Revisiting Mask-Head Architectures for Novel Class Instance Segmentation
September 15, 2021
Posted by Vighnesh Birodkar, Research Software Engineer and Jonathan Huang, Research Scientist, Google Research
Quick links
Instance segmentation is the task of grouping pixels in an image into instances of individual things, and identifying those things with a class label (countable objects such as people, animals, cars, etc., and assigning unique identifiers to each, e.g., car_1 and car_2). As a core computer vision task, it is critical to many downstream applications, such as self-driving cars, robotics, medical imaging, and photo editing. In recent years, deep learning has made significant strides in solving the instance segmentation problem with architectures like Mask R-CNN. However, these methods rely on collecting a large labeled instance segmentation dataset. But unlike bounding box labels, which can be collected in 7 seconds per instance with methods like Extreme clicking, collecting instance segmentation labels (called “masks”) can take up to 80 seconds per instance, an effort that is costly and creates a high barrier to entry for this research. And a related task, pantopic segmentation, requires even more labeled data.
The partially supervised instance segmentation setting, where only a small set of classes are labeled with instance segmentation masks and the remaining (majority of) classes are labeled only with bounding boxes, is an approach that has the potential to reduce the dependence on manually-created mask labels, thereby significantly lowering the barriers to developing an instance segmentation model. However this partially supervised approach also requires a stronger form of model generalization to handle novel classes not seen at training time—e.g., training with only animal masks and then tasking the model to produce accurate instance segmentations for buildings or plants. Further, naïve approaches, such as training a class-agnostic Mask R-CNN, while ignoring mask losses for any instances that don’t have mask labels, have not worked well. For example, on the typical “VOC/Non-VOC” benchmark, where one trains on masks for a subset of 20 classes in COCO (called “seen classes”) and is tested on the remaining 60 classes (called “unseen classes”), a typical Mask R-CNN with Resnet-50 backbone gets to only ~18% mask mAP (mean Average Precision, higher is better) on unseen classes, whereas when fully supervised it can achieve a much higher >34% mask mAP on the same set.
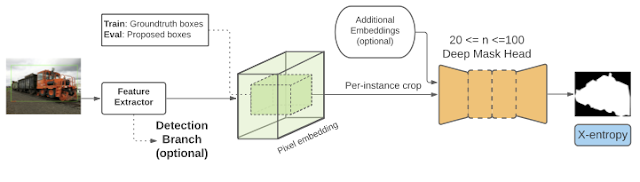
In “The surprising impact of mask-head architecture on novel class segmentation”, to be presented at ICCV 2021, we identify the main culprits for Mask R-CNN’s poor performance on novel classes and propose two easy-to-implement fixes (one training protocol fix, one mask-head architecture fix) that work in tandem to close the gap to fully supervised performance. We show that our approach applies generally to crop-then-segment models, i.e., a Mask R-CNN or Mask R-CNN-like architecture that computes a feature representation of the entire image and then subsequently passes per-instance crops to a second-stage mask prediction network—also called a mask-head network. Putting our findings together, we propose a Mask R-CNN–based model that improves over the current state-of-the-art by a significant 4.7% mask mAP without requiring more complex auxiliary loss functions, offline trained priors, or weight transfer functions proposed by previous work. We have also open sourced the code bases for two versions of the model, called Deep-MAC and Deep-MARC, and published a colab to interactively produce masks like the video demo below.
| A demo of our model, DeepMAC, which learns to predict accurate masks, given user specified boxes, even on novel classes that were not seen at training time. Try it yourself in the colab. Image credits: Chris Briggs, Wikipedia and Europeana. |
Impact of Cropping Methodology in Partially Supervised Settings
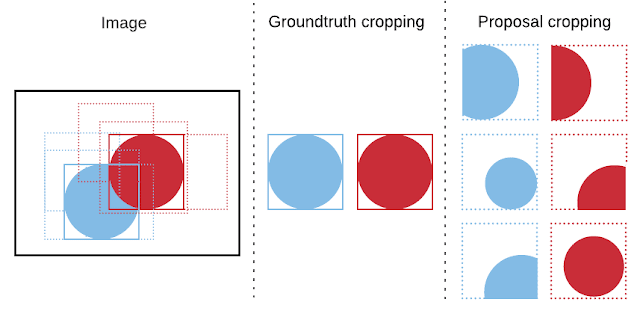
An important step of crop-then-segment models is cropping—Mask R-CNN is trained by cropping a feature map as well as the ground truth mask to a bounding box corresponding to each instance. These cropped features are passed to another neural network (called a mask-head network) that computes a final mask prediction, which is then compared against the ground truth crop in the mask loss function. There are two choices for cropping: (1) cropping directly to the ground truth bounding box of an instance, or (2) cropping to bounding boxes predicted by the model (called, proposals). At test time, cropping is always performed with proposals as ground truth boxes are not assumed to be available.
 |
| Cropping to ground truth boxes vs. cropping to proposals predicted by a model during training. Standard Mask R-CNN implementations use both types of crops, but we show that cropping exclusively to ground truth boxes yields significantly stronger performance on novel categories. |
 |
| We consider a general family of Mask R-CNN–like architectures with one small, but critical difference from typical Mask R-CNN training setups: we crop using ground truth boxes (instead of proposal boxes) at training time. |
Typical Mask R-CNN implementations pass both types of crops to the mask head. However, this choice has traditionally been considered an unimportant implementation detail, because it does not affect performance significantly in the fully supervised setting. In contrast, for partially supervised settings, we find that cropping methodology plays a significant role—while cropping exclusively to ground truth boxes during training doesn’t change the results significantly in the fully supervised setting, it has a surprising and dramatic positive impact in the partially supervised setting, performing significantly better on unseen classes.
 |
| Performance of Mask R-CNN on unseen classes when trained with either proposals and ground truth (the default) or with only ground truth boxes. Training mask heads with only ground truth boxes yields a significant boost to performance on unseen classes, upwards of 9% mAP. We report performance with the ResNet-101-FPN backbone. |
Unlocking the Full Generalization Potential of the Mask Head
Even more surprisingly, the above approach unlocks a novel phenomenon—with cropping-to-ground truth enabled during training, the mask head of Mask R-CNN takes on a disproportionate role in the ability of the model to generalize to unseen classes. As an example, in the following figure, we compare models that all have cropping-to-ground-truth enabled, but different out-of-the-box mask-head architectures on a parking meter, cell phone, and pizza (classes unseen during training).
 |
| Mask predictions for unseen classes with four different mask-head architectures (from left to right: ResNet-4, ResNet-12, ResNet-20, Hourglass-20, where the number refers to the number of layers of the neural network). Despite never having seen masks from the ‘parking meter’, ‘pizza’ or ‘mobile phone’ class, the rightmost mask-head architecture can segment these classes correctly. From left to right, we show better mask-head architectures predicting better masks. Moreover, this difference is only apparent when evaluating on unseen classes — if we evaluate on seen classes, all four architectures exhibit similar performance. |
Particularly notable is that these differences between mask-head architectures are not as obvious in the fully supervised setting. Incidentally, this may explain why previous works in instance segmentation have almost exclusively used shallow (i.e., low number of layers) mask heads, as there has been no benefit to the added complexity. Below we compare the mask mAP of three different mask-head architectures on seen versus unseen classes. All three models do equally well on the set of seen classes, but the deep hourglass mask heads stand out when applied to unseen classes. We find hourglass mask heads to be the best among the architectures we tried and we use hourglass mask heads with 50 or more layers to get the best results.
 |
| Performance of ResNet-4, Hourglass-10 and Hourglass-52 mask-head architectures on seen and unseen classes. There is a significant difference in performance on unseen classes, even though the performance on seen classes barely changes. |
Finally, we show that our findings are general, holding for a variety of backbones (e.g., ResNet, SpineNet, Hourglass) and detector architectures including anchor-based and anchor-free detectors and even when there is no detector at all.
Putting It Together
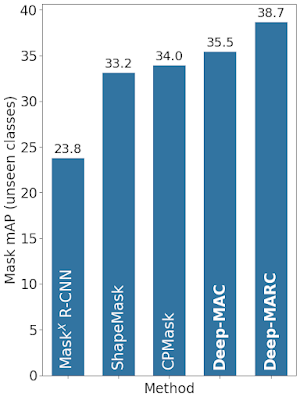
To achieve the best result, we combined the above findings: We trained a Mask R-CNN model with cropping-to-ground-truth enabled and a deep Hourglass-52 mask head with a SpineNet backbone on high resolution images (1280x1280). We call this model Deep-MARC (Deep Mask heads Above R-CNN). Without using any offline training or other hand-crafted priors, Deep-MARC exceeds previous state-of-the-art models by > 4.5% (absolute) mask mAP. Demonstrating the general nature of this approach, we also see strong results with a CenterNet-based (as opposed to Mask R-CNN-based) model (called Deep-MAC), which also exceeds the previous state of the art.
 |
| Comparison of Deep-MAC and Deep-MARC to other partially supervised instance segmentation approaches like MaskX R-CNN, ShapeMask and CPMask. |
Conclusion
We develop instance segmentation models that are able to generalize to classes that were not part of the training set. We highlight the role of two key ingredients that can be applied to any crop-then-segment model (such as Mask R-CNN): (1) cropping-to-ground truth boxes during training, and (2) strong mask-head architectures. While neither of these ingredients have a large impact on the classes for which masks are available during training, employing both leads to significant improvement on novel classes for which masks are not available during training. Moreover, these ingredients are sufficient for achieving state-of-the-art-performance on the partially-supervised COCO benchmark. Finally, our findings are general and may also have implications for related tasks, such as panoptic segmentation and pose estimation.
Acknowledgements
We thank our co-authors Zhichao Lu, Siyang Li, and Vivek Rathod. We thank David Ross and our anonymous ICCV reviewers for their comments which played a big part in improving this research.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence