TRILLsson: Small, Universal Speech Representations for Paralinguistic Tasks
March 3, 2022
Posted by Joel Shor, Staff Software Engineer, Google Research
Quick links
In recent years, we have seen dramatic improvements on lexical tasks such as automatic speech recognition (ASR). However, machine systems still struggle to understand paralinguistic aspects — such as tone, emotion, whether a speaker is wearing a mask, etc. Understanding these aspects represents one of the remaining difficult problems in machine hearing. In addition, state-of-the-art results often come from ultra-large models trained on private data, making them impractical to run on mobile devices or to release publicly.
In “Universal Paralinguistic Speech Representations Using Self-Supervised Conformers”, to appear in ICASSP 2022, we introduce CAP12— the 12th layer of a 600M parameter model trained on the YT-U training dataset using self-supervision. We demonstrate that the CAP12 model outperforms nearly all previous results in our paralinguistic benchmark, sometimes by large margins, even though previous results are often task-specific. In “TRILLsson: Distilled Universal Paralinguistic Speech Representations'', we introduce the small, performant, publicly-available TRILLsson models and demonstrate how we reduced the size of the high-performing CAP12 model by 6x-100x while maintaining 90-96% of the performance. To create TRILLsson, we apply knowledge distillation on appropriately-sized audio chunks and use different architecture types to train smaller, faster networks that are small enough to run on mobile devices.
1M-Hour Dataset to Train Ultra-Large Self-Supervised Models
We leverage the YT-U training dataset to train the ultra-large, self-supervised CAP12 model. The YT-U dataset is a highly varied, 900M+ hour dataset that contains audio of various topics, background conditions, and speaker acoustic properties.
 |
| Video categories by length (outer) and number (inner), demonstrating the variety in the YT-U dataset (figure from BigSSL) |
We then modify a Wav2Vec 2.0 self-supervised training paradigm, which can solve tasks using raw data without labels, and combine it with ultra-large Conformer models. Because self-training doesn't require labels, we can take full advantage of YT-U by scaling up our models to some of the largest model sizes ever trained, including 600M, 1B, and 8B parameters.
NOSS: A Benchmark for Paralinguistic Tasks
We demonstrate that an intermediate representation of one of the previous models contains a state-of-the-art representation for paralinguistic speech. We call the 600M parameter Conformer model without relative attention Conformer Applied to Paralinguistics (CAP). We exhaustively search through all intermediate representations of six ultra-large models and find that layer 12 (CAP12) outperforms previous representations by significant margins.
To measure the quality of the roughly 300 candidate paralinguistic speech representations, we evaluate on an expanded version of the NOn-Semantic Speech (NOSS) benchmark, which is a collection of well-studied paralinguistic speech tasks, such as speech emotion recognition, language identification, and speaker identification. These tasks focus on paralinguistics aspects of speech, which require evaluating speech features on the order of 1 second or longer, rather than lexical features, which require 100ms or shorter. We then add to the benchmark a mask-wearing task introduced at Interspeech 2020, a fake speech detection task (ASVSpoof 2019), a task to detect the level of dysarthria from project Euphonia, and an additional speech emotion recognition task (IEMOCAP). By expanding the benchmark and increasing the diversity of the tasks, we empirically demonstrate that CAP12 is even more generally useful than previous representations.
Simple linear models on time-averaged CAP12 representations even outperform complex, task-specific models on five out of eight paralinguistic tasks. This is surprising because comparable models sometimes use additional modalities (e.g., vision and speech, or text and speech) as well. Furthermore, CAP12 is exceptionally good at emotion recognition tasks. CAP12 embeddings also outperform all other embeddings on all other tasks with only a single exception: for one embedding from a supervised network on the dysarthria detection task.
| Model | Voxceleb† | Voxforge | Speech Commands | ASVSpoof2019∗∗ | Euphonia# | CREMA-D | IEMOCAP |
| Prev SoTA | - | 95.4 | 97.9 | 5.11 | 45.9 | 74.0∗ | 67.6+ |
| TRILL | 12.6 | 84.5 | 77.6 | 74.6 | 48.1 | 65.7 | 54.3 |
| ASR Embedding | 5.2 | 98.9 | 96.1 | 11.2 | 54.5 | 71.8 | 65.4 |
| Wav2Vec2 layer 6†† | 17.9 | 98.5 | 95.0 | 6.7 | 48.2 | 77.4 | 65.8 |
| CAP12 | 51.0 | 99.7 | 97.0 | 2.5 | 51.5 | 88.2 | 75.0 |
| Test performance on the NOSS Benchmark and extended tasks. “Prev SoTA” indicates the previous best performing state-of-the-art model, which has arbitrary complexity, but all other rows are linear models on time-averaged input. † Filtered according to YouTube’s privacy guidelines. ∗∗ Uses equal error rate [20]. # The only non-public dataset. We exclude it from aggregate scores. ∗ Audio and visual features used in previous state-of-the-art models. + The previous state-of-the-art model performed cross-validation. For our evaluation, we hold out two specific speakers as a test. †† Wav2Vec 2.0 model from HuggingFace. Best overall layer was layer 6. |
TRILLsson: Small, High Quality, Publicly Available Models
Similar to FRILL, our next step was to make an on-device, publicly available version of CAP12. This involved using knowledge distillation to train smaller, faster, mobile-friendly architectures. We experimented with EfficientNet, Audio Spectrogram Transformer (AST), and ResNet. These model types are very different, and cover both fixed-length and arbitrary-length inputs. EfficientNet comes from a neural architecture search over vision models to find simultaneously performant and efficient model structures. AST models are transformers adapted to audio inputs. ResNet is a standard architecture that has shown good performance across many different models.
We trained models that performed on average 90-96% as well as CAP12, despite being 1%-15% the size and trained using only 6% the data. Interestingly, we found that different architecture types performed better at different sizes. ResNet models performed best at the low end, EfficientNet in the middle, and AST models at the larger end.
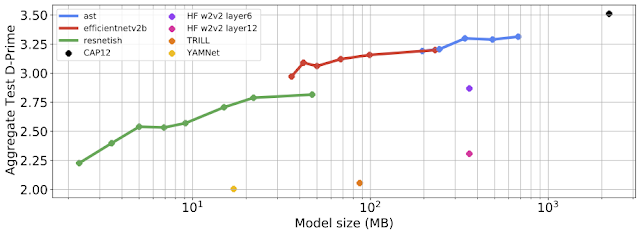 |
| Aggregate embedding performance vs. model size for various student model architectures and sizes. We demonstrate that ResNet architectures perform best for small sizes, EfficientNetV2 performs best in the midsize model range, up to the largest model size tested, after which the larger AST models are best. |
We perform knowledge distillation with the goal of matching a student, with a fixed-size input, to the output of a teacher, with a variable-size input, for which there are two methods of generating student targets: global matching and local matching. Global matching produces distillation targets by generating CAP12 embeddings for an entire audio clip, and then requires that a student match the target from just a small segment of audio (e.g., 2 seconds). Local matching requires that the student network match the average CAP12 embedding just over the smaller portion of the audio that the student sees. In our work, we focused on local matching.
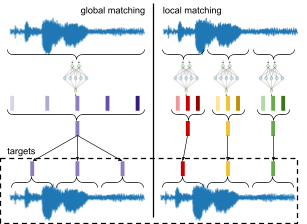 |
| Two types of generating distillation targets for sequences. Left: Global matching uses the average CAP12 embedding over the whole clip for the target for each local chunk. Right: Local matching uses CAP12 embeddings averaged just over local clips as the distillation target. |
Observation of Bimodality and Future Directions
Paralinguistic information shows an unexpected bimodal distribution. For the CAP model that operates on 500 ms input segments, and two of the full-input Conformer models, intermediate representations gradually increase in paralinguistic information, then decrease, then increase again, and finally lose this information towards the output layer. Surprisingly, this pattern is also seen when exploring the intermediate representations of networks trained on retinal images.
 |
| 500 ms inputs to CAP show a relatively pronounced bimodal distribution of paralinguistic information across layers. |
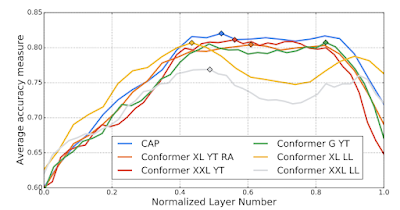 |
| Two of the conformer models with full inputs show a bimodal distribution of paralinguistic information across layers. |
We hope that smaller, faster models for paralinguistic speech unlock new applications in speech recognition, text-to-speech generation, and understanding user intent. We also expect that smaller models will be more easily interpretable, which will allow researchers to understand what aspects of speech are important for paralinguistics. Finally, we hope that our open-sourced speech representations are used by the community to improve paralinguistic speech tasks and user understanding in private or small datasets.
Acknowledgements
I'd like to thank my co-authors Aren Jansen, Wei Han, Daniel Park, Yu Zhang, and Subhashini Venugopalan for their hard work and creativity on this project. I'd also like to thank the members of the large collaboration for the BigSSL work, without which these projects would not be possible. The team includes James Qin, Anmol Gulati, Yuanzhong Xu, Yanping Huang, Shibo Wang, Zongwei Zhou, Bo Li, Min Ma, William Chan, Jiahui Yu, Yongqiang Wang, Liangliang Cao, Khe Chai Sim, Bhuvana Ramabhadran, Tara N. Sainath, Françoise Beaufays, Zhifeng Chen, Quoc V. Le, Chung-Cheng Chiu, Ruoming Pang, and Yonghui Wu.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence