Scaling wearable foundation models
November 20, 2024
Daniel McDuff, Staff Research Scientist, and Xin Liu, Senior Research Scientist, Google Health
Inspired by empirical successes in generative modeling, where large neural networks learn powerful representations from unstructured and noisy data, we demonstrate the scaling properties of this model for consumer health data, highlighting how these models enable sample-efficient downstream learning for tasks like exercise and activity recognition.
Quick links
Wearable devices that measure physiological and behavioral signals have become commonplace. There is growing evidence that these devices can have a meaningful impact promoting healthy behaviors, detecting diseases, and improving the design and implementation of treatments. These devices generate vast amounts of continuous, longitudinal, and multimodal data. However, raw data from signals like electrodermal activity or accelerometer values are difficult for consumers and experts to interpret. To address this challenge, algorithms have been developed to convert sensor outputs into more meaningful representations.
Historically, algorithms for wearable sensors have relied on supervised, discriminative models (i.e., a class of models often used for classification) designed to detect specific events or activities (e.g., recognizing whether a user is running). This approach, however, faces several significant limitations. First, the limited volume and severe class imbalance of the labeled events means that there are large amounts of potentially valuable unlabeled data left unused. Second, supervised models are trained to do only one task (e.g., classification) and thus create representations that may not generalize to other tasks. Third, there can be limited heterogeneity in the training data since it is frequently collected from small study populations (usually tens or hundreds of participants).
Self-supervised learning (SSL) using generic pretext tasks (e.g., rearranging image patches akin to solving a jigsaw puzzle or filling in missing parts of an image) can yield versatile representations that are useful for multiple types of downstream applications. SSL can be used to leverage a much larger proportion of the data available, without bias to labeled data regions (e.g., a limited number of subjects with self-reported labels of exercise segments). These benefits have inspired efforts to apply similar training strategies to create models with large volumes of unlabeled data from wearable devices.
Building on this, the empirical and theoretical success of scaling laws in neural models indicates that model performance improves predictably with increases in data, compute, and parameters. These results prompt a critical question: Do scaling laws apply to models trained on wearable sensor data? The answer to this question is not immediately obvious, as the sensor inputs capture information that is quite different from language, video or audio. Understanding how scaling manifests in this domain could not only shape model design but also enhance generalization across diverse tasks and datasets.
In “Scaling Wearable Foundation Models”, we investigate whether the principles driving the scaling of neural networks in domains like text and image data also extend to large-scale, multimodal wearable sensor data. We present the results of our scaling experiments on the largest wearable dataset published to date, consisting of over 40 million hours of de-identified multimodal sensor data from 165,000 users. We leverage this dataset to train a foundation model, which we refer to as the Large Sensor Model (LSM). We demonstrate the scaling properties of this dataset and model with respect to data, compute, and model parameters, showing performance gains of up to 38% over traditional imputation methods.
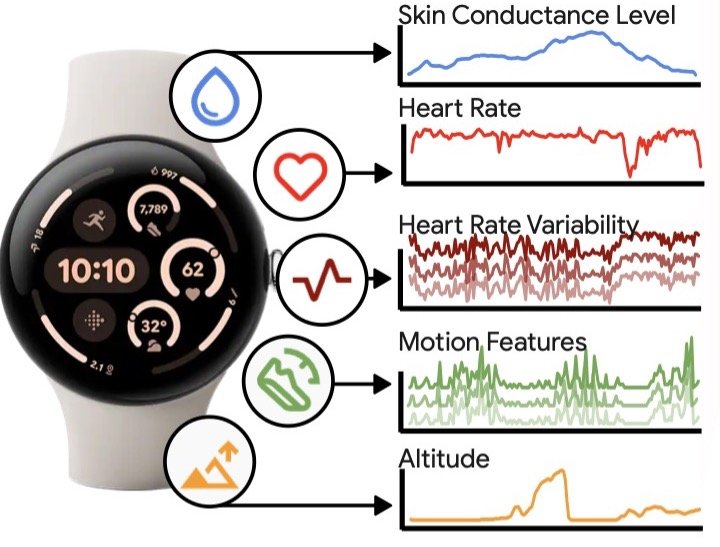
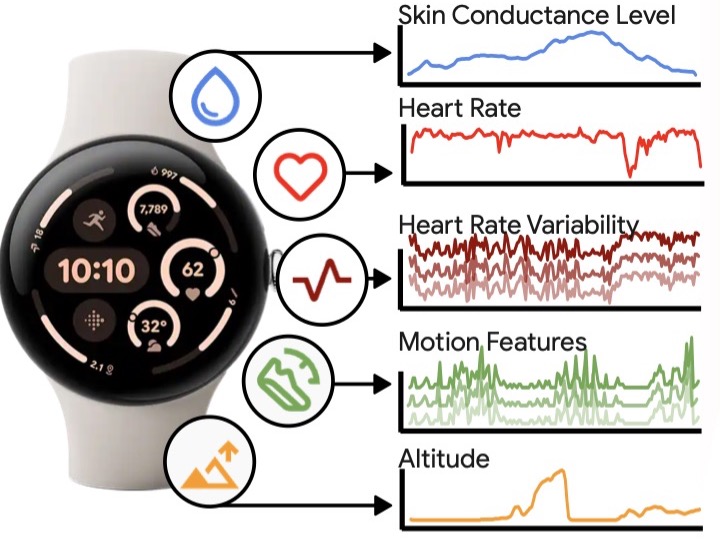
Wearable devices sense an array of physiological and behavioral signals — making sense of these can be challenging.
Training the model
We sampled wearable data from 165,090 participants during the period from January 2023 to July 2024. The subjects wore Fitbit Sense 2 or Google Pixel Watch 2 devices and consented for their data to be used for research and development of new health and wellness products and services. We sub-selected from people wearing these devices to ensure that we had as many signals as possible. The subjects were asked for self-reported sex, age, weight and US state where they reside. The data was de-identified and not linked with any other information. To create a dataset that maximized the number of subjects, we randomly sampled 10 5-hour windows of data from each subject.
To train LSM, we employ a masking approach where certain portions of the wearable data are intentionally and randomly hidden, or "masked," and the model learns to reconstruct or impute (fill in or complete) these missing patches. Illustrated below, this technique encourages the model to understand underlying patterns in the data, enhancing its ability to interpret signals across different sensor types. The intention is that applying this masking task in the training of wearable sensor models may not only result in learned representations that are useful for downstream classification tasks, but also produce models that can impute missing or incomplete data (i.e., ability to interpolate) and forecast future sensor values (i.e., ability to extrapolate).

An overview of generative LSM tasks. We define a pre-training and four distinct generative evaluation tasks: random imputation, temporal interpolation, signal/sensor imputation, and temporal extrapolation (forecasting). We also evaluate the model on downstream exercise and activity classification.
Activity recognition is the process of classifying different user activities, such as biking, running, or walking, based on the patterns detected in sensor data. This allows wearable devices to monitor daily routines accurately, providing insights into fitness levels, activity trends, and overall health. Effective activity recognition enables applications like fitness tracking, lifestyle monitoring, and personalized coaching. In addition to recognized activities, our dataset includes eight user-labeled activities: biking, elliptical, high-intensity interval training (HIIT), strength training, swimming, running, walking, and weightlifting.
Results of scaling laws for wearable data
Given the scale of the dataset, we perform experiments to help justify whether the additional resources required for large models deliver meaningful benefits. We first focus on characterizing how model performance improves as we scale compute, data and model size (number of parameters).
Our results highlight, over multiple orders of magnitude of compute, performance scales sublinearly with compute. Then, at the higher end of computing power, we observe a plateau where adding more resources does not continue to reduce error as much. This behavior has also been observed for scaling language models and vision transformers.
Below we illustrate data scaling across various model sizes. Performance improves monotonically to approximately 105 hours of data (middle chart), beyond which the rate of improvement diminishes, particularly around 107 hours. Larger models, especially the ViT-110M, continue to benefit from data scaling, showing substantial gains when training on over 1 million hours of data (also shown below). These observations underscore the large data requirements needed to fully exploit the capacity of larger models, which are far greater than those required for smaller models. A similar trend is observed in discriminative tasks.
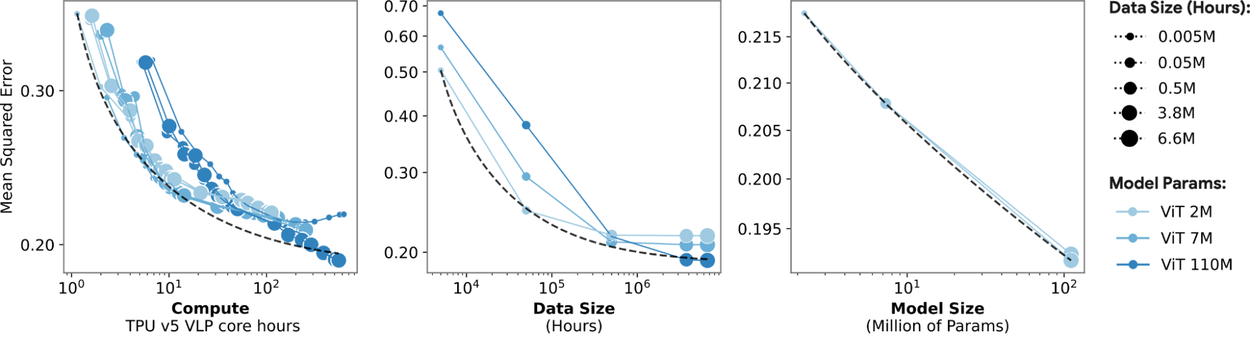
Through a set of systematic scaling experiments of sensor models using up to 40 million hours of multimodal data, we show that increasing compute, data, and model size are all effective at improving the model’s ability to reconstruct unseen data (range through 10 million hours shown above).
Next we assess whether these pre-trained models lead to benefits on useful downstream classification tasks. Two useful tasks are detecting whether an individual is engaged in a physical exercise and classifying what activity they are doing. Ideally we want to be able to build these models with a relatively small amount of labeled examples, something we call label efficiency.
Our experiment on few-shot learning for activity indicates that wearable foundation models can learn effectively with very few labeled examples. The performance of LSM consistently outperforms supervised baselines across all shot counts. Even in the low-data regime (5- and 10-shot), LSM demonstrates promising results, achieving significantly higher accuracy compared to models trained from scratch (the baseline) or with limited supervision (linear probe), as illustrated in the figure below. As the number of labeled examples increases, the performance gap widens, with LSM leveraging pre-training to more effectively transfer learned representations to downstream tasks.
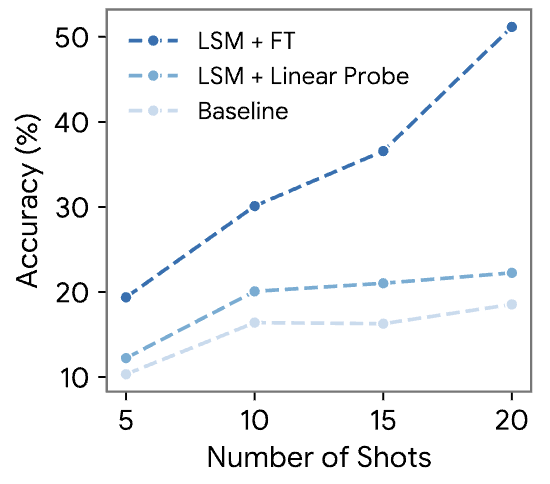
Activity recognition results for few-shot learning experiments.
Additionally, our findings suggest that increasing the total number of wearable signal hours is more impactful for model performance than simply adding more subjects when the total hours are held constant. This may be because capturing a wider variety of activities within each subject (by having more hours per subject) plays a crucial role. However, for maximizing model generalization, scaling both the number of subjects and hours per subject is ideal, as this approach combines intra-subject variability with inter-subject diversity. Together, these factors help the model learn richer representations and enhance performance across different tasks.
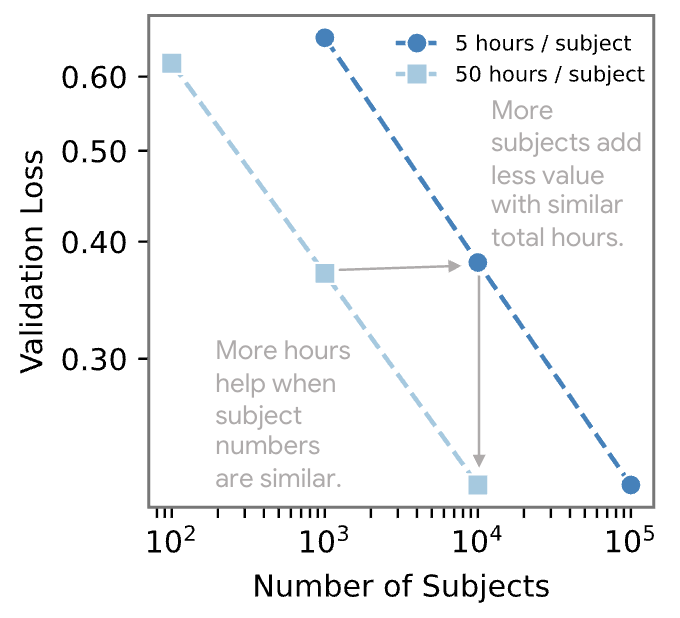
Analysis on data scaling LSM: The total number of hours is more important than the total number of subjects.
Conclusion
Our research establishes a foundation for scaling wearable sensor models by training on an unprecedented dataset of 40 million hours from 165,000 users. This effort demonstrates that scaling data, model size, and compute enables significant advancements in tasks such as imputation, interpolation, and extrapolation, as well as in discriminative tasks.
Looking forward, we plan to explore additional strategies for further scaling with diverse datasets and custom pre-training techniques to address the unique challenges of wearable sensor data, ultimately contributing to the broader landscape of personal health technologies.
Acknowledgements
The research described here is joint work across Google Research, Google Health, Google DeepMind, and partnering teams. The following researchers contributed to this work: Girish Narayanswamy, Xin Liu, Kumar Ayush, Yuzhe Yang, Xuhai Xu, Shun Liao, Jake Garrison, Shyam Tailor, Jake Sunshine, Yun Liu, Tim Althoff, Shrikanth Narayanan, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Samy Abdel-Ghaffar, Daniel McDuff. We would also like to thank participants who contributed their data for this study.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence



