
Advancing personal health and wellness insights with AI
June 11, 2024
Shwetak Patel, Distinguished Engineer & Health Technologies Lead, Google, and Shravya Shetty, Principal Engineer, Google Research
Our research introduces a novel large language model that aims to understand and reason about personal health questions and data. To systematically evaluate our model, we curate a set of three benchmark datasets that test expert domain knowledge, alignment with patient reported outcomes, and the ability to produce human quality recommendations.
Mobile and wearable devices can provide continuous, granular, and longitudinal data on an individual’s physiological state and behaviors. Examples include step counts, raw sensor measurements such as heart rate variability, sleep duration, and more. Individuals can use these data for personal health monitoring as well as to motivate healthy behavior. This represents an exciting area in which generative AI models can be used to provide additional personalized insights and recommendations to an individual to help them reach their health goals. To do so, however, models must be able to reason about personal health data comprising complex time series and sporadic information (like workout logs), contextualize these data using relevant personal health domain knowledge, and produce personalized interpretations and recommendations grounded in an individual’s health context.
Consider a common health query, “How can I get better sleep?” Though a seemingly straightforward question, arriving at a response that is customized to the individual involves performing a series of complex analytical steps, such as: checking data availability, calculating average sleep duration, identifying sleep pattern anomalies over a period of time, contextualizing these findings within the individual's broader health, integrating knowledge of population norms of sleep, and offering tailored sleep improvement recommendations. Recently, we showed how building on Gemini models’ advanced capabilities in multimodality and long-context reasoning could enable state-of-the-art performance on a diverse set of medical tasks. However, such tasks rarely make use of complex data sourced from mobile and wearable devices relevant for personal health monitoring.
Building on the next-generation capabilities of Gemini models, we present research that highlights two complementary approaches to providing accurate personal health and wellness information with LLMs. The first paper, “Towards a Personal Health Large Language Model”, demonstrates that LLMs fine-tuned on expert analysis and self-reported outcomes are able to successfully contextualize physiological data for personal health tasks. The second paper, “Transforming Wearable Data into Personal Health Insights Using Large Language Model Agents”, emphasizes the value of code generation and agent-based workflows to accurately analyze behavioral health data through natural language queries. We believe that bringing these ideas together, to enable interactive computation and grounded reasoning over personal health data, will be critical components for developing truly personalized health assistants. With these two papers, we curate new benchmark datasets across a range of personal health tasks, which help evaluate the effectiveness of these models.
Towards a personal health large language model
The Personal Health Large Language Model (PH-LLM) is a fine-tuned version of Gemini, designed to generate insights and recommendations to improve personal health behaviors related to sleep and fitness patterns. By using a multimodal encoder, PH-LLM is optimized for both textual understanding and reasoning as well as interpretation of raw time-series sensor data such as heart rate variability and respiratory rate from wearables.
To systematically evaluate PH-LLM, we create and curate a set of three benchmark datasets that test:
- The model’s ability to produce detailed insights and recommendations for individuals based on their measured sleep patterns, physical activity, and physiological responses.
- Expert-level domain knowledge.
- Prediction of self-reported assessments of sleep quality.
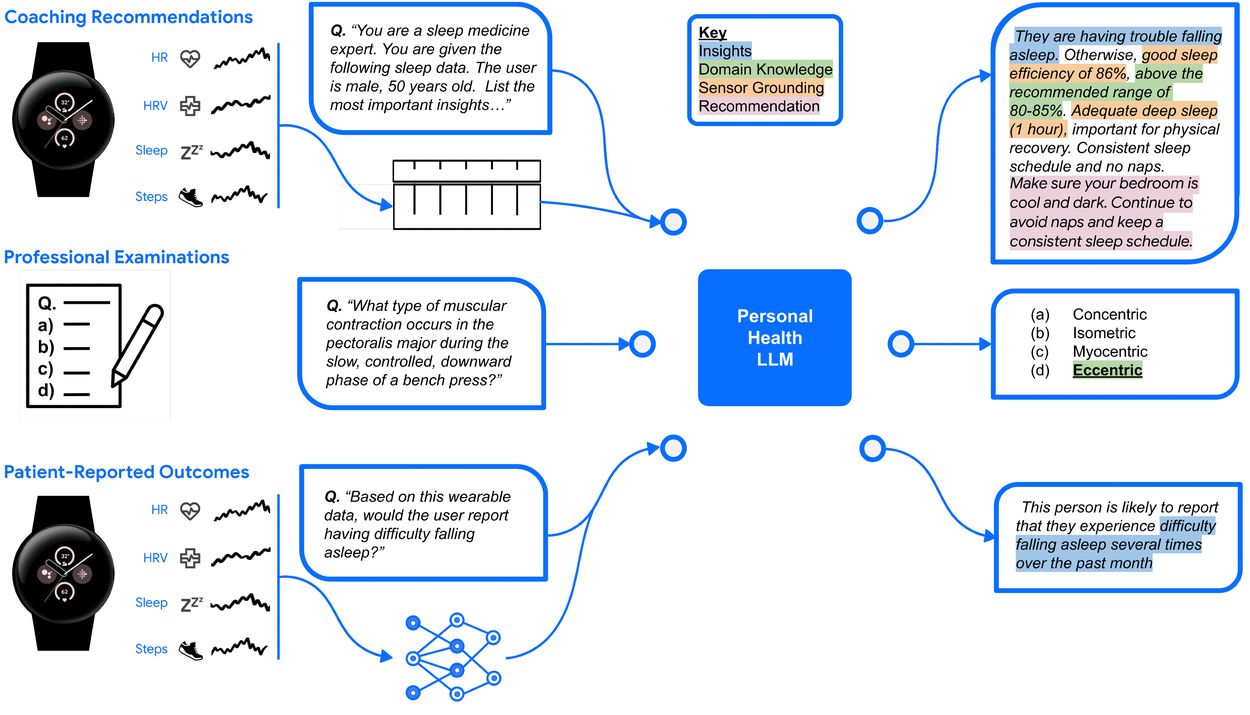
To evaluate PH-LLM, we curate three benchmark datasets that span long-form coaching recommendation tasks, assessments of expert domain knowledge, and prediction of self-reported sleep outcomes.
For the insights and recommendations tasks, we created 857 case studies from consenting US-based users across two personal health verticals: sleep and fitness. These case studies, designed in collaboration with domain experts, represent real-world coaching scenarios and highlight the model’s capabilities in understanding, reasoning, and coaching by interpreting time-series physiological data using textual representations. Through comprehensive evaluation of model responses, we observe that performance of both Gemini Ultra 1.0 and PH-LLM is not statistically different from expert performance in fitness. While recommendations written by experts are rated higher for sleep, the performance is close, and further fine-tuning PH-LLM significantly improves its ability to use relevant domain knowledge and personalize information when generating insights and predicting potential causal factors.
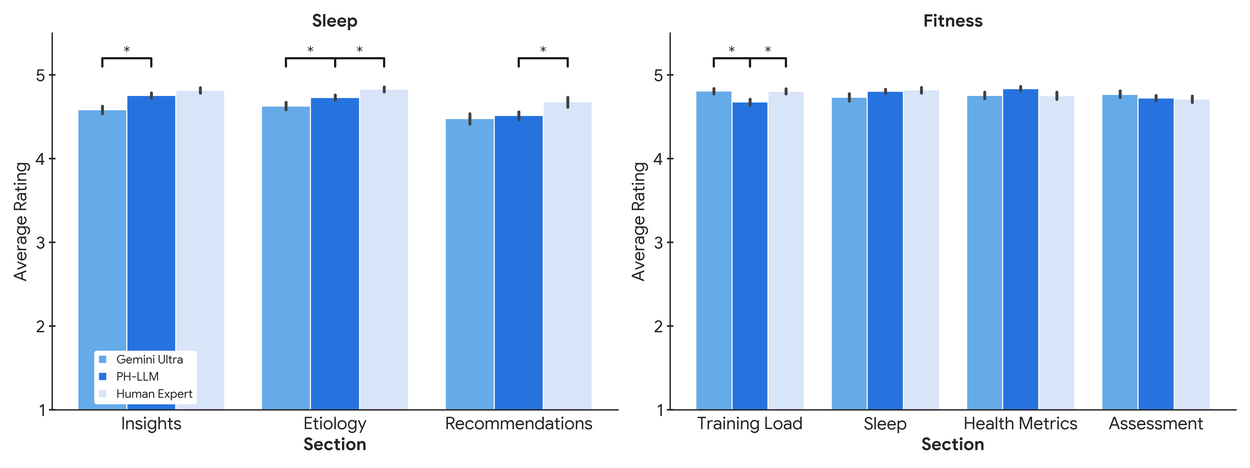
Based on evaluations by human experts, fine-tuning of PH-LLM improves its ability to generate accurate insights and potential causative factors in sleep. Here we present the mean expert rating (higher is better) across evaluation rubrics for each case study subsection. Performance in fitness is not statistically different from human experts. “∗” indicates a statistically significant difference between two response types after multiple hypothesis testing correction.
To further assess expert domain knowledge, we evaluated PH-LLM performance on multiple choice question datasets in the style of sleep medicine and fitness certification examinations via manual test takers using online portals. PH-LLM achieved 79% on sleep (N=629 questions) and 88% on fitness (N=99 questions), both of which exceed average scores from a sample of human experts (76% and 71%, respectively) as well as benchmarks for receiving continuing education credit to maintain professional licenses in those domains.
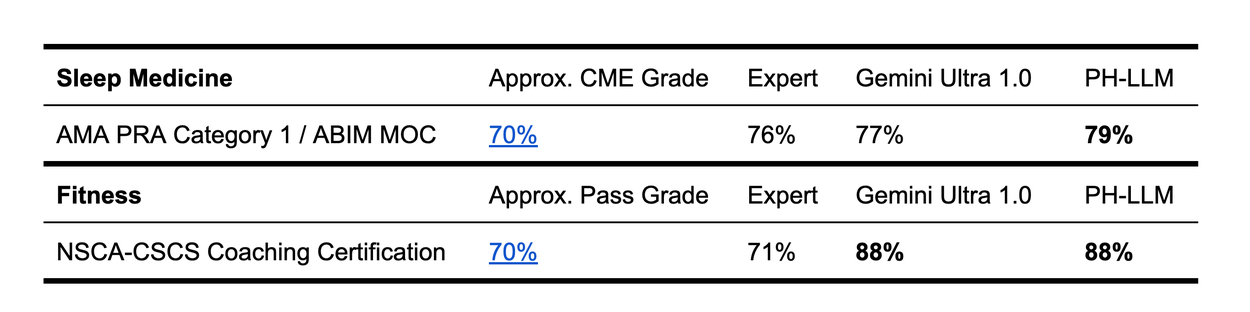
AMA = American Medical Association, PRA = Physician's Recognition Award, ABIM = American Board of Internal Medicine, MOC = Maintenance of Certification, CME = Continuing Medical Education, NSCA = National Strength and Conditioning Association, CSCS = Certified Strength and Conditioning Specialists.
Finally, to enable PH-LLM to predict self-reported assessments of sleep quality, we trained the model on responses to validated survey questions on sleep disruption and impairment using textual and multimodal encoding representations of wearable sensor data. Shown below, we demonstrate that multimodal encoding is both necessary and sufficient to achieve performance on par with discriminative models trained solely to predict these outcomes.
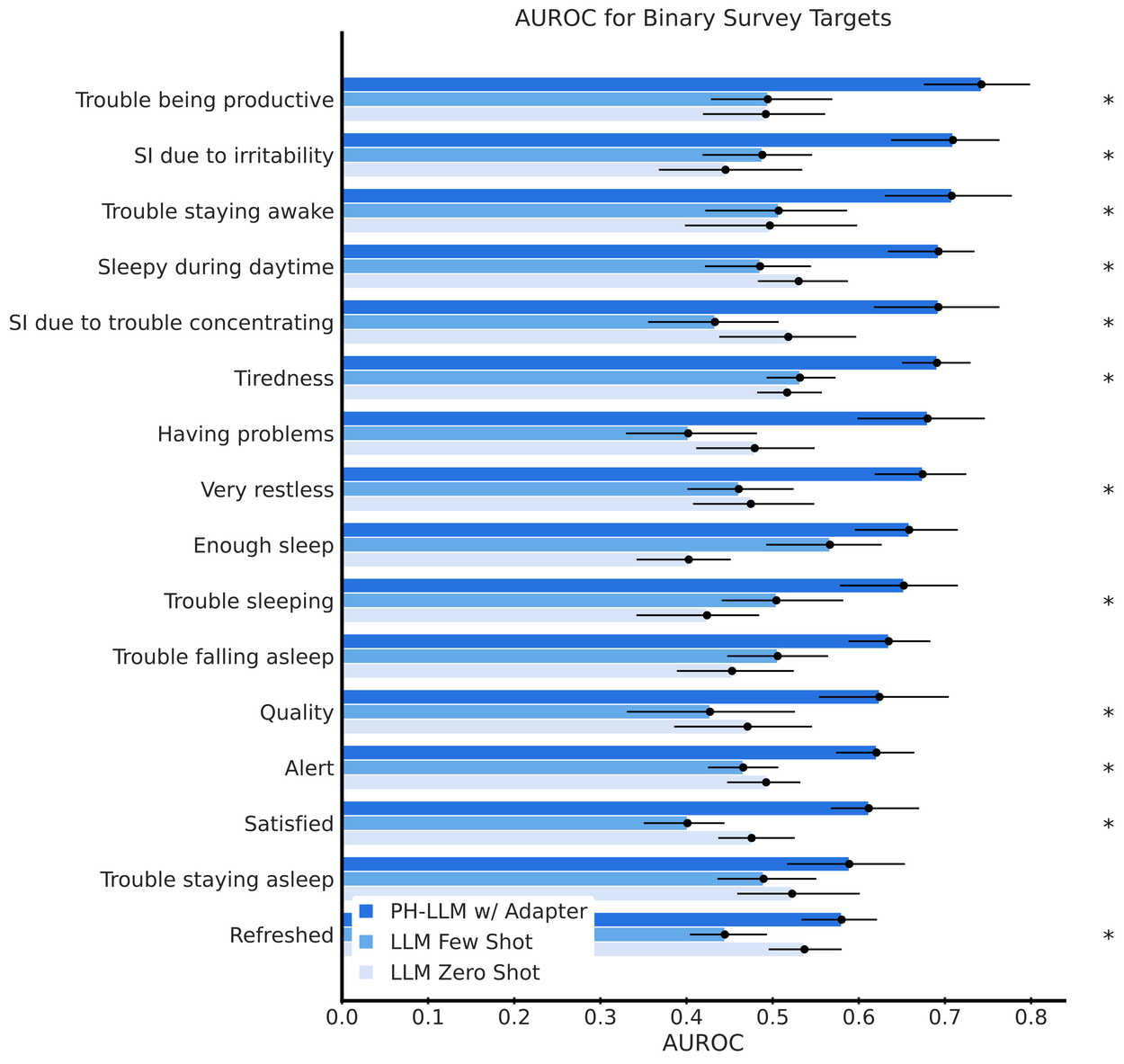
Predictive AUROC performance of PH-LLM model variants on self-reported sleep outcomes. Encoding multimodal sensor data with an adapter outperforms equivalent text representations for both zero- and few-shot prompting for 12 out of 16 outcomes (denoted with “*”) with statistical significance.
Together, these results demonstrate the benefit of tuning PH-LLM to contextualize physiological data for personal health applications.
Transforming wearable data into personal health insights
LLMs can be augmented with software tools to extend their capabilities, examples of which include code generation and information retrieval. The ability of LLM-based agents to iteratively reason and interact with tools offers a promising way to extend their reasoning abilities to complex, temporal wearable data. In our second paper, we introduce a framework for a personal health insights agent based on Gemini Ultra 1.0. The agent leverages the power of Gemini models along with an agent framework, code generation capabilities, and information retrieval tools to iteratively analyze raw wearable data and provide personalized interpretations and recommendations to health queries. This combination enables the agent to:
- Analyze data from wearable devices: the agent employs a Python interpreter to analyze multi-dimensional time-series data from wearables, performing complex calculations and identifying trends.
- Integrate additional health knowledge: the agent accesses a knowledge base via a search engine, incorporating up-to-date medical and health information into its responses.
- Provide personalized insights: the agent conducts iterative multi-step reasoning through individual data, medical knowledge, and specific user queries, generating tailored insights and recommendations.
An example that shows how the agent reasons a personal health query step by step. This is for illustrative purposes only.
To evaluate the agent’s capabilities, we curated two datasets: one to test the agent's numerical accuracy in health queries, and the other to assess the quality of its reasoning and code in open-ended health queries through human annotations.
On the first dataset, Objective Health Insights Queries, the agent achieved 84% accuracy on a dataset of 4,000 objective personal health insights queries, demonstrating its ability to handle numerical reasoning and data analysis.
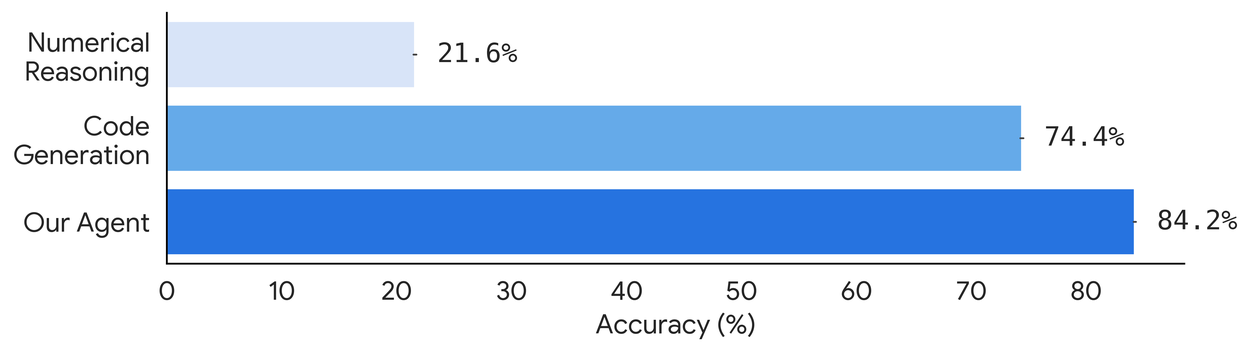
Our agent scores better than the Code Generation and standard LLM Numerical Reasoning baselines on objective personal health insights queries. Accuracy is based on an exact match to within two digits of precision.
On the second dataset, Open-Ended Health Insights Queries, we assess the agent’s performance on 172 representative open-ended personal health queries across over 600 hours of human evaluation of more than 6000 model responses. Overall, the agent significantly improved performance over a non-agent code generation baseline in nine of the 14 axes of evaluation, including key aspects like domain knowledge, logic, and reasoning quality.
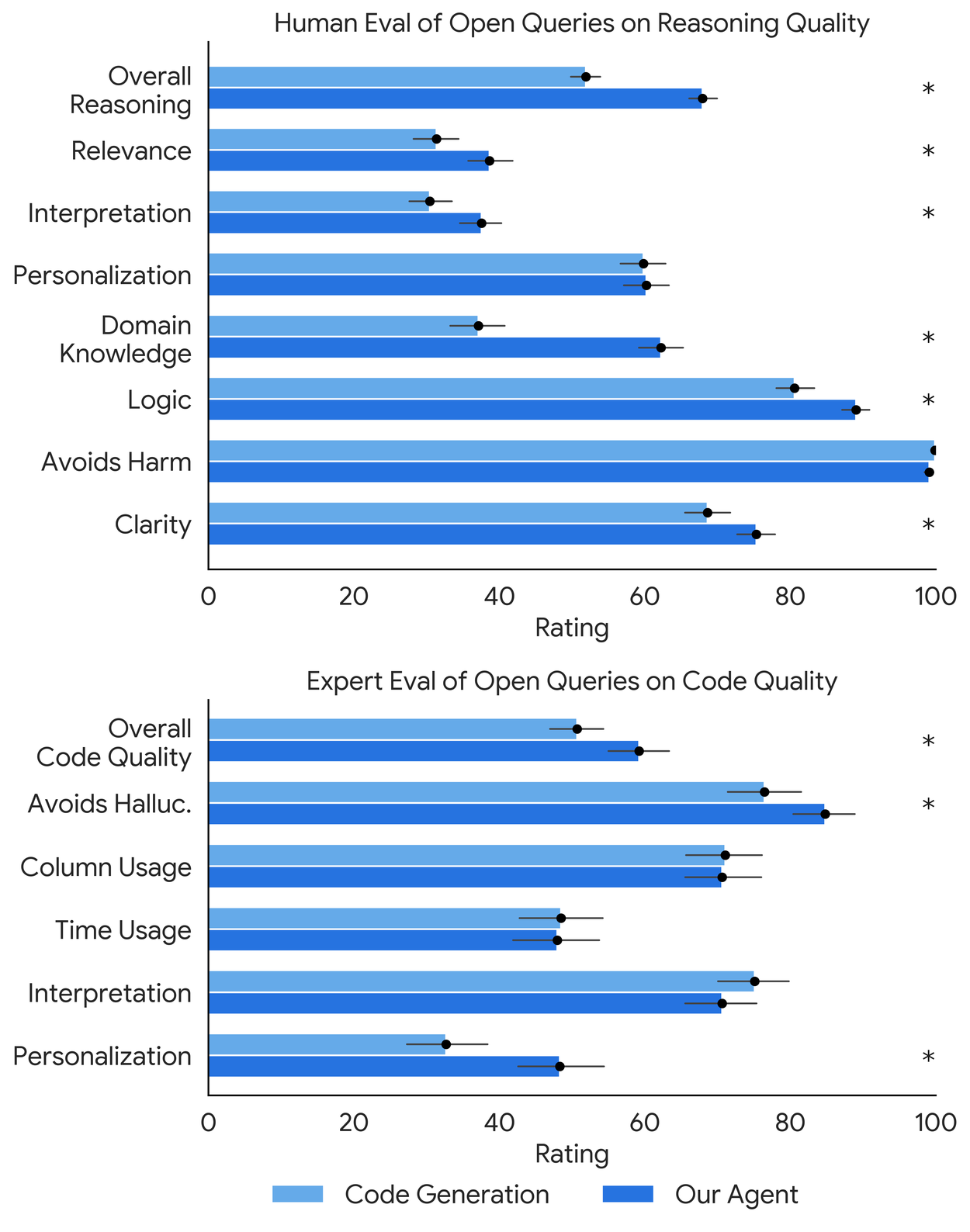
Our human and expert evaluations show that our agent outperforms the code generation baseline, indicating the importance of iterative reasoning and tool usage. “∗” indicates a statistically significant difference between average ratings.
While the agent focuses on sleep and fitness data, its framework can be extended to analyze a broader range of health information, including medical records, nutrition data, and even user-provided journal entries. As LLMs continue to advance, agents have the potential to become increasingly sophisticated and may offer even deeper insights and more effective guidance for personal health management.
Conclusion
Our primary goals are to research features and capabilities that may help people live longer, healthier lives. Sleep and fitness are crucial components of population health and are predictors of premature mortality worldwide. The capabilities enabled by our research in case studies, personal health domain knowledge, and open-ended queries in sleep and fitness represent a meaningful step toward AI models that support personalized insights and recommendations that enable individuals to draw accurate and actionable conclusions from their own health data. We look forward to careful testing and understanding which capabilities are most helpful for users.
Acknowledgements
The research described here is joint work across Google Research, Google Health, Google DeepMind and partnering teams.
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 24, 2026
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
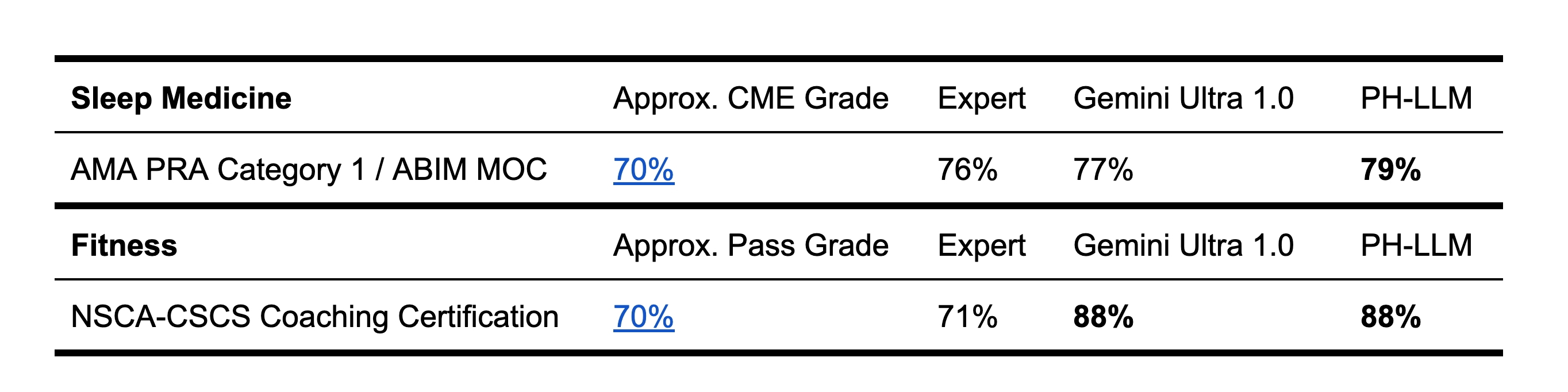
AMA = American Medical Association, PRA = Physician's Recognition Award, ABIM = American Board of Internal Medicine, MOC = Maintenance of Certification, CME = Continuing Medical Education, NSCA = National Strength and Conditioning Association, CSCS = Certified Strength and Conditioning Specialists.

Predictive AUROC performance of PH-LLM model variants on self-reported sleep outcomes. Encoding multimodal sensor data with an adapter outperforms equivalent text representations for both zero- and few-shot prompting for 12 out of 16 outcomes (denoted with “*”) with statistical significance.

Based on evaluations by human experts, fine-tuning of PH-LLM improves its ability to generate accurate insights and potential causative factors in sleep. Here we present the mean expert rating (higher is better) across evaluation rubrics for each case study subsection. Performance in fitness is not statistically different from human experts. “∗” indicates a statistically significant difference between two response types after multiple hypothesis testing correction.
To evaluate PH-LLM, we curate three benchmark datasets that span long-form coaching recommendation tasks, assessments of expert domain knowledge, and prediction of self-reported sleep outcomes.

Our agent scores better than the Code Generation and standard LLM Numerical Reasoning baselines on objective personal health insights queries. Accuracy is based on an exact match to within two digits of precision.

Our human and expert evaluations show that our agent outperforms the code generation baseline, indicating the importance of iterative reasoning and tool usage. “∗” indicates a statistically significant difference between average ratings.