Towards a science of scaling agent systems: When and why agent systems work
January 28, 2026
Yubin Kim, Research Intern, and Xin Liu, Senior Research Scientist, Google Research
Through a controlled evaluation of 180 agent configurations, we derive the first quantitative scaling principles for AI agent systems, revealing that multi-agent coordination dramatically improves performance on parallelizable tasks but degrades it on sequential ones; we also introduce a predictive model that identifies the optimal architecture for 87% of unseen tasks.
Quick links
AI agents — systems capable of reasoning, planning, and acting — are becoming a common paradigm for real-world AI applications. From coding assistants to personal health coaches, the industry is shifting from single-shot question answering to sustained, multi-step interactions. While researchers have long utilized established metrics to optimize the accuracy of traditional machine learning models, agents introduce a new layer of complexity. Unlike isolated predictions, agents must navigate sustained, multi-step interactions where a single error can cascade throughout a workflow. This shift compels us to look beyond standard accuracy and ask: How do we actually design these systems for optimal performance?
Practitioners often rely on heuristics, such as the assumption that "more agents are better", believing that adding specialized agents will consistently improve results. For example, "More Agents Is All You Need" reported that LLM performance scales with agent count, while collaborative scaling research found that multi-agent collaboration "...often surpasses each individual through collective reasoning."
In our new paper, “Towards a Science of Scaling Agent Systems”, we challenge this assumption. Through a large-scale controlled evaluation of 180 agent configurations, we derive the first quantitative scaling principles for agent systems, revealing that the "more agents" approach often hits a ceiling, and can even degrade performance if not aligned with the specific properties of the task.
Defining "agentic" evaluation
To understand how agents scale, we first defined what makes a task "agentic". Traditional static benchmarks measure a model's knowledge, but they don't capture the complexities of deployment. We argue that agentic tasks require three specific properties:
- Sustained multi-step interactions with an external environment.
- Iterative information gathering under partial observability.
- Adaptive strategy refinement based on environmental feedback.
We evaluated five canonical architectures: one single-agent system (SAS) and four multi-agent variants (independent, centralized, decentralized, and hybrid) across four diverse benchmarks, including Finance-Agent (financial reasoning), BrowseComp-Plus (web navigation), PlanCraft (planning), and Workbench (tool use). The agent architectures are defined as follow:
- Single-Agent (SAS): A solitary agent executing all reasoning and acting steps sequentially with a unified memory stream.
- Independent: Multiple agents working in parallel on sub-tasks without communicating, aggregating results only at the end.
- Centralized: A "hub-and-spoke" model where a central orchestrator delegates tasks to workers and synthesizes their outputs.
- Decentralized: A peer-to-peer mesh where agents communicate directly with one another to share information and reach consensus.
- Hybrid: A combination of hierarchical oversight and peer-to-peer coordination to balance central control with flexible execution.
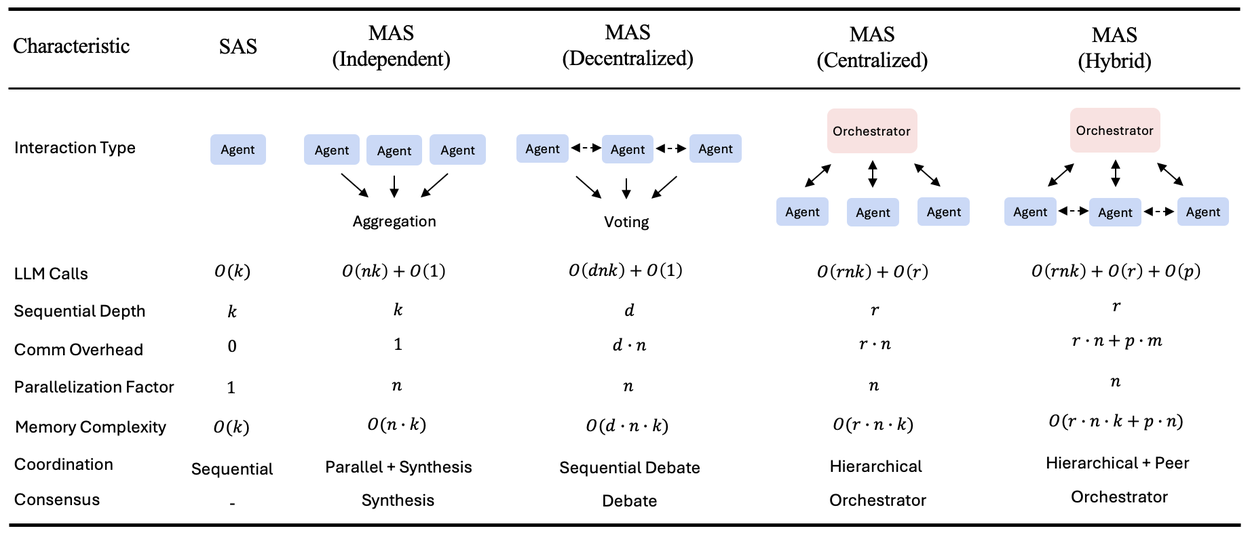
Summary of the five canonical agent architectures evaluated in this study, including their computational complexity, communication overhead, and coordination mechanisms. k = max iterations per agent, n = number of agents, r = orchestrator rounds, d = debate rounds, p = peer communication rounds, m = average peer requests per round. Communication overhead counts inter-agent message exchanges. Independent offers maximal parallelization with minimal coordination. Decentralized uses sequential debate rounds. Hybrid combined orchestrator control with directed peer communication.
Results: The myth of "more agents"
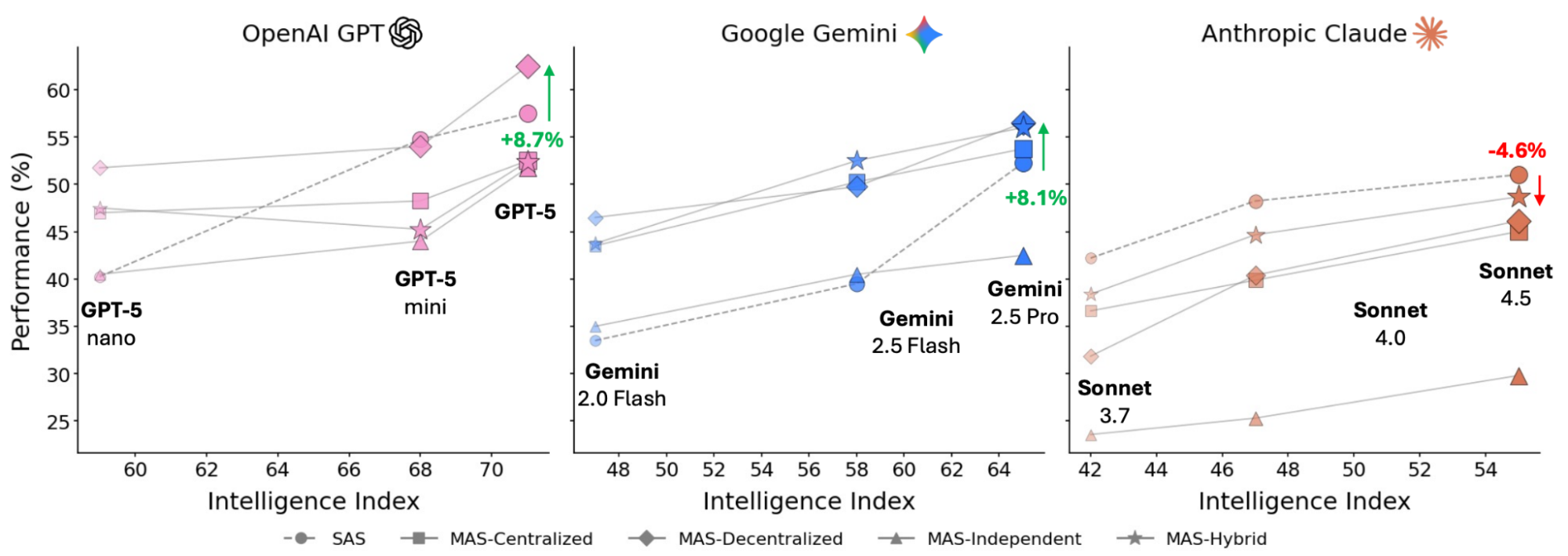
To quantify the impact of model capabilities on agent performance, we evaluated our architectures across three leading model families: OpenAI GPT, Google Gemini, and Anthropic Claude. The results reveal a complex relationship between model capabilities and coordination strategy. As shown in the figure below, while performance generally trends upward with more capable models, multi-agent systems are not a universal solution — they can either significantly boost or unexpectedly degrade performance depending on the specific configuration.
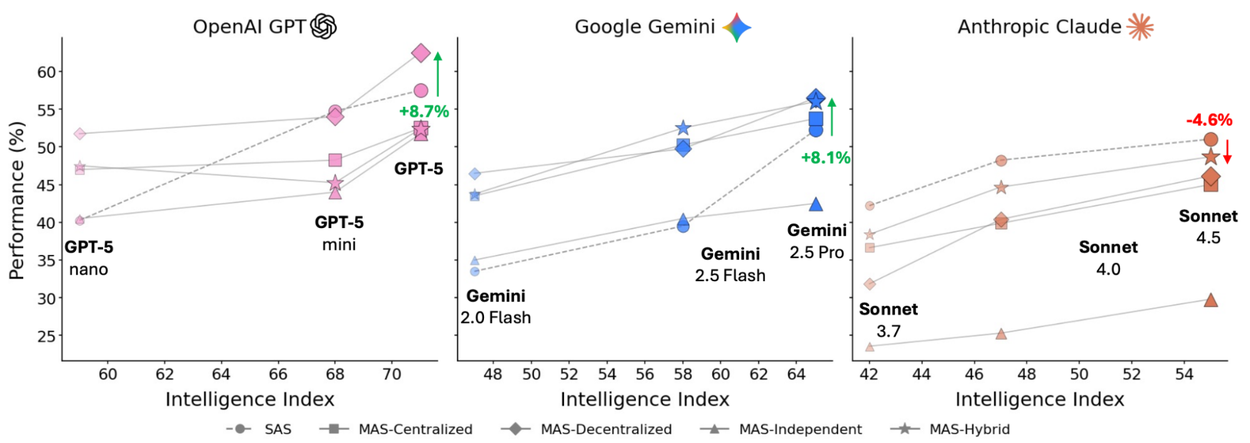
Performance comparison across three major model families (OpenAI GPT, Google Gemini, Anthropic Claude) showing how different agent architectures scale with model intelligence, where multi-agent systems can either boost or degrade performance depending on the configuration.
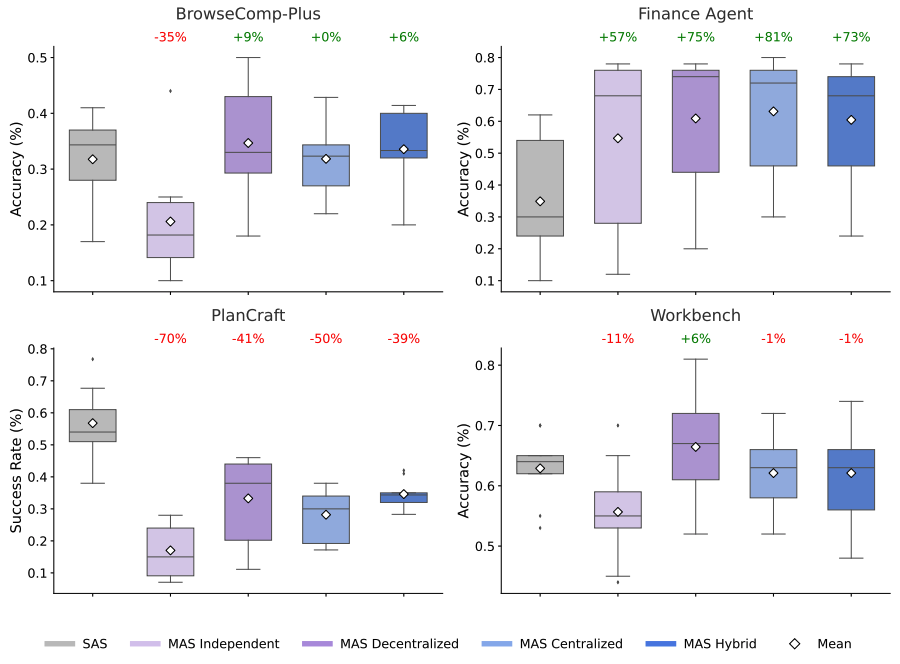
The results below compare the performance of the five architectures across different domains, such as web browsing and financial analysis. The box plots represent the accuracy distribution for each approach, while the percentages indicate the relative improvement (or decline) of multi-agent teams compared to the single-agent baseline. This data highlights that while adding agents can drive massive gains in parallelizable tasks, it can often lead to diminishing returns — or even performance drops — in more sequential workflows.
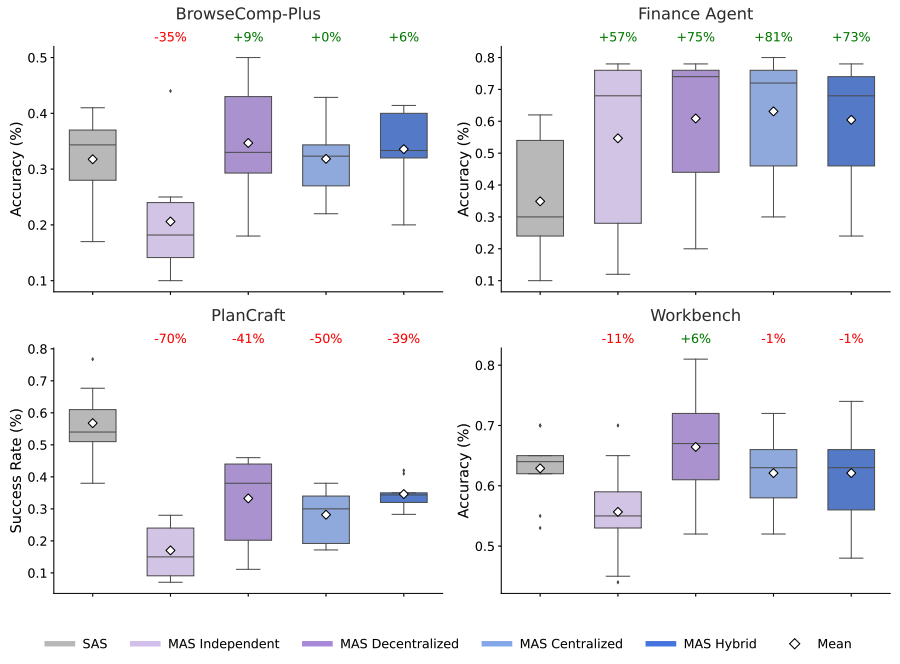
Task-specific performance showing that multi-agent coordination yields substantial gains on parallelizable tasks like Finance-Agent (+81%) while degrading performance on sequential tasks like PlanCraft (-70%).
The alignment principle
On parallelizable tasks like financial reasoning (e.g., distinct agents can simultaneously analyze revenue trends, cost structures, and market comparisons), centralized coordination improved performance by 80.9% over a single agent. The ability to decompose complex problems into sub-tasks allowed agents to work more effectively.
The sequential penalty
Conversely, on tasks requiring strict sequential reasoning (like planning in PlanCraft), every multi-agent variant we tested degraded performance by 39-70%. In these scenarios, the overhead of communication fragmented the reasoning process, leaving insufficient "cognitive budget" for the actual task.
The tool-use bottleneck
We identified a "tool-coordination trade-off". As tasks require more tools (e.g., a coding agent with access to 16+ tools), the "tax" of coordinating multiple agents increases disproportionately.
Architecture as a safety feature
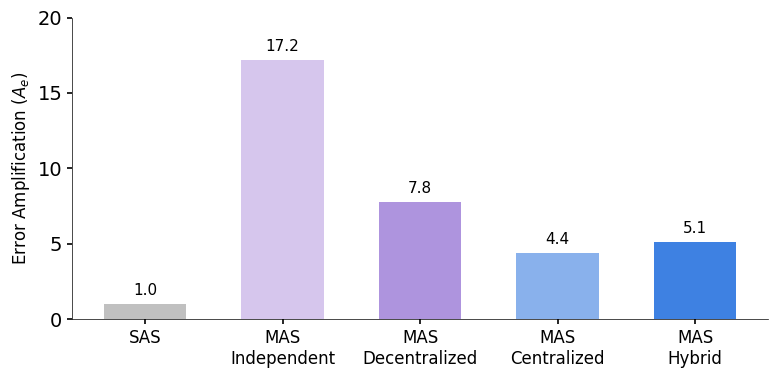
Perhaps most important for real-world deployment, we found a relationship between architecture and reliability. We measured error amplification, the rate at which a mistake by one agent propagates to the final result.
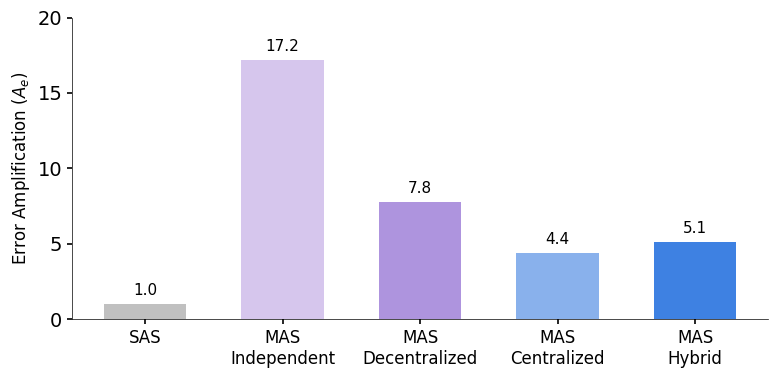
Comprehensive metrics across architectures reveal that centralized systems achieve the best balance between success rate and error containment, while independent multi-agent systems amplify errors by up to 17.2x.
We found that independent multi-agent systems (agents working in parallel without talking) amplified errors by 17.2x. Without a mechanism to check each other's work, errors cascaded unchecked. Centralized systems (with an orchestrator) contained this amplification to just 4.4x. The orchestrator effectively acts as a "validation bottleneck", catching errors before they propagate.
A predictive model for agent design
Moving beyond retrospection, we developed a predictive model (R^2 = 0.513) that uses measurable task properties like tool count and decomposability to predict which architecture will perform best. This model correctly identifies the optimal coordination strategy for 87% of unseen task configurations.
This suggests we are moving toward a new science of agent scaling. Instead of guessing whether to use a swarm of agents or a single powerful model, developers can now look at the properties of their task, specifically its sequential dependencies and tool density, to make principled engineering decisions.
Conclusion
As foundational models like Gemini continue to advance, our research suggests that smarter models don't replace the need for multi-agent systems, they accelerate it, but only when the architecture is right. By moving from heuristics to quantitative principles, we can build the next generation of AI agents that are not just more numerous, but smarter, safer, and more efficient.
Acknowledgements
We would like to thank our co-authors and collaborators from Google Research, Google DeepMind, and academia for their contributions to this work.
-
Labels:
- Generative AI
- Machine Intelligence
Quick links
Other posts of interest
-

June 16, 2026
From pixels to planning: Earth AI for nature restoration- Climate & Sustainability ·
- Earth AI ·
- Machine Intelligence ·
- Open Source Models & Datasets
-

June 5, 2026
Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG- Data Management ·
- Machine Intelligence ·
- Natural Language Processing ·
- Product
-

June 4, 2026
Towards passive heart health monitoring via smartphone camera- Health & Bioscience ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence