Video Understanding Using Temporal Cycle-Consistency Learning
August 8, 2019
Posted by Debidatta Dwibedi, Research Associate, Google Research
Quick links
In the last few years there has been great progress in the field of video understanding. For example, supervised learning and powerful deep learning models can be used to classify a number of possible actions in videos, summarizing the entire clip with a single label. However, there exist many scenarios in which we need more than just one label for the entire clip. For example, if a robot is pouring water into a cup, simply recognizing the action of “pouring a liquid” is insufficient to predict when the water will overflow. For that, it is necessary to track frame-by-frame the amount of water in the cup as it is being filled. Similarly, a baseball coach who is comparing stances of pitchers may want to retrieve video frames from the precise moment that the ball leaves the pitchers’ hands. Such applications require models to understand each frame of a video.
However, applying supervised learning to understand each individual frame in a video is expensive, since per-frame labels in videos of the action of interest are needed. This requires that annotators apply fine-grained labels to videos by manually adding unambiguous labels to every frame in each video. Only then can the model be trained, and only on a single action. Training on new actions requires the process to be repeated. With the increasing demand for fine-grained labeling, necessary for applications ranging from robotics to sports analytics, this makes the need for scalable learning algorithms that can understand videos without the tedious labeling process increasingly pertinent.
We propose a potential solution using a self-supervised learning method called Temporal Cycle-Consistency Learning (TCC). This novel approach uses correspondences between examples of similar sequential processes to learn representations particularly well-suited for fine-grained temporal understanding of videos. We are also releasing our TCC codebase to enable end-users to apply our self-supervised learning algorithm to new and novel applications.
Representation Learning Using TCC
A plant growing from a seedling to a tree; the daily routine of getting up, going to work and coming back home; or a person pouring themselves a glass of water are all examples of events that happen in a particular order. Videos capturing such processes provide temporal correspondences across multiple instances of the same process. For example, when pouring a drink one could be reaching for a teapot, a bottle of wine, or a glass of water to pour from. Key moments are common to all pouring videos (e.g., the first touch to the container or the container being lifted from the ground) and exist independent of many varying factors, such as visual changes in viewpoint, scale, container style, or the speed of the event. TCC attempts to find such correspondences across videos of the same action by leveraging the principle of cycle-consistency, which has been applied successfully in many problems in computer vision, to learn useful visual representations by aligning videos.
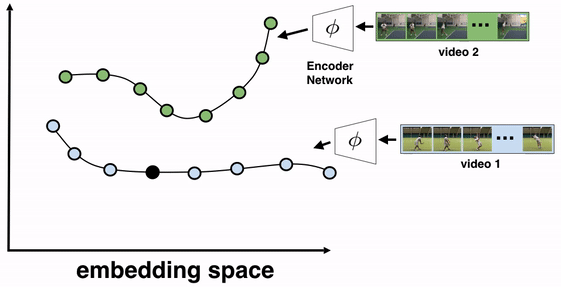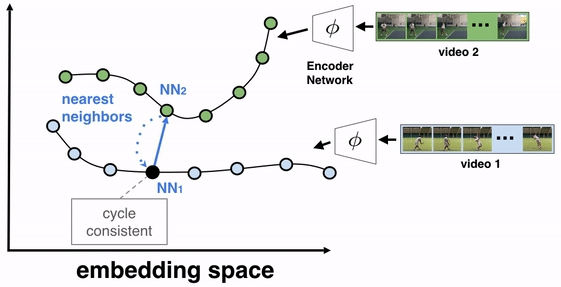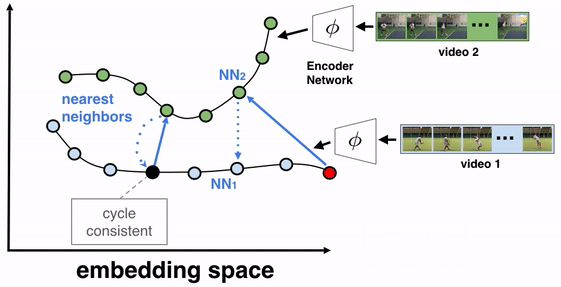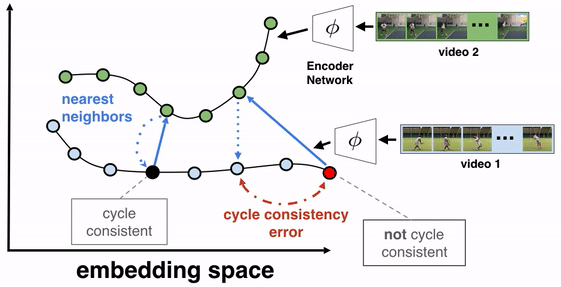
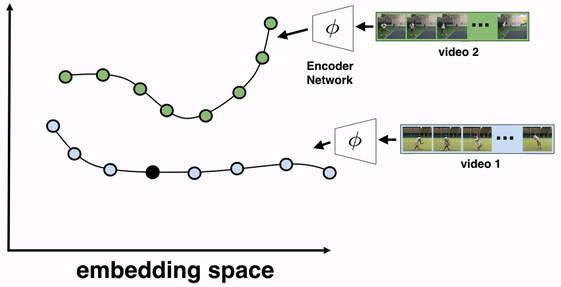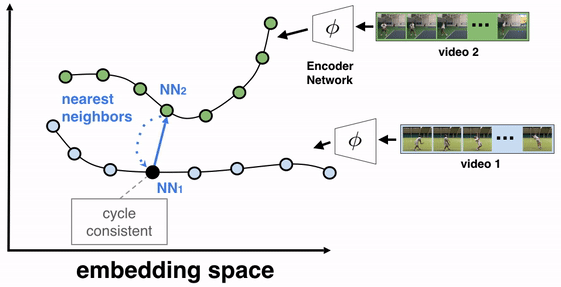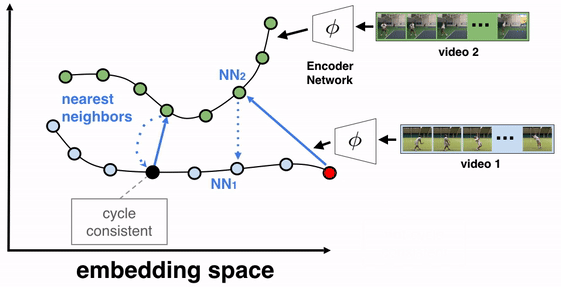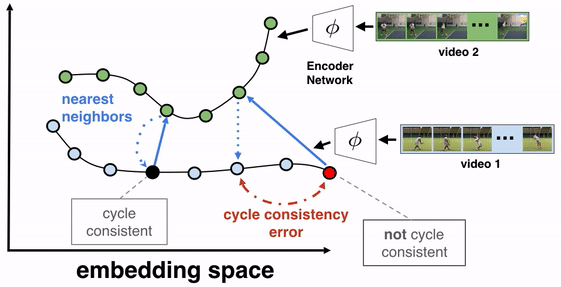
The objective of this training algorithm is to learn a frame encoder, using any network architecture that processes images, such as ResNet. To do so, we pass all frames of the videos to be aligned through the encoder to produce their corresponding embeddings. We then select two videos for TCC learning, say video 1 (the reference video) and video 2. A reference frame is chosen from video 1 and its nearest neighbor frame (NN2) from video 2 is found in the embedding space (not pixel space). We then cycle back by finding the nearest neighbor of NN2 in video 1, which we call NN1. If the representations are cycle-consistent, then the nearest neighbor frame in video 1 (NN1) should refer back to the starting reference frame.

 |
| Using TCC, we learn embeddings with temporally fine-grained understanding of an action by aligning related videos. |
In the following figure, we show a model trained using TCC on videos from the Penn Action Dataset of people performing squat exercises. Each point on the left corresponds to frame embeddings, with the highlighted points tracking the embedding of the current video frame. Notice how the embeddings move collectively in spite of many differences in pose, lighting, body and object type. TCC embeddings encode the different phases of squatting without being provided explicit labels.
 |
| Right: Input videos of people performing a squat exercise. The video on the top left is the reference. The other videos show nearest neighbor frames (in the TCC embedding space) from other videos of people doing squats. Left: The corresponding frame embeddings move as the action is performed. |
The learned per-frame embeddings enable an array of interesting applications:
- Few-shot action phase classification
When few labeled videos are available for training, the few-shot scenario, TCC performs very well. In fact, TCC can classify the phases of different actions with as few as a single labeled video. In the next figure we compare to other supervised and self-supervised learning approaches in the few-shot setting. We find that supervised learning requires about 50 videos with each frame labeled to achieve the same accuracy that self-supervised methods achieve with just one fully labeled video.

Comparison of self-supervised and supervised learning for few-shot action phase classification. - Unsupervised video alignment
Aligning or synchronizing videos manually becomes prohibitively difficult as the number of videos increases. Using TCC, many videos can be aligned by selecting the nearest neighbor to each frame in a reference video, without the need for additional labels, as demonstrated in the figure below.

Results of unsupervised video alignment on videos of people pitching baseball using the distance between frames in the TCC space. The reference video used for alignment is shown in the upper left panel. - Label/modality transfer between videos
Just as TCC finds similar frames by using a nearest neighbor search in the embedding space, it can transfer metadata associated with any frame in one video to its matching frame in another video. This metadata can be in the form of temporal semantic labels or other modalities, such as sound or text. In the video below we show two examples where we can transfer the sound of liquid being poured into a cup from one video to another.
- Per-frame Retrieval
With TCC, each frame in a video can be used as a query for retrieval of similar frames by looking up the nearest neighbors in the learned embedding space. The embeddings are powerful enough to differentiate between frames that look quite similar, such as frames just before or after the release of a bowling ball.

We can perform retrieval from videos on a per-frame basis, i.e., any frame can be used to look up similar frames in a large collection of videos. The retrieved nearest neighbors show that the model captures fine-grained differences in the scene.



We are releasing our codebase, which includes implementations of a number of state-of-the-art self-supervised learning methods, including TCC. This codebase will be useful for researchers working on video understanding, as well as artists looking to use machine learning to align videos to create mosaics of people, animals, and objects moving synchronously.
Acknowledgements
This is joint work with Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, and Andrew Zisserman. The authors would like to thank Alexandre Passos, Allen Lavoie, Anelia Angelova, Bryan Seybold, Priya Gupta, Relja Arandjelović, Sergio Guadarrama, Sourish Chaudhuri, and Vincent Vanhoucke for their help with this project. The videos used in this project come from the PennAction dataset. We thank the creators of PennAction for curating such an interesting dataset.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯