Introducing Translatotron: An End-to-End Speech-to-Speech Translation Model
May 15, 2019
Posted by Ye Jia and Ron Weiss, Software Engineers, Google AI
Quick links
Speech-to-speech translation systems have been developed over the past several decades with the goal of helping people who speak different languages to communicate with each other. Such systems have usually been broken into three separate components: automatic speech recognition to transcribe the source speech as text, machine translation to translate the transcribed text into the target language, and text-to-speech synthesis (TTS) to generate speech in the target language from the translated text. Dividing the task into such a cascade of systems has been very successful, powering many commercial speech-to-speech translation products, including Google Translate.
In “Direct speech-to-speech translation with a sequence-to-sequence model”, we propose an experimental new system that is based on a single attentive sequence-to-sequence model for direct speech-to-speech translation without relying on intermediate text representation. Dubbed Translatotron, this system avoids dividing the task into separate stages, providing a few advantages over cascaded systems, including faster inference speed, naturally avoiding compounding errors between recognition and translation, making it straightforward to retain the voice of the original speaker after translation, and better handling of words that do not need to be translated (e.g., names and proper nouns).
Translatotron
The emergence of end-to-end models on speech translation started in 2016, when researchers demonstrated the feasibility of using a single sequence-to-sequence model for speech-to-text translation. In 2017, we demonstrated that such end-to-end models can outperform cascade models. Many approaches to further improve end-to-end speech-to-text translation models have been proposed recently, including our effort on leveraging weakly supervised data. Translatotron goes a step further by demonstrating that a single sequence-to-sequence model can directly translate speech from one language into speech in another language, without relying on an intermediate text representation in either language, as is required in cascaded systems.
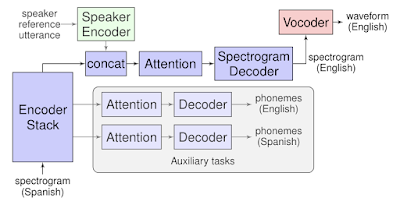
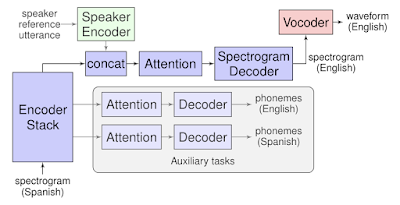
Translatotron is based on a sequence-to-sequence network which takes source spectrograms as input and generates spectrograms of the translated content in the target language. It also makes use of two other separately trained components: a neural vocoder that converts output spectrograms to time-domain waveforms, and, optionally, a speaker encoder that can be used to maintain the character of the source speaker’s voice in the synthesized translated speech. During training, the sequence-to-sequence model uses a multitask objective to predict source and target transcripts at the same time as generating target spectrograms. However, no transcripts or other intermediate text representations are used during inference.
 |
| Model architecture of Translatotron. |
We validated Translatotron’s translation quality by measuring the BLEU score, computed with text transcribed by a speech recognition system. Though our results lag behind a conventional cascade system, we have demonstrated the feasibility of the end-to-end direct speech-to-speech translation.
Compared in the audio clips below are the direct speech-to-speech translation output from Translatotron to that of the baseline cascade method. In this case, both systems provide a suitable translation and speak naturally using the same canonical voice.
| Input (Spanish) | |
| Reference translation (English) | |
| Baseline cascade translation | |
| Translatotron translation |
You can listen to more audio samples here.
Preserving Vocal Characteristics
By incorporating a speaker encoder network, Translatotron is also able to retain the original speaker’s vocal characteristics in the translated speech, which makes the translated speech sound more natural and less jarring. This feature leverages previous Google research on speaker verification and speaker adaptation for TTS. The speaker encoder is pretrained on the speaker verification task, learning to encode speaker characteristics from a short example utterance. Conditioning the spectrogram decoder on this encoding makes it possible to synthesize speech with similar speaker characteristics, even though the content is in a different language.
The audio clips below demonstrate the performance of Translatotron when transferring the original speaker’s voice to the translated speech. In this example, Translatotron gives more accurate translation than the baseline cascade model, while being able to retain the original speaker’s vocal characteristics. The Translatotron output that retains the original speaker’s voice is trained with less data than the one using the canonical voice, so that they yield slightly different translations.
| Input (Spanish) | |
| Reference translation (English) | |
| Baseline cascade translation | |
| Translatotron translation (canonical voice) | |
| Translatotron translation (original speaker’s voice) |
More audio samples are available here.
Conclusion
To the best of our knowledge, Translatotron is the first end-to-end model that can directly translate speech from one language into speech in another language. It is also able to retain the source speaker’s voice in the translated speech. We hope that this work can serve as a starting point for future research on end-to-end speech-to-speech translation systems.
Acknowledgments
This research was a joint work between the Google Brain, Google Translate, and Google Speech teams. Contributors include Ye Jia, Ron J. Weiss, Fadi Biadsy, Wolfgang Macherey, Melvin Johnson, Zhifeng Chen, Mengmeng Niu, Quan Wang, Jason Pelecanos, Ignacio Lopez Moreno, Tom Walters, Heiga Zen, Patrick Nguyen, Yu Zhang, Jonathan Shen, Orhan Firat, and Yonghui Wu. We also thank Jorge Pereira and Stella Laurenzo for verifying the quality of the translation from Translatotron.
Quick links
Other posts of interest
-

December 3, 2025
From Waveforms to Wisdom: The New Benchmark for Auditory Intelligence- Machine Intelligence ·
- Sound & Accoustics ·
- Speech Processing
-

October 7, 2025
Speech-to-Retrieval (S2R): A new approach to voice search- Machine Intelligence ·
- Natural Language Processing ·
- Product ·
- Speech Processing
-

July 2, 2025
Making group conversations more accessible with sound localization- Human-Computer Interaction and Visualization ·
- Sound & Accoustics ·
- Speech Processing
×
❮
❯