Scalable learning of segment-level traffic congestion functions
November 19, 2024
Shushman Choudhury and Iveel Tsogsuren, Software Engineers, Google Research, Athena Team
We propose and study a framework for identifying traffic congestion functions (numerical relationships between observations of traffic variables) at global scale and segment-level granularity.
Quick links
Cities face the constant challenge of traffic congestion, which is intrinsically linked to our quality of life. Congested streets impact not only our economies but also the environment and our collective well-being. To build smarter cities, we need a quantitative understanding of how traffic behaves, just as Google’s Project Green Light explores how to improve traffic flow.
Central to understanding traffic are congestion functions, which provide a mathematical way to capture congestion at the level of individual roadway segments: as vehicle volume increases, congestion tends to grow, and travel speeds tend to reduce. The challenge of identifying congestion functions — accurately estimating speed based on observed vehicle volume — is key to several applications, such as real-time navigation, traffic flow simulation, and traffic management.
Mathematical models for road network congestion have a long and impactful history. Most prior models are based on physics and are applied to individual road segments. Unfortunately, traffic sensors are typically only installed on major roadways, leading to sparse or non-existent data for many urban streets and thus incomplete model coverage. While solutions for these issues have historically been limited, the recent rise of vehicle telematics and smartphones enables vehicles to act as moving sensors and collect real-time estimates of vehicle speed and volumes over a much wider set of roads. With these new data sources, perhaps a data-driven approach to identify congestion functions could succeed, even at a global scale for any road in a city and any city in the world.
In “Scalable Learning of Segment-Level Traffic Congestion Functions”, we explore this challenge systematically. Our goal is to fuse data across all road segments of a city to yield a single model for the city, enabling more robust inference on roadways with limited data. We assess our framework's ability to identify congestion functions and predict segment attributes on a large, multi-city dataset. Despite the challenges posed by data sparsity, our approach demonstrated strong performance, particularly in generalizing to unobserved road segments.

Two similar roadways in opposite situations: (left) free-flow and (right) high traffic. Congestion functions help model the spectrum between these extremes.
Model design
Our approach builds on two fundamental insights about traffic modeling:
- Congestion functions depend on roadway characteristics. Every road has static attributes, such as length, width, and number of lanes, which influence how traffic behaves. These attributes do not change often and can be measured for any road.
- Congestion patterns are recurrent. On any given roadway, traffic behavior follows predictable patterns based on time. Congestion in the morning rush hour differs from the lull at midday or the evening rush. These recurring patterns are driven by dynamic factors such as time of day and day of the week.
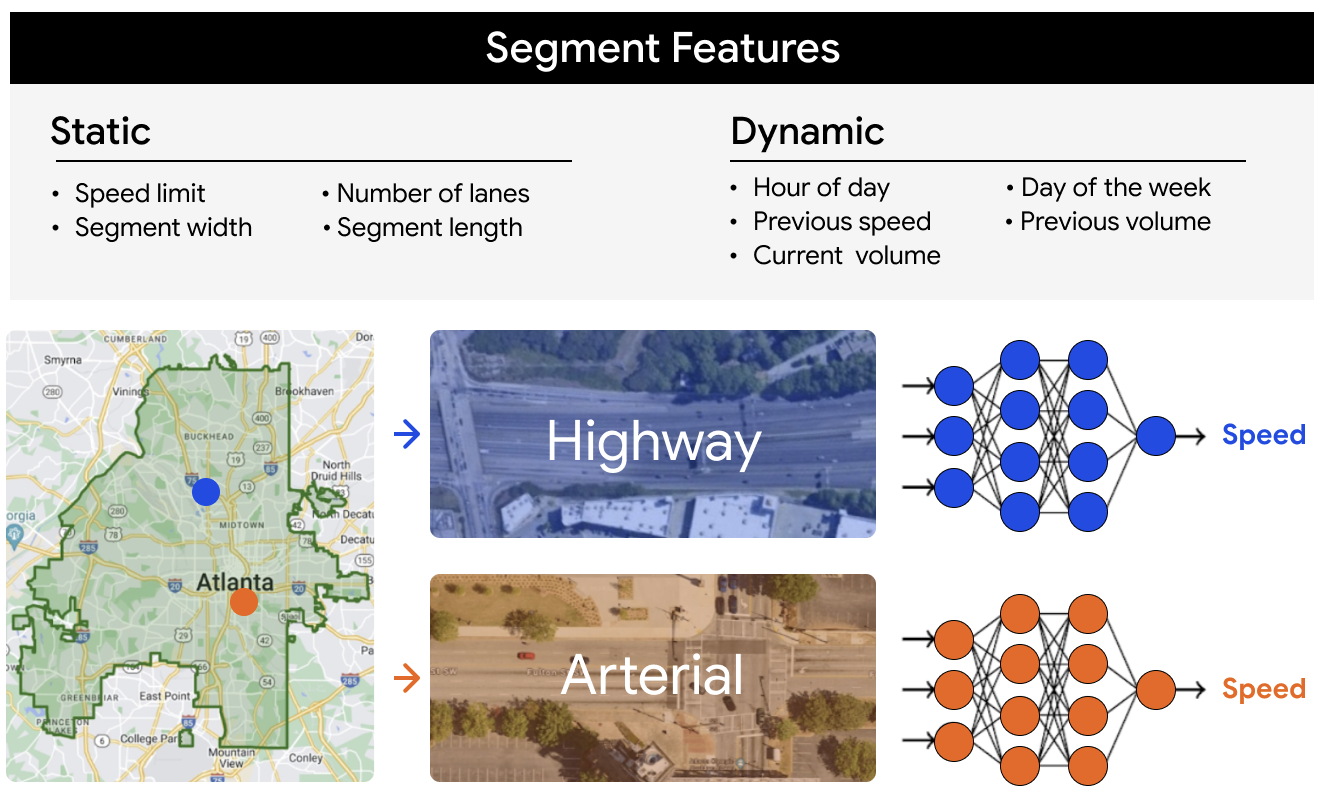
Instead of a separate model for each individual road (like most prior work), we fuse data from all road segments in a city and across all time periods, using both static and dynamic features. These features are then fed into a single machine learning (ML) model that learns a general congestion function. The model can then estimate the average speed on any given road segment, using the road’s specific static attributes and the dynamic conditions at the time.
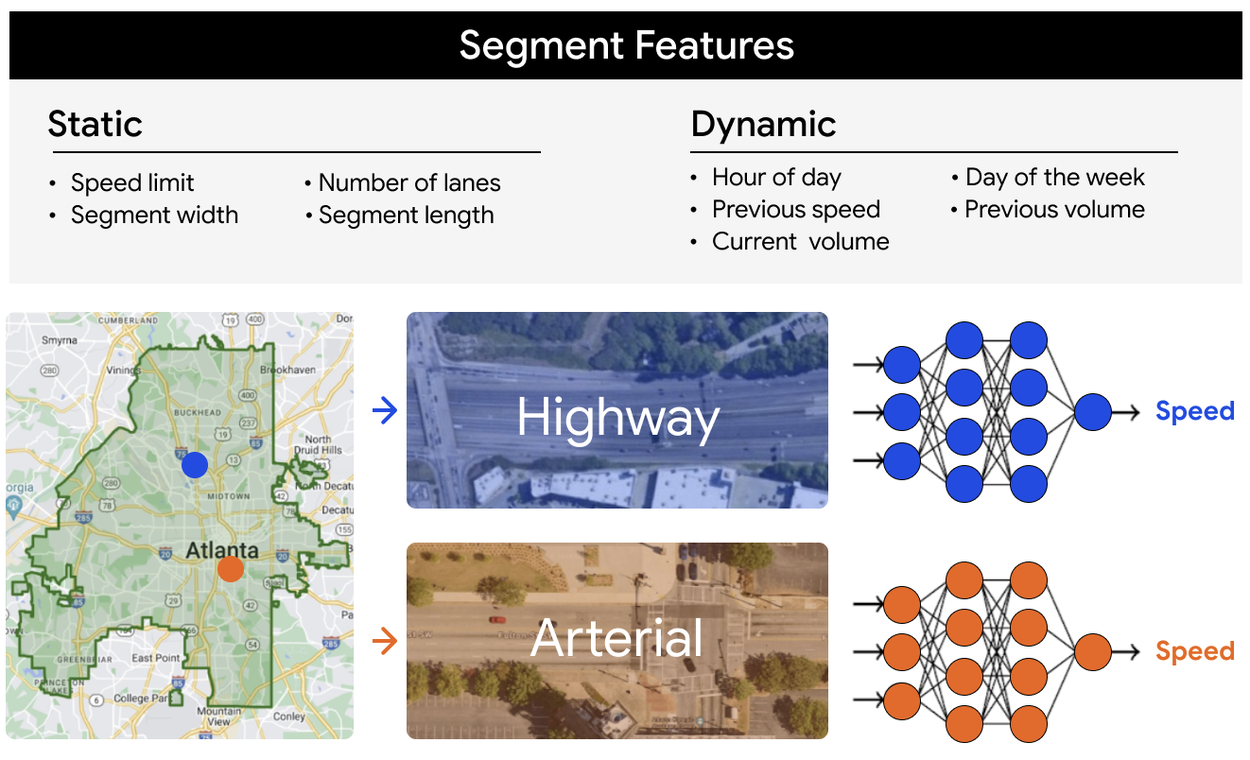
Our framework learns congestion functions from static and dynamic data of all highway and arterial road segments in a city.
While our data-driven framework is an exciting prospect, one of the biggest challenges is generalization. Roadways exhibit remarkable variability. Even within a single segment, factors like traffic signal timing can alter traffic flow. This variability, coupled with limited data for many roads, makes it hard to create highly accurate and road-specific models for every street. The key question becomes: can a single model work well even on roads with limited data, effectively generalizing across diverse road types and cities?
This challenge has not been studied at this scale before, so our work is primarily an exploration into the strengths and limits of the approach. We want to test if such a model can truly scale across all roadways in a city, or even across cities with different traffic patterns, without significantly losing accuracy.
Experiments
We conducted many experiments on a comprehensive dataset from multiple major global cities, spanning different continents, traffic rules, and driving patterns. Our data, sourced from Google Maps road network data and anonymized driving trends, comprised hourly measurements of vehicle volume and speed from 7am to 10pm across all days of the week. We trained our model on five weeks of data and tested it on the following week, allowing us to evaluate how well our approach can make predictions on unobserved data.
For each city, we separated our analyses into two broad road categories: highways (major roads that connect regions) and arterials (moderate to high-capacity urban roads). These roads are the most critical for understanding city-wide traffic congestion patterns. The two types have fundamentally different roadway characteristics and traffic dynamics. Thus, we trained and evaluated models on each separately for more granular and targeted experiments.
Where relevant, we also compared our approach to a commonly used, road-specific model known as the Bureau of Public Roads (BPR) link function. The BPR function assumes a physics-based relationship between speed and traffic flow, and fits its parameters to data. It can only be applied when there is enough data for a specific road, and thus provides a relevant baseline for comparison on both accuracy and generalization.
Results
Estimation performance
On average, for highway segments with sufficient data for the BPR function to apply, our single data-driven congestion function estimated traffic speed with similar or lower error. Crucially, it performed comparably well on segments where there wasn’t enough data to fit an individual BPR model. This scalability is a significant advantage when cities cannot collect extensive traffic data on every road.
However, on arterial roads, our approach struggled relative to the baseline. Arterial roads vary more in their features and receive less consistent data than highways, which was the likely culprit in the lower performance when modeling them. In some cities, up to 20% of arterials lacked enough data for a BPR function (compared with 5–7% for city highways), which highlights the complexity of urban roadways and the need for further refinement in our approach.
Perhaps the most interesting finding was how our model performed during periods of transition between free-flow and congested traffic, which are critical for understanding and managing congestion. On highways, our approach showed more improvement over the baseline during these transition periods. This suggests that our data-driven model is especially valuable when it comes to predicting traffic during some of the most dynamic and challenging times.
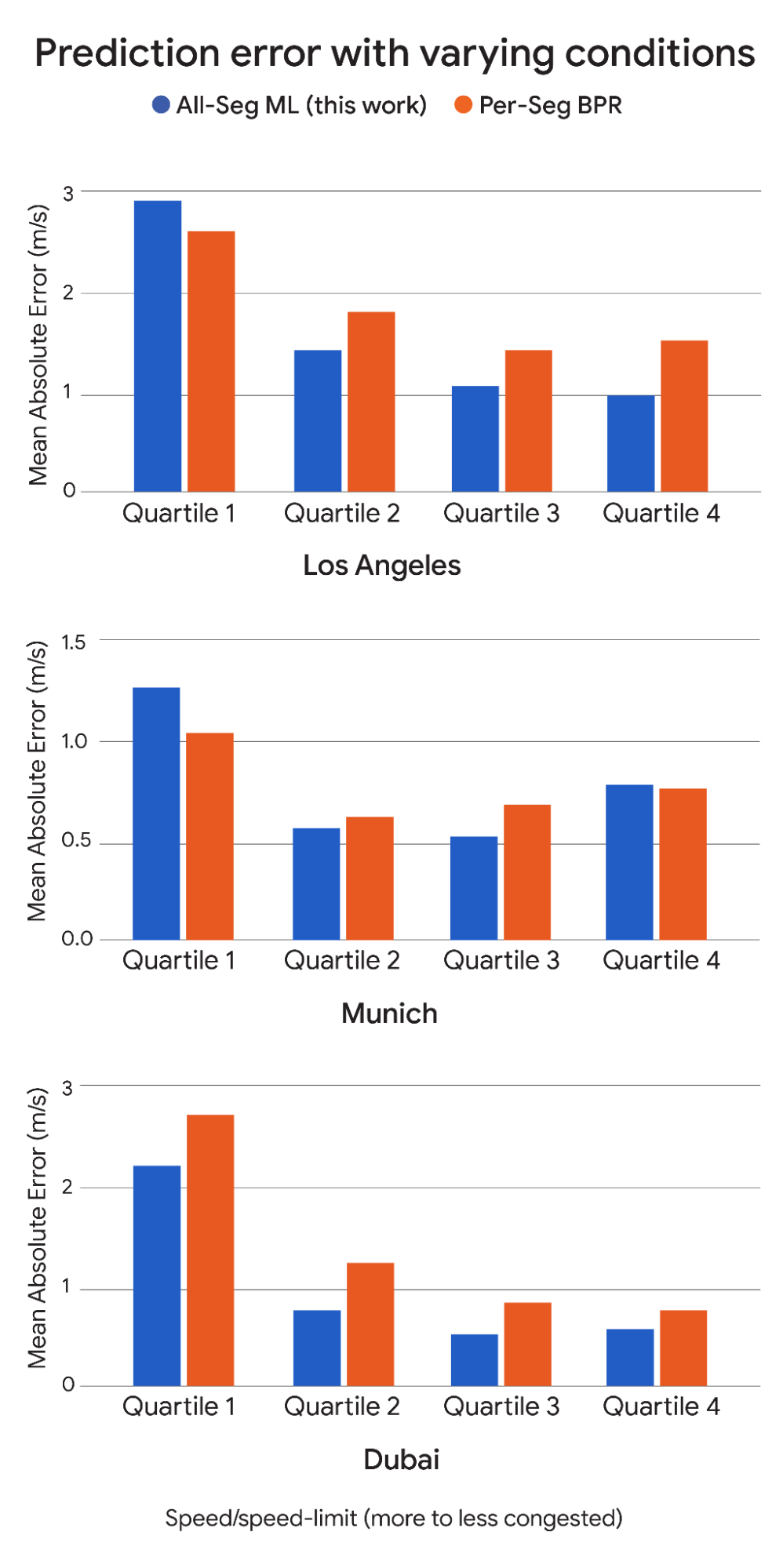
For highways of three representative cities (left to right; Los Angeles, Munich, Dubai), we compare the estimation error (lower is better) between our framework (blue) and the road-specific BPR function (orange) in four underlying traffic conditions: most congested (Quartile 1) to free flow (Quartile 4). The results show that our approach performs particularly well in Quartiles 2 and 3, the most critical regimes of transition between free-flow and congestion.
Generalization
Within the same city, we found that our model could generalize well to unobserved road segments. For example, if we trained the model on 80% of the roadways, it could identify congestion functions on the remaining 20% of unobserved segments almost as well as it did on segments for which we had data. This ability to generalize is key for making traffic models scalable and useful for real-world applications.
We went further by testing the model’s ability to generalize across cities. Could a model trained in one city work for another city with entirely different traffic patterns? To test this, we took a model trained on five weeks of traffic data from one city and evaluated it on five weeks of data from another city. Our results were intriguing: when both cities were in the US or Europe, the model transferred well, producing results comparable to the original city. However, when we tested between cities on different continents — for example between Asian and non-Asian cities — the transfer was less effective. This highlights potential limits in learning traffic models globally, possibly due to differences in driving behavior and infrastructure.
Additional traffic insights
As a bonus experiment, we explored whether our single city-wide model could predict other important traffic properties of roadways, such as critical density — the point at which a road transitions from free-flow to congestion. Our model performed well in this task, producing predictions comparable to those from road-specific models. Perhaps our approach could be used for a range of traffic analysis tasks beyond estimating congestion functions.
Broader implications
Our findings are significant for both academic research and practical traffic understanding and management. They demonstrate the power of ML to model traffic patterns at a global scale, a task that was previously difficult with traditional physics-based models. However, our work is just the beginning. There is ample room to enhance the model by including more complex features (e.g., stoplights, road signs), using advanced architectures like graph neural networks, or introducing physics-informed constraints (as has been used in robotics) to better capture traffic dynamics.
For city planners and transportation authorities, this approach offers a new way to make sense of traffic patterns across their entire road network without needing sensors on every street. The scalability of our approach means it could be deployed globally, making real-time traffic management and long-term planning more efficient and effective. As urban populations grow, data-driven frameworks like ours could become essential tools for designing smarter, more sustainable cities.
Acknowledgements
This work was done in collaboration with Aboudy Kreidieh, Neha Arora, Carolina Osorio, and Alexandre Bayen. The authors also thank Pranjal Awasthi for insights and guidance.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence

