
Real-time speech-to-speech translation
November 19, 2025
Karolis Misiunas, Research Engineer, Google DeepMind, and Artsiom Ablavatski, Software Engineer, Google Core ML
We introduce an innovative end-to-end speech-to-speech translation (S2ST) model that enables real-time translation in the original speaker's voice with only a 2-second delay — bringing long-imagined technology into reality and making cross-language communication more natural.
Real-time communication is an integral part of both our professional and personal lives. When speaking to people remotely across language barriers, it can be difficult to truly connect by just relying on state-of-the-art translated captions, as they lack personality and real-time responsiveness essential for fluid conversation. The arrival of speech-to-speech translation (S2ST) bridges this gap by directly generating translated audio, leading to more natural communication. Existing speech-to-speech translation systems often incur significant delays (4–5s), tend to accumulate errors, and typically lack personalization.
Today we describe an innovative end-to-end S2ST model that overcomes these limitations, enabling live translation in the original speaker's voice with only 2 second delay. The novel architecture leverages a streaming framework and, with training on time-synchronized data, significantly reduces the delay between the original input and the translated speech. To support a breadth of languages, we introduce a scalable time-synced data acquisition pipeline that allows us to gradually expand the system to include more languages. This technology has demonstrated its effectiveness through successful deployment in real-time sensitive use cases.
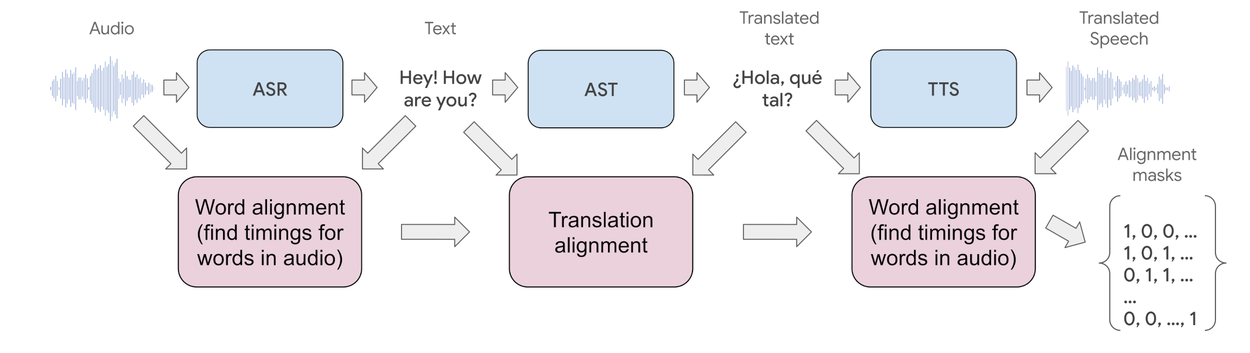
Cascaded S2ST
Prior real-time speech-to-speech technologies employed a cascaded pipeline of individual processing blocks:
- Firstly, the source audio is transcribed to text using automatic speech recognition (ASR) AI models.
- Next, the transcribed text is translated word-for-word to the target language using automatic speech translation (AST).
- Finally, the translated text is converted back to audio using text-to-speech pipelines (TTS).

Schematic representation of classic, cascade-style speech-to-speech translation system.
Despite the high quality of the individual cascade components, achieving a seamless, real-time S2ST experience has been challenging due to three primary factors:
- Significant delays of 4–5 seconds, forcing turn-based conversations.
- Accumulated errors at each stage of the translation process.
- A notable lack of personalization due to the general-purpose TTS technology.
A novel end-to-end, personalized S2ST
To significantly advance S2ST, we created a scalable data acquisition pipeline and developed an end-to-end model that provides direct, real-time language translation with just a two-second delay:
- Scalable data acquisition pipeline: We created a data processing pipeline to convert raw audio into a time-synchronized input/target dataset. This was achieved by integrating existing ASR and TTS technologies with precise alignment steps, ensuring translated audio best matches the input. Rigorous filtering and validation were employed to remove difficult-to-align examples.
- Real-time speech-to-speech translation architecture: We introduced an audio-specific streaming machine learning architecture to support training on this time-synchronized data. Building on the AudioLM framework and fundamental transformer blocks, this architecture is designed to handle continuous audio streams, allowing the model to decide when to output translations. It is also structured to manage hierarchical audio representations using the SpectroStream codec technology.
| An example of our personalized S2ST applied to a Spanish original translated to English. |
Scalable data acquisition pipeline
For a given language pair, initial work starts with raw audio acquisition. We utilize a diverse set of audio sources, including data generated by TTS models. This audio undergoes a cleaning and filtering process to ensure it contains a single speaker of the source language and has an appropriate noise level. After initial data collection, an ASR step transcribes the source text. With both source audio and text available, the forced alignment algorithm generates alignment timesteps (audio-to-text mapping). Any audio segments where alignment fails are discarded.
The remaining clips are machine translated from the source into the target language. Subsequently, a series of automated filters validate the translated output, ensuring accuracy and correspondence to the input text. Next, the original transcribed and translated texts are also aligned to generate corresponding timestamp annotations (text-to-translated text mapping).
Using a custom text-to-speech generation engine, the translated text is converted into translated audio, preserving the voice characteristics from the original audio while producing natural-sounding output. The pipeline concludes with one more forced alignment step of the translated text and the generated speech (speech-to-text mapping).
Streaming audio-to-audio translation dataset generation.
Utilizing the three generated alignments from the previous steps, the overlap between them is calculated, yielding alignment masks between the source and target audio. These alignment masks are then used to guide the loss computation during training.


Text alignment of input and translated audio with corresponding overlaps.
Invalid overlaps or translations that fail to meet delay requirements are filtered from the training dataset. The remaining aligned data is used to train the streaming S2ST model in chunks of up to 60 seconds. Various audio augmentation techniques are also applied during training, including sample rate reduction, reverberation, saturation, and denoising.
Real-time speech-to-speech translation architecture
The end-to-end S2ST model leverages fundamental transformer blocks and consists of two main components:
- Streaming encoder: Summarizes source audio data based on the preceding 10 seconds of input.
- Streaming decoder: Predicts translated audio autoregressively, using the compressed encoder state and predictions from previous iterations.
A feature of these models is their representation of audio as a 2D set of tokens, known as RVQ audio tokens. As shown below, the X-axis represents time, while the Y-axis represents a set of tokens that describe the current audio segment. When summed, all tokens in a specific set can be readily converted into an audio stream using an ML codec. The number of tokens controls the audio quality for every segment, with more tokens yielding higher fidelity. The model predicts tokens sequentially, prioritizing those at the beginning. Typically, 16 tokens are sufficient for high-quality audio representation of a 100 ms chunk.

Schematic representation of audio-to-audio streaming inference for S2ST.
The model outputs a single text token in addition to the audio tokens. This text token acts as an extra prior for audio generation and enables direct metric calculation (BLEU) without relying on proxy ASR systems.
During training, a per-token loss is applied to the model to ensure accurate translation. The model's prediction delay, or lookahead, can be adjusted by shifting ground truth tokens to the right, allowing for flexibility based on the target language's complexity. For real-time conversations, a standard 2-second delay is typically used, which is suitable for most languages. While a longer lookahead improves translation quality by providing more context, it negatively impacts the real-time communication experience.

Ablation of lookahead and corresponding quality of translation for Spanish / English language pair (BLEU, higher is better).
In addition to the internal 2 second delay, the model's inference time contributes to the overall system latency. To minimize this and achieve real-time performance, we implemented several optimization techniques, including hybrid low-bit (int8 and int4) quantization and optimized CFG precomputation.
The examples of translation for different language pairs with developed models with corresponding ground truth (taken from publicly available CVSS dataset) follow:
|
Direction |
Input audio |
Translated audio |
Ground truth |
|
Spanish to English |
In coastal areas there is a larger accumulation of water molecules in the air. |
||
|
English to Spanish |
Su portaaviones insignia, el Portaviones Formidable fue tocado por un kamikaze sin gravísimas consecuencias. |
||
|
German to English |
The electrician used a piece of aluminum foil to splice the fuse. |
||
|
English to German |
Margaret versucht mit allen Mitteln, die bevorstehende Katastrophe zu verhindern. |
||
|
Italian to English |
By clicking on the right, on the bell icon, you can activate Pash notifications so that they are updated in real time. |
||
|
English to Italian |
La voce popolare parla dei proprietari terrieri, dei mafiosi e dei rappresentanti del Partito conservatore e dei loro nomi, che sono noti a tutti. |
||
|
Portuguese to English |
This text is made available under the respective license. |
||
|
English to Portuguese |
Um homem de camisa azul observa algo projetado na frente dele. |
||
|
French to English |
The volunteer firefighters are a full part of our civil security arsenal. |
||
|
English to French |
|
|
Ce gouvernement et cette majorité portent donc seuls la responsabilité de cette situation. |
| Exemplar bidirectional translation generated by the trained models for English, Spanish, German, Italian, Portuguese, and French languages with corresponding ground truth. |
Real-world applications
The new end-to-end S2ST technology has been launched in two key areas, highlighting the importance of real-time cross-language communication. It is now available in Google Meet on servers, and as a built-in on-device feature for the new Pixel 10 devices. Although the products utilize different strategies for running the S2ST pipeline, they share training data and model architecture. The Pixel Voice Translate on-device feature also employs a cascade approach to maximize language coverage. To mitigate potential feature misuse, prior to each translation session, we inform the end-user that the translation is synthetically generated.
The new end-to-end S2ST technology enables Google Meet speech translation feature.
The current end-to-end model delivers robust performance for five Latin-based language pairs (English to and from Spanish, German, French, Italian, Portuguese), enabling our initial product launches. We are also observing promising capabilities in other languages, such as Hindi, that we plan to develop further. Future enhancements will focus on improving the dynamism of the model's lookahead. This will enable the S2ST technology to seamlessly adjust to languages with word orders significantly different from English, facilitating more contextual rather than literal word-for-word translation.
We believe that this breakthrough in S2ST technology will revolutionize real-time, cross-language communication, turning a long-envisioned concept into reality.
Acknowledgements
We are sincerely grateful to everyone who contributed to this project; their critical contributions were instrumental in making it a reality. We are particularly thankful to our colleagues Kevin Kilgour, Pen Li, Félix de Chaumont Quitry, Michael Dooley, Jeremy Thorpe, Mihajlo Velimirović, Alex Tudor, Christian Frank, Daniel Johansson, Hanna Silén, Christian Schuldt, Henrik Lundin, Esbjörn Dominique, Marcus Wirebrand, Daniel Kallander, Pablo Barrera González, Huib Kleinhout, Niklas Blum, Fredric Lindstrom, Esha Uboweja, Karthik Raveendran, Frédéric Rechtenstein, Xing Li, Queenie Zhang, Cheng Yang, Jason Fan, Matsvei Zhdanovich, Jianing Wei, and Matthias Grundmann.
-
Labels:
- Algorithms & Theory
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 31, 2026
Safeguarding cryptocurrency by disclosing quantum vulnerabilities responsibly- Algorithms & Theory ·
- Quantum ·
- Security, Privacy and Abuse Prevention
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence




