The Importance of A/B Testing in Robotics
June 10, 2021
Arnab Bose and Yuheng Kuang, Staff Software Engineers, Robotics at Google
Quick links
Disciplines in the natural sciences, social sciences, and medicine all have to grapple with how to evaluate and compare results within the context of the continually changing real world. In contrast, a significant body of machine learning (ML) research uses a different method that relies on the assumption of a fixed world: measure the performance of a baseline model on fixed data sets, then build a new model aimed at improving on the baseline, and evaluate its performance (on the same fixed data) by comparing its performance to the baseline.
Research into robotics systems and their applications to the real world requires a rethinking of this experiment design. Even in controlled robotic lab environments, it is possible that real-world changes cause the baseline model to perform inconsistently over time, making it unclear whether new models’ performance is an improvement compared to the baseline, or just the result of unintentional, random changes in the experiment setup. As robotics research advances into more complex and challenging real-world scenarios, there is a growing need for both understanding the impact of the ever-changing world on baselines and developing systematic methods to generate informative and clear results.
In this post, we demonstrate how robotics research, even in the relatively controlled environment of a lab, is meaningfully affected by changes in the environment, and discuss how to address this fundamental challenge using random assignment and A/B testing. Although these are classical research methods, they are not generally employed by default in robotics research — yet, they are critical to producing meaningful and measurable scientific results for robotics in real-world scenarios. Additionally, we cover the costs, benefits, and other considerations of using these methods.
The Ever-Changing Real World in Robotics
Even in a robotics lab environment, which is designed to minimize all changes that are not experimental conditions, it is notoriously difficult to set up a perfectly reproducible experiment. Robots get bumped and are subject to wear and tear, lighting changes affect perception, battery charge influences the torque applied to motors — all things that can affect results in ways large and small.
To illustrate this on real robot data, we collected success rate data on one of our simplest setups — moving identical foam dice from one bin to another. For this task, we ran about 33k task trials on two robots over more than five months with the same software and ML model, and took the overall success rate of the last two weeks as baseline. We then measured the historic performance over time in this “very well controlled” environment.
 |
| Video of a real robot completing the task: moving identical foam dice from one bin to another. |
Given that we did not purposefully change anything during data collection, one would expect the success rate to be statistically similar over time. And yet, this is not what was observed.
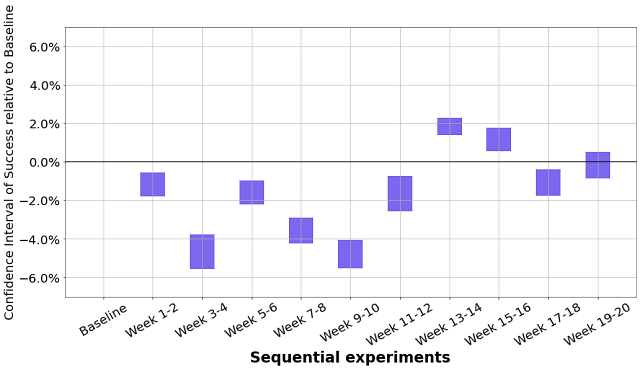
 |
| The y-axis represents the 95% confidence interval of % change in success rate relative to baseline. If the confidence intervals contain zero, that indicates the success rate is statistically similar to the success rate of baseline. Confidence intervals were computed using Jackknife, with Cochran-Mantel-Haenszel correction to remove operator bias. |
Using the sequential data from the plot above, one might conclude that the model ran during weeks 13-14 performed best and that ran during weeks 9-10 performed the worst. One might also expect most, if not all, of the confidence intervals above to contain 0, but only one did. Because no changes were made at any time during these trials, this example effectively demonstrates the impact of unintentional, random real-world changes on even very simple setups. It’s also worth noting that having more trials per experiment wouldn’t remove these differences, instead they will more likely produce a narrower confidence interval making the impact more obvious.
However, what happens when one uses random assignment to compare results, grouping the data randomly rather than sequentially? To answer this, we randomly assigned the above data to the same number of groups for comparison with the baseline. This is equivalent to performing A/B testing where all groups receive the same treatment.
 |
Looking at the chart, we observe that the confidence intervals include zero, indicating success similar to the baseline, as expected.
We performed similar studies with a few other robotics tasks, comparing between sequential and random assignments. They all yielded similar results.
 |
We see that even with no intentional changes, there are statistically significant differences observed for sequential assignment, while random assignment shows the expected result of no statistically significant differences.
Considerations for A/B Testing in Robotics
While it’s clear based on the above that A/B testing with random assignment is an effective way to control for the unexplainable variance of the real world in robotics, there are some considerations when adopting this approach. Here are several, along with their accompanying pros, cons, and solutions:
- Absolute vs relative performance: Each experiment needs to be measured against a baseline that is run concurrently. The relative performance metric between baseline and experiment is published with a confidence interval. The absolute performance metric (in baseline or experiment) is less informative, because it depends to an unknown degree on the state of the world when the measurement was taken. However, the statistical differences we’ve measured between the experiment and baseline are sound and robust to reproduction.
- Data efficiency: With this approach, the baseline always needs to run in parallel with the experimental conditions so they can be compared against each other. Although this may seem wasteful, it is worth the cost when compared against the drawbacks of making an invalid inference against a stale baseline. Furthermore, as the number of random assignment experiments scale up, we can use a single baseline arm with multiple simultaneous experiment arms across independent factors leveraging Google’s overlapping experiment infrastructure. Data efficiency improves with scale.
- Environmental biases: If there’s any external factor affecting performance overall (lighting, slicker surfaces, etc.), both the baseline and all experiment arms will encounter this factor with similar probability, so its effect will cancel if there’s no relative impact. If there is a correlation between environmental factors and experiment arms, this will show up as differences over time (each environmental factor accumulates in the episodes collected). This can substantially reduce or eliminate the need for effortful environmental resets, and lets us run lifelong experiments and still measure improvements across experimental arms.
- Human biases: One advantage of random assignment is a reduction in biases introduced by humans. Since human operators cannot know which data sample gets routed to which arm of the experiment, it is harder to have biased experimenters influence any particular outcome.
The Path Forward
The A/B testing experiment framework has been successfully used for a long time in many scientific disciplines to measure performance against changing, unpredictable real-world environments. In this blog post, we show that robotics research can benefit from using this same methodology: it improves the quality and confidence of research results, and avoids the impossible task of perfectly controlling all elements of a fundamentally changing environment. Doing this well requires infrastructure to continuously operate robots, collect data, and tools to make the statistical framework easily accessible to researchers.
Acknowledgements
Arnab Bose, Tuna Toksoz, Yuheng Kuang, Anthony Brohan, Razvan Sudulescu developed the experiment infrastructure and conducted the research. Matthieu Devin suggested the A/A analysis to showcase the differences using existing data. Special thanks to Bill Heavlin, Chris Harris, Vincent Vanhoucke who provided invaluable feedback and support to the work.
-
Labels:
- Algorithms & Theory
- Robotics
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence