Robot See, Robot Do
February 8, 2022
Posted by Kevin Zakka, Student Researcher and Andy Zeng, Research Scientist, Robotics at Google
Quick links
People learn to do things by watching others — from mimicking new dance moves, to watching YouTube cooking videos. We’d like robots to do the same, i.e., to learn new skills by watching people do things during training. Today, however, the predominant paradigm for teaching robots is to remote control them using specialized hardware for teleoperation and then train them to imitate pre-recorded demonstrations. This limits both who can provide the demonstrations (programmers & roboticists) and where they can be provided (lab settings). If robots could instead self-learn new tasks by watching humans, this capability could allow them to be deployed in more unstructured settings like the home, and make it dramatically easier for anyone to teach or communicate with them, expert or otherwise. Perhaps one day, they might even be able to use Youtube videos to grow their collection of skills over time.
 |
| Our motivation is to have robots watch people do tasks, naturally with their hands, and then use that data as demonstrations for learning. Video by Teh Aik Hui and Nathaniel Lim. License: CC-BY |
However, an obvious but often overlooked problem is that a robot is physically different from a human, which means it often completes tasks differently than we do. For example, in the pen manipulation task below, the hand can grab all the pens together and quickly transfer them between containers, whereas the two-fingered gripper must transport one at a time. Prior research assumes that humans and robots can do the same task similarly, which makes manually specifying one-to-one correspondences between human and robot actions easy. But with stark differences in physique, defining such correspondences for seemingly easy tasks can be surprisingly difficult and sometimes impossible.
 |
| Physically different end-effectors (i.e., “grippers”) (i.e., the part that interacts with the environment) induce different control strategies when solving the same task. Left: The hand grabs all pens and quickly transfers them between containers. Right: The two-fingered gripper transports one pen at a time. |
In “XIRL: Cross-Embodiment Inverse RL”, presented as an oral paper at CoRL 2021, we explore these challenges further and introduce a self-supervised method for Cross-embodiment Inverse Reinforcement Learning (XIRL). Rather than focusing on how individual human actions should correspond to robot actions, XIRL learns the high-level task objective from videos, and summarizes that knowledge in the form of a reward function that is invariant to embodiment differences, such as shape, actions and end-effector dynamics. The learned rewards can then be used together with reinforcement learning to teach the task to agents with new physical embodiments through trial and error. Our approach is general and scales autonomously with data — the more embodiment diversity presented in the videos, the more invariant and robust the reward functions become. Experiments show that our learned reward functions lead to significantly more sample efficient (roughly 2 to 4 times) reinforcement learning on new embodiments compared to alternative methods. To extend and build on our work, we are releasing an accompanying open-source implementation of our method along with X-MAGICAL, our new simulated benchmark for cross-embodiment imitation.
Cross-Embodiment Inverse Reinforcement Learning (XIRL)
The underlying observation in this work is that in spite of the many differences induced by different embodiments, there still exist visual cues that reflect progression towards a common task objective. For example, in the pen manipulation task above, the presence of pens in the cup but not the mug, or the absence of pens on the table, are key frames that are common to different embodiments and indirectly provide cues for how close to being complete a task is. The key idea behind XIRL is to automatically discover these key moments in videos of different length and cluster them meaningfully to encode task progression. This motivation shares many similarities with unsupervised video alignment research, from which we can leverage a method called Temporal Cycle Consistency (TCC), which aligns videos accurately while learning useful visual representations for fine-grained video understanding without requiring any ground-truth correspondences.
We leverage TCC to train an encoder to temporally align video demonstrations of different experts performing the same task. The TCC loss tries to maximize the number of cycle-consistent frames (or mutual nearest-neighbors) between pairs of sequences using a differentiable formulation of soft nearest-neighbors. Once the encoder is trained, we define our reward function as simply the negative Euclidean distance between the current observation and the goal observation in the learned embedding space. We can subsequently insert the reward into a standard MDP and use an RL algorithm to learn the demonstrated behavior. Surprisingly, we find that this simple reward formulation is effective for cross-embodiment imitation.
 |
| XIRL self-supervises reward functions from expert demonstrations using temporal cycle consistency (TCC), then uses them for downstream reinforcement learning to learn new skills from third-person demonstrations. |
X-MAGICAL Benchmark
To evaluate the performance of XIRL and baseline alternatives (e.g., TCN, LIFS, Goal Classifier) in a consistent environment, we created X-MAGICAL, which is a simulated benchmark for cross-embodiment imitation. X-MAGICAL features a diverse set of agent embodiments, with differences in their shapes and end-effectors, designed to solve tasks in different ways. This leads to differences in execution speeds and state-action trajectories, which poses challenges for current imitation learning techniques, e.g., ones that use time as a heuristic for weak correspondences between two trajectories. The ability to generalize across embodiments is precisely what X-MAGICAL evaluates.
The SweepToTop task we considered for our experiments is a simplified 2D equivalent of a common household robotic sweeping task, where an agent has to push three objects into a goal zone in the environment. We chose this task specifically because its long-horizon nature highlights how different agent embodiments can generate entirely different trajectories (shown below). X-MAGICAL features a Gym API and is designed to be easily extendable to new tasks and embodiments. You can try it out today with pip install x-magical.
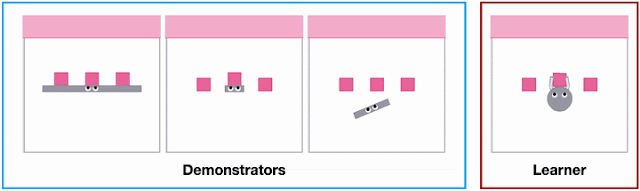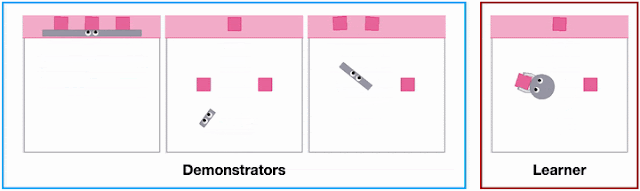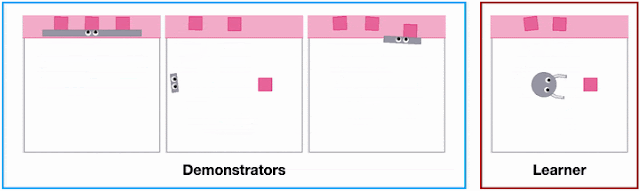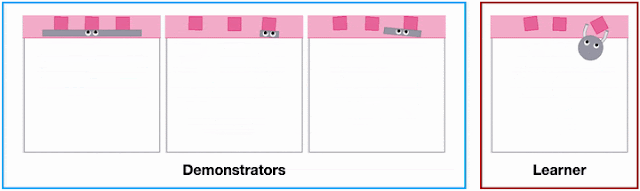 |
| Different agent shapes in the SweepToTop task in the X-MAGICAL benchmark need to use different strategies to reposition objects into the target area (pink), i.e., to “clear the debris”. For example, the long-stick can clear them all in one fell swoop, whereas the short-stick needs to do multiple consecutive back-and-forths. |
 |
 |
| Left: Heatmap of state visitation for each embodiment across all expert demonstrations. Right: Examples of expert trajectories for each embodiment. |
Highlights
In our first set of experiments, we checked whether our learned embodiment-invariant reward function can enable successful reinforcement learning, when the expert demonstrations are provided through the agent itself. We find that XIRL significantly outperforms alternative methods especially on the tougher agents (e.g., short-stick and gripper).
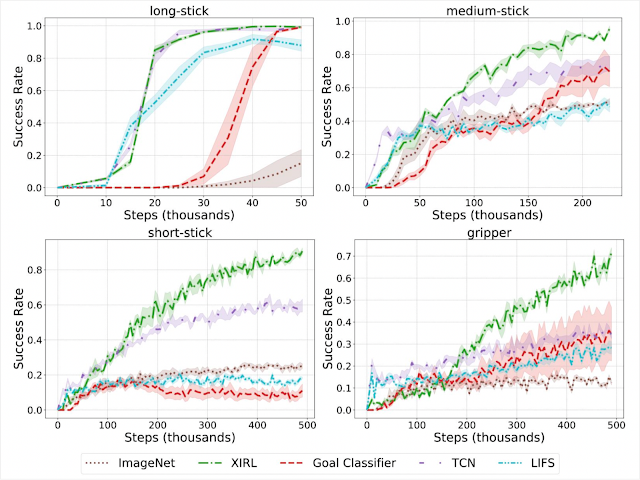 |
| Same-embodiment setting: Comparison of XIRL with baseline reward functions, using SAC for RL policy learning. XIRL is roughly 2 to 4 times more sample efficient than some of the baselines on the harder agents (short-stick and gripper). |
We also find that our approach shows great potential for learning reward functions that generalize to novel embodiments. For instance, when reward learning is performed on embodiments that are different from the ones on which the policy is trained, we find that it results in significantly more sample efficient agents compared to the same baselines. Below, in the gripper subplot (bottom right) for example, the reward is first learned on demonstration videos from long-stick, medium-stick and short-stick, after which the reward function is used to train the gripper agent.
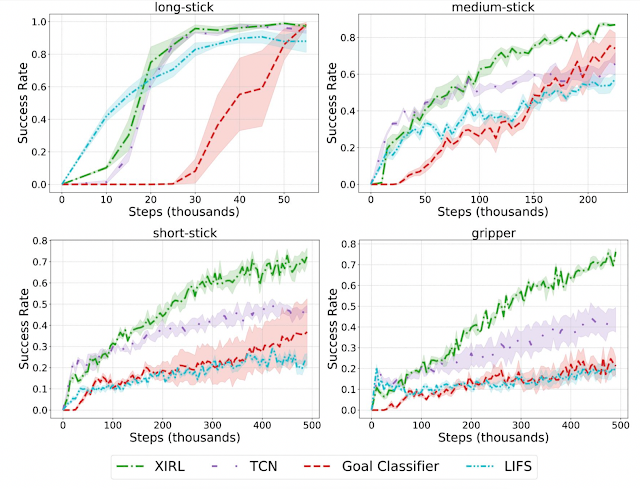 |
| Cross-embodiment setting: XIRL performs favorably when compared with other baseline reward functions, trained on observation-only demonstrations from different embodiments. Each agent (long-stick, medium-stick, short-stick, gripper) had its reward trained using demonstrations from the other three embodiments. |
We also find that we can train on real-world human demonstrations, and use the learned reward to train a Sawyer arm in simulation to push a puck to a designated target zone. In these experiments as well, our method outperforms baseline alternatives. For example, our XIRL variant trained only on the real-world demonstrations (purple in the plots below) reaches 80% of the total performance roughly 85% faster than the RLV baseline (orange).
 |
 |
What Do The Learned Reward Functions Look Like?
To further explore the qualitative nature of our learned rewards in more challenging real-world scenarios, we collect a dataset of the pen transfer task using various household tools.
 |
Below, we show rewards extracted from a successful (top) and unsuccessful (bottom) demonstration. Both demonstrations follow a similar trajectory at the start of the task execution. The successful one nets a high reward for placing the pens consecutively into the mug then into the glass cup, while the unsuccessful one obtains a low reward because it drops the pens outside the glass cup towards the end of the execution (orange circle). These results are promising because they show that our learned encoder can represent fine-grained visual differences relevant to a task.
 |
Conclusion
We highlighted XIRL, our approach to tackling the cross-embodiment imitation problem. XIRL learns an embodiment-invariant reward function that encodes task progress using a temporal cycle-consistency objective. Policies learned using our reward functions are significantly more sample-efficient than baseline alternatives. Furthermore, the reward functions do not require manually paired video frames between the demonstrator and the learner, giving them the ability to scale to an arbitrary number of embodiments or experts with varying skill levels. Overall, we are excited about this direction of work, and hope that our benchmark promotes further research in this area. For more details, please check out our paper and download the code from our GitHub repository.
Acknowledgments
Kevin and Andy summarized research performed together with Pete Florence, Jonathan Tompson, Jeannette Bohg (faculty at Stanford University) and Debidatta Dwibedi. All authors would additionally like to thank Alex Nichol, Nick Hynes, Sean Kirmani, Brent Yi, Jimmy Wu, Karl Schmeckpeper and Minttu Alakuijala for fruitful technical discussions, and Sam Toyer for invaluable help with setting up the simulated benchmark.
Quick links
Other posts of interest
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence