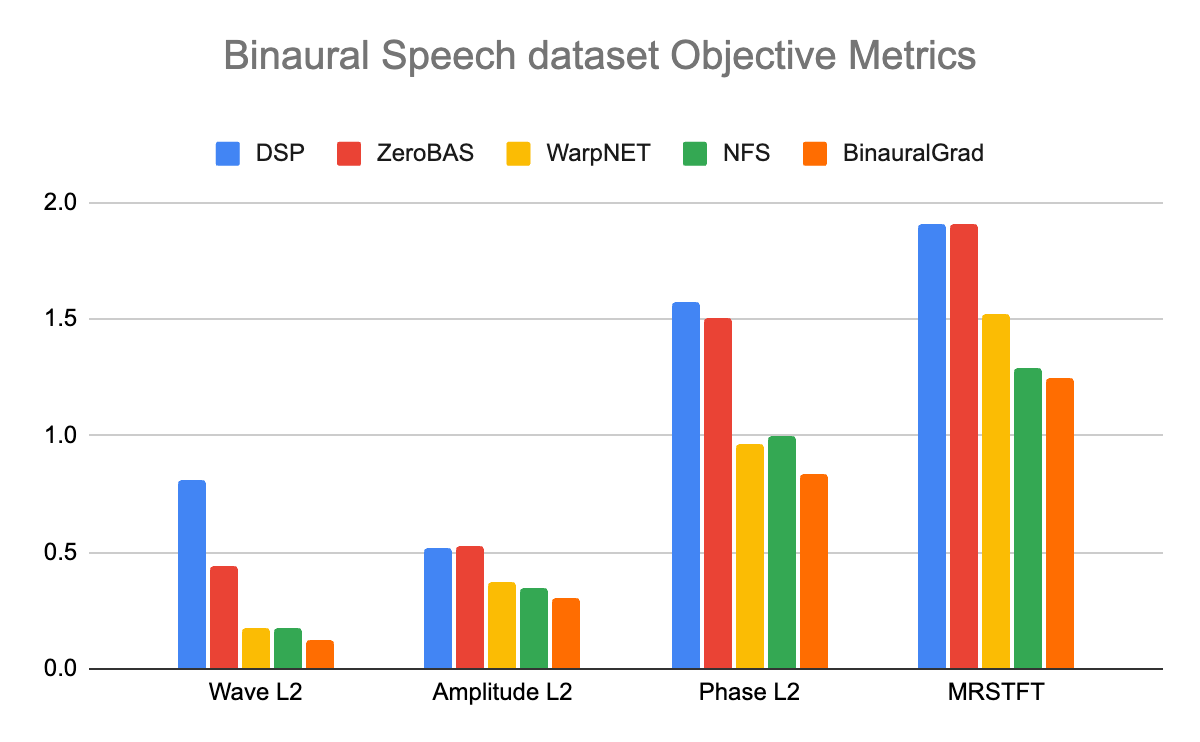
Objective metrics evaluating the similarity to the reference waveform on the Binaural Speech dataset, which include Wave L2, Amplitude L2, Phase L2 and MRSTFT.
TUT Mono-to-Binaural
Although the zero-shot method underperforms compared to supervised methods in the objective evaluation on the Binaural Speech dataset, we argue that the supervised methods are more sensitive to the room and recording conditions of that dataset. But in a real-world scenario, systems would be expected to perform well across a wide range of acoustic conditions, even ones on which they were not originally trained. To demonstrate that ZeroBAS fulfills this criteria, we evaluated all methods on our newly constructed TUT Mono-to-Binaural dataset.
The subjective evaluation further demonstrates that ZeroBAS exhibits better performance in terms of perceived naturalness compared to the supervised methods WarpNet, BinauralGrad, and NFS. As evidenced by the MOS, ZeroBAS surpasses these methods by notable margins. Furthermore, MUSHRA evaluations reveal a statistically significant preference for the proposed ZeroBAS method compared to supervised approaches. This suggests that human listeners perceive the spatial quality of binaural signals generated by ZeroBAS to best align with the reference.
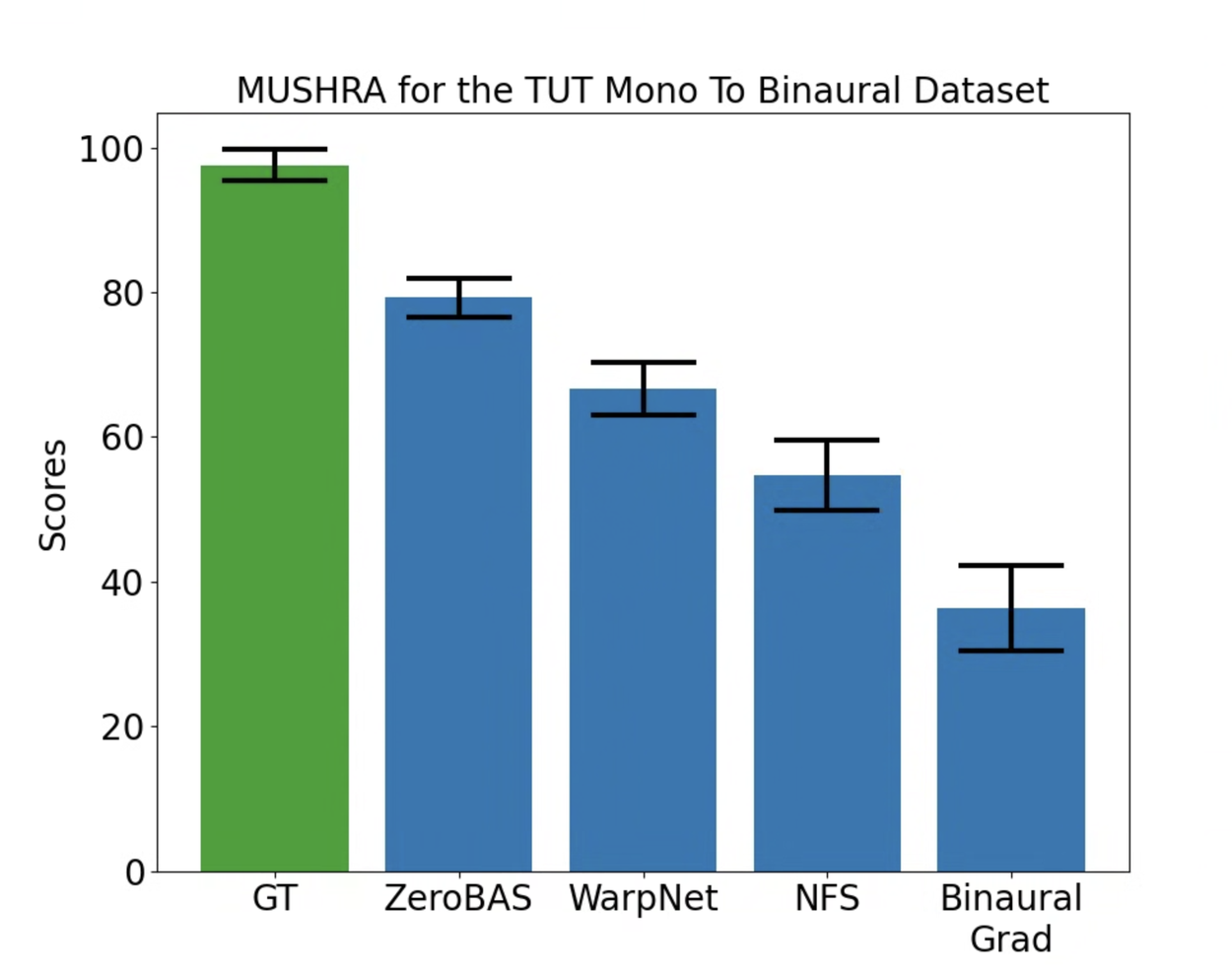
MUSHRA scores on the TUT Mono To Binaural dataset, where human raters are asked to rate how similar each model output is to the reference.
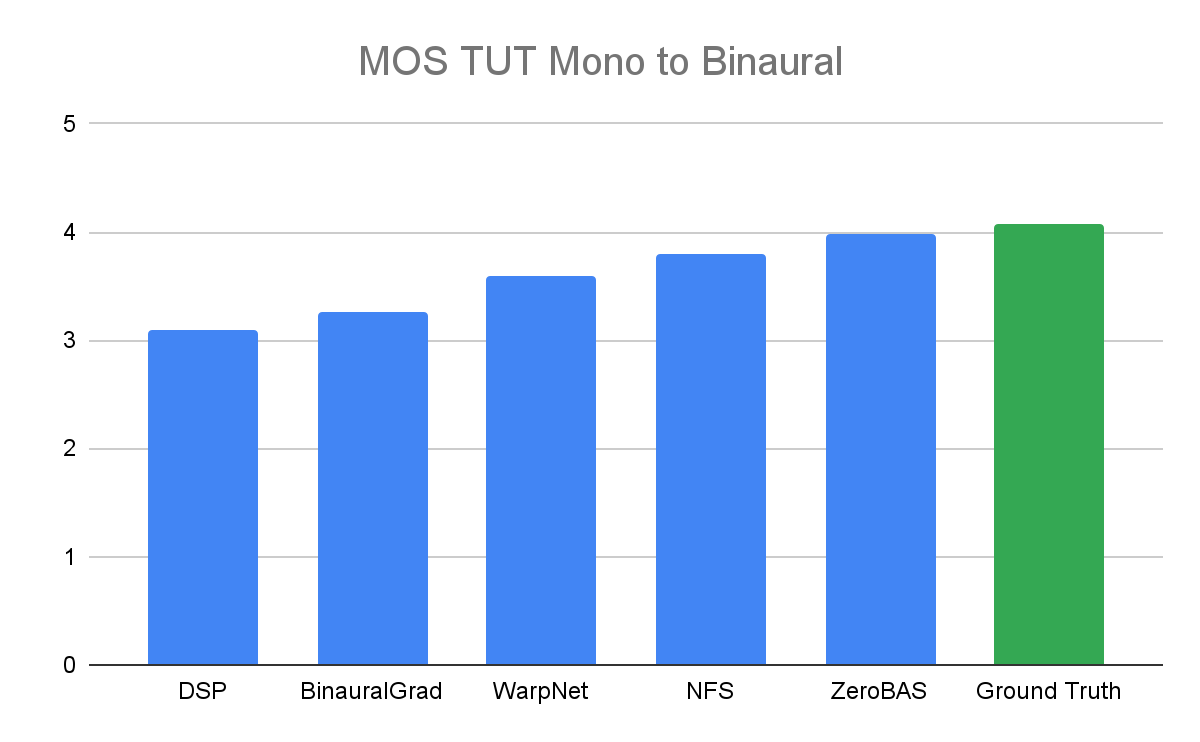
MOS on the TUT Mono to Binaural dataset computed by ratings from human evaluators.
Objective evaluation demonstrates that our zero-shot method, ZeroBAS, significantly outperforms all supervised methods on the TUT Mono-to-Binaural dataset. Yet, both ZeroBAS and the supervised methods struggle to capture accurate phase information, as evidenced by the Phase L2 metric, which indicates that there is still additional work to be done.
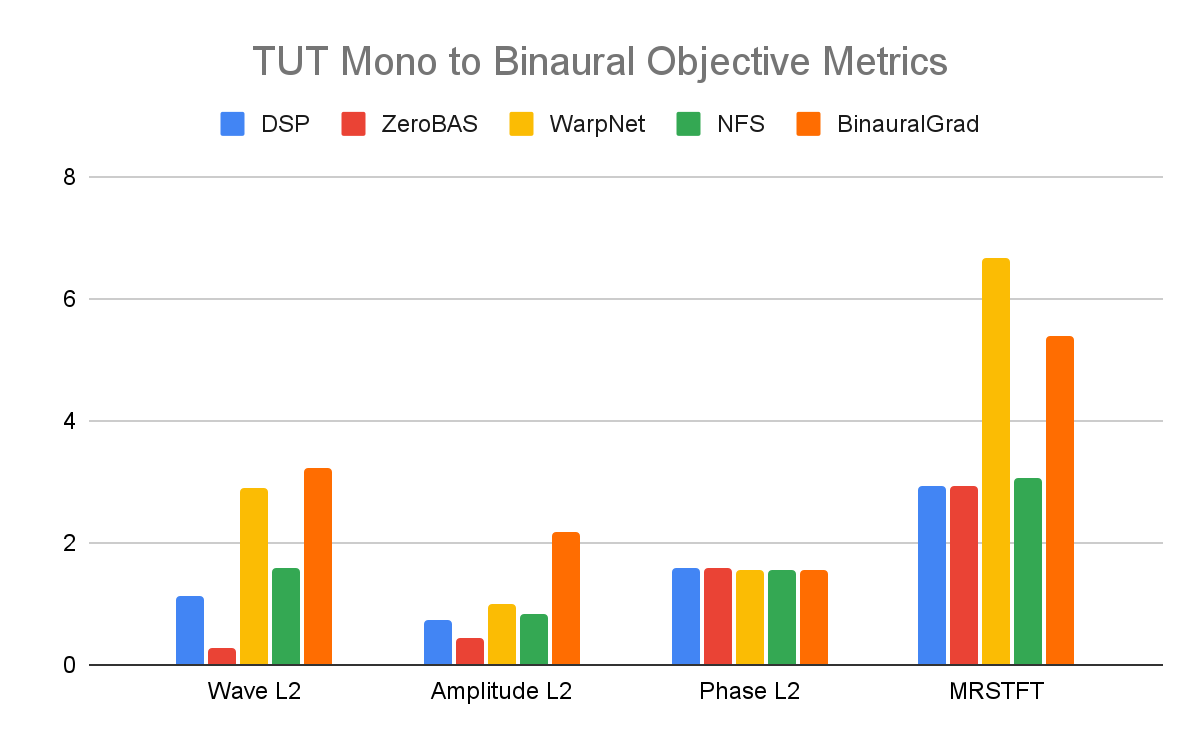
Objective metrics for the TUT Mono to Binaural dataset, which includes Wave L2, amplitude L2, Phase L2 and MRSTFT. These evaluate the similarity to the reference waveform.
Conclusion
In this work, we presented a room-agnostic zero-shot method for binaural speech synthesis from monaural audio. Our results demonstrate that the method achieves perceptual performance comparable to supervised approaches on their in-distribution datasets. Furthermore, we introduce a novel dataset specifically designed to evaluate the generalization capabilities of monaural-to-binaural synthesis methods for out-of-distribution scenarios.
Acknowledgements
The direct contributors to this work include Alon Levkovitch, Julian Salazar, Soroosh Mariooryad, RJ Skerry-Ryan, Nadav Bar, Bastiaan Kleijn and Eliya Nachmani. We also want to thank Heiga Zhen, Yuma Koizumi and Benny Schlesinger.
-
Labels:
- Sound & Accoustics
- Speech Processing
Quick links
Other posts of interest
-

February 9, 2026
How AI trained on birds is surfacing underwater mysteries- Climate & Sustainability ·
- Open Source Models & Datasets ·
- Sound & Accoustics
-

December 3, 2025
From Waveforms to Wisdom: The New Benchmark for Auditory Intelligence- Machine Intelligence ·
- Sound & Accoustics ·
- Speech Processing
-

October 7, 2025
Speech-to-Retrieval (S2R): A new approach to voice search- Machine Intelligence ·
- Natural Language Processing ·
- Product ·
- Speech Processing





