ROBEL: Robotics Benchmarks for Learning with Low-Cost Robots
October 9, 2019
Posted by Michael Ahn, Software Engineer and Vikash Kumar, Research Scientist, Robotics at Google
Quick links
Learning-based methods for solving robotic control problems have recently seen significant momentum, driven by the widening availability of simulated benchmarks (like dm_control or OpenAI-Gym) and advancements in flexible and scalable reinforcement learning techniques (DDPG, QT-Opt, or Soft Actor-Critic). While learning through simulation is effective, these simulated environments often encounter difficulty in deploying to real-world robots due to factors such as inaccurate modeling of physical phenomena and system delays. This motivates the need to develop robotic control solutions directly in the real world, on real physical hardware.
The majority of current robotics research on physical hardware is conducted on high-cost, industrial-quality robots (PR2, Kuka-arms, ShadowHand, Baxter, etc.) intended for precise, monitored operation in controlled environments. Furthermore, these robots are designed around traditional control methods that focus on precision, repeatability, and ease of characterization. This stands in sharp contrast with the learning-based methods that are robust to imperfect sensing and actuation, and demand (a) a high degree of resilience to allow real-world trial-and-error learning, (b) low cost and ease of maintenance to enable scalability through replication and (c) a reliable reset mechanism to alleviate strict human monitoring requirements.
In “ROBEL: Robotics Benchmarks for Learning with Low-Cost Robots”, to be presented at CoRL 2019, we introduce an open-source platform of cost-effective robots and curated benchmarks designed primarily to facilitate research and development on physical hardware in the real world. Analogous to an optical table in the field of optics, ROBEL serves as a rapid experimentation platform, supporting a wide range of experimental needs and the development of new reinforcement learning and control methods. ROBEL consists of D'Claw, a three-fingered hand robot that facilitates learning of dexterous manipulation tasks and D'Kitty, a four-legged robot that enables the learning of agile legged locomotion tasks. The robotic platforms are low-cost, modular, easy to maintain, and are robust enough to sustain on-hardware reinforcement learning from scratch.
 |
| Left: The 12 DoF D’Kitty; Middle: The 9 DoF D’Claw; Right: A functional D’Claw setup D’Lantern. |
ROBEL Benchmarks
We devised a set of tasks suitable for each platform, D’Claw and D’Kitty, which can be used for benchmarking real-world robotic learning. ROBEL’s task definitions include both dense and sparse task objectives, and introduce metrics for hardware-safety in the task definition, which for example, indicate if joints are exceeding “safe” operating bounds or force thresholds. ROBEL also supports a simulator for all tasks to facilitate algorithmic development and rapid prototyping. D’Claw tasks are centered around three commonly observed manipulation behaviors — Pose, Turn, and Screw.
 |  |  |
| Left: Pose — Conform to the shape of the environment. Center: Turn — Turn the object to a specified angle. Right: Screw — Continuously rotate the object. (Click images for video.) |
 |  |  |
| Left: Stand — Stand upright. Center: Orient — Align heading with the target. Right: Walk — Move to the target. (Click images for video.) |
Reproducibility & Robustness
ROBEL platforms are robust to sustain direct hardware training, and have clocked over 14,000 hours of real-world experience to-date. The platforms have significantly matured over the year. Owing to the modularity of the design, repairs are trivial and require minimal to no domain expertise, making the overall system easy to maintain.
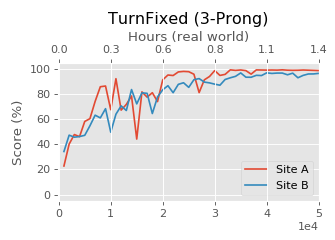
To establish the replicability of the platforms and reproducibility of the benchmarks, ROBEL was studied in isolation by two different research labs. Only software distribution and documentation was used in this study. No in-person visits were allowed. Using ROBEL’s design files and assembly instructions both sites were able to replicate both hardware platforms. Benchmark tasks were trained on robots built at both sites. In the figure below we see that two D’Claw robots built at two different sites not only exhibit similar training progress but also converge to the same final performance, establishing reproducibility of the ROBEL benchmarks.
 |
| SAC training performance of a task on two real D’Claw robots developed at different laboratory locations. |
ROBEL has been useful in a variety of reinforcement learning studies so far. Below we highlight a few of the key results, and you can find all our results in this comprehensive gallery. D’Claw platforms are completely autonomous and can sustain reliable experimentation for an extended period of time, and has facilitated experimentation with a wide variety of reinforcement learning paradigms and tasks using both rigid and flexible objects.
 |  |  |
| Left: Flexible Objects — On-hardware training with DAPG effectively learns to turn flexible objects. We observe manipulation targeting the center of the valve where there is more rigidity. D'Claw is robust to on-hardware training, facilitating successful outcomes on hard to simulate tasks. Center: Disturbance Rejection — A Sim2Real policy trained via Natural Policy Gradient on MuJoCo simulation with object perturbations (amongst others) being tested on hardware. We observe fingers working together to resist external disturbances. Right: Obstructed Finger — A Sim2Real policy trained via Natural Policy Gradient on MuJoCo simulation with external perturbations (amongst others) being tested on hardware. We observe that free fingers fill in for the missing finger. |
 |
| On-hardware training with distributed version of SAC leaning to turn multiple objects to arbitrary angles in conjunction by sharing experience. Five tasks only need twice the amount of experience of single tasks, thanks to the multi-task formulation. In the video we observe five D'Claws turning different objects to 180 degrees (picked for visual effectiveness, actual policy can turn to any angle). |
 |  |  |
| Left: Indoor – Walking in Clutter — A Sim2Real policy trained via Natural Policy Gradient on MuJoCo simulation with randomized perturbations learns to walk in clutter and step over objects. Center: Outdoor – Gravel and Branches — A Sim2Real policy trained via Natural Policy Gradient on MuJoCo simulation with randomized height field learns to walk outdoors over gravel and branches. Right: Outdoor – Slope and Grass — A Sim2Real policy trained via Natural Policy Gradient on MuJoCo simulation with randomized height field learns to handle moderate slopes. |
 |  |  |
| Left: Avoid Moving Obstacles — Policy trained via Hierarchical Sim2Real learns to avoid a moving block and reach the target (marked by the controller on the floor). Center: Push to Moving Goal — Policy trained via Hierarchical Sim2Real learns to push block towards a moving target (marked by the controller in the hand). Right: Co-ordinate — Policy trained via Hierarchical Sim2Real learns to coordinate two D'Kitties to push a heavy block towards a target (marked by two + signs on the floor). |
Acknowledgments
Google's ROBEL D'Claw evolved from earlier designs Vikash Kumar developed at the Universities of Washington and Berkeley. Multiple people across organizations have contributed towards the ROBEL projects. We thank our co-authors Henry Zhu (UC Berkeley), Kristian Hartikainen (UC Berkeley), Abhishek Gupta (UC Berkeley) and Sergey Levine (Google and UC Berkeley) for their contributions and extensive feedback throughout the project. We would like to acknowledge Matt Neiss (Google) and Chad Richards (Google) for their significant contribution to the platform designs. We would also like to thank Aravind Rajeshwaran (U-Washington), Emo Todorov (U-Washington), and Vincent Vanhoucke (Google) for their helpful discussions and comments throughout the project.
-
Labels:
- Machine Intelligence
- Robotics
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯