Recursive Classification: Replacing Rewards with Examples in RL
March 24, 2021
Posted by Benjamin Eysenbach, Student Researcher, Google Research
Quick links
A general goal of robotics research is to design systems that can assist in a variety of tasks that can potentially improve daily life. Most reinforcement learning algorithms for teaching agents to perform new tasks require a reward function, which provides positive feedback to the agent for taking actions that lead to good outcomes. However, actually specifying these reward functions can be quite tedious and can be very difficult to define for situations without a clear objective, such as whether a room is clean or if a door is sufficiently shut. Even for tasks that are easy to describe, actually measuring whether the task has been solved can be difficult and may require adding many sensors to a robot's environment.
Alternatively, training a model using examples, called example-based control, has the potential to overcome the limitations of approaches that rely on traditional reward functions. This new problem statement is most similar to prior methods based on "success detectors", and efficient algorithms for example-based control could enable non-expert users to teach robots to perform new tasks, without the need for coding expertise, knowledge of reward function design, or the installation of environmental sensors.
In "Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification," we propose a machine learning algorithm for teaching agents how to solve new tasks by providing examples of success (e.g., if “success” examples show a nail embedded into a wall, the agent will learn to pick up a hammer and knock nails into the wall). This algorithm, recursive classification of examples (RCE), does not rely on hand-crafted reward functions, distance functions, or features, but rather learns to solve tasks directly from data, requiring the agent to learn how to solve the entire task by itself, without requiring examples of any intermediate states. Using a version of temporal difference learning — similar to Q-learning, but replacing the typical reward function term using only examples of success — RCE outperforms prior approaches based on imitation learning on simulated robotics tasks. Coupled with theoretical guarantees similar to those for reward-based learning, the proposed method offers a user-friendly alternative for teaching robots new tasks.
 |
 |
| Top: To teach a robot to hammer a nail into a wall, most reinforcement learning algorithms require that the user define a reward function. Bottom: The example-based control method uses examples of what the world looks like when a task is completed to teach the robot to solve the task, e.g., examples where the nail is already hammered into the wall. |
Example-Based Control vs Imitation Learning
While the example-based control method is similar to imitation learning, there is an important distinction — it does not require expert demonstrations. In fact, the user can actually be quite bad at performing the task themselves, as long as they can look back and pick out the small fraction of states where they did happen to solve the task.
Additionally, whereas previous research used a stage-wise approach in which the model first uses success examples to learn a reward function and then applies that reward function with an off-the-shelf reinforcement learning algorithm, RCE learns directly from the examples and skips the intermediate step of defining the reward function. Doing so avoids potential bugs and bypasses the process of defining the hyperparameters associated with learning a reward function (such as how often to update the reward function or how to regularize it) and, when debugging, removes the need to examine code related to learning the reward function.
Recursive Classification of Examples
The intuition behind the RCE approach is simple: the model should predict whether the agent will solve the task in the future, given the current state of the world and the action that the agent is taking. If there were data that specified which state-action pairs lead to future success and which state-action pairs lead to future failure, then one could solve this problem using standard supervised learning. However, when the only data available consists of success examples, the system doesn’t know which states and actions led to success, and while the system also has experience interacting with the environment, this experience isn't labeled as leading to success or not.
 |
| Left: The key idea is to learn a future success classifier that predicts for every state (circle) in a trajectory whether the task will be solved in the future (thumbs up/down). Right: In the example-based control approach, the model is provided only with unlabeled experience (grey circles) and success examples (green circles), so one cannot apply standard supervised learning. Instead, the model uses the success examples to automatically label the unlabeled experience. |
Nonetheless, one can piece together what these data would look like, if it were available. First, by definition, a successful example must be one that solves the given task. Second, even though it is unknown whether an arbitrary state-action pair will lead to success in solving a task, it is possible to estimate how likely it is that the task will be solved if the agent started at the next state. If the next state is likely to lead to future success, it can be assumed that the current state is also likely to lead to future success. In effect, this is recursive classification, where the labels are inferred based on predictions at the next time step.
The underlying algorithmic idea of using a model's predictions at a future time step as a label for the current time step closely resembles existing temporal-difference methods, such as Q-learning and successor features. The key difference is that the approach described here does not require a reward function. Nonetheless, we show that this method inherits many of the same theoretical convergence guarantees as temporal difference methods. In practice, implementing RCE requires changing only a few lines of code in an existing Q-learning implementation.
Evaluation
We evaluated the RCE method on a range of challenging robotic manipulation tasks. For example, in one task we required a robotic hand to pick up a hammer and hit a nail into a board. Previous research into this task [1, 2] have used a complex reward function (with terms corresponding to the distance between the hand and the hammer, the distance between the hammer and the nail, and whether the nail has been knocked into the board). In contrast, the RCE method requires only a few observations of what the world would look like if the nail were hammered into the board.
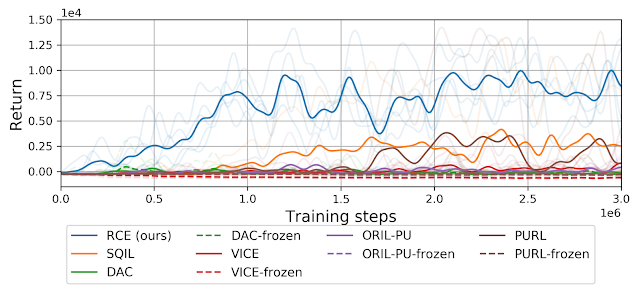
We compared the performance of RCE to a number of prior methods, including those that learn an explicit reward function and those based on imitation learning , all of which struggle to solve this task. This experiment highlights how example-based control makes it easy for users to specify even complex tasks, and demonstrates that recursive classification can successfully solve these sorts of tasks.
 |
| Compared with prior methods, the RCE approach solves the task of hammering a nail into a board more reliably that prior approaches based on imitation learning [SQIL, DAC] and those that learn an explicit reward function [VICE, ORIL, PURL]. |
Conclusion
We have presented a method to teach autonomous agents to perform tasks by providing them with examples of success, rather than meticulously designing reward functions or collecting first-person demonstrations. An important aspect of example-based control, which we discuss in the paper, is what assumptions the system makes about the capabilities of different users. Designing variants of RCE that are robust to differences in users' capabilities may be important for applications in real-world robotics. The code is available, and the project website contains additional videos of the learned behaviors.
Acknowledgements
We thank our co-authors, Ruslan Salakhutdinov and Sergey Levine. We also thank Surya Bhupatiraju, Kamyar Ghasemipour, Max Igl, and Harini Kannan for feedback on this post, and Tom Small for helping to design figures for this post.
-
Labels:
- Robotics
Quick links
Other posts of interest
-

August 29, 2023
SayTap: Language to quadrupedal locomotion- Machine Intelligence ·
- Robotics
-

August 22, 2023
Language to rewards for robotic skill synthesis- Machine Intelligence ·
- Robotics
-

May 26, 2023
Barkour: Benchmarking animal-level agility with quadruped robots- Hardware & Architecture ·
- Machine Intelligence ·
- Robotics