Re-weighted gradient descent via distributionally robust optimization
September 28, 2023
Ramnath Kumar, Pre-Doctoral Researcher, and Arun Sai Suggala, Research Scientist, Google Research
Quick links
Deep neural networks (DNNs) have become essential for solving a wide range of tasks, from standard supervised learning (image classification using ViT) to meta-learning. The most commonly-used paradigm for learning DNNs is empirical risk minimization (ERM), which aims to identify a network that minimizes the average loss on training data points. Several algorithms, including stochastic gradient descent (SGD), Adam, and Adagrad, have been proposed for solving ERM. However, a drawback of ERM is that it weights all the samples equally, often ignoring the rare and more difficult samples, and focusing on the easier and abundant samples. This leads to suboptimal performance on unseen data, especially when the training data is scarce.
To overcome this challenge, recent works have developed data re-weighting techniques for improving ERM performance. One particularly fruitful approach in this line of work is the framework of distributionally robust optimization (DRO), where one aims to learn models that perform well even when the training data comes from a slightly different distribution than expected. Recent techniques such as TERM, RECOVER, ABSGD leverage this framework to develop effective data reweighting techniques.
In “Stochastic Re-weighted Gradient Descent via Distributionally Robust Optimization”, we build upon these techniques to introduce a variant of the classical SGD algorithm. Stochastic re-weighted gradient descent (RGD) re-weights data points during each optimization step based on their difficulty, while simultaneously performing weight clipping. RGD’s re-weighting scheme is simple and robust to outliers, and only has a single hyper-parameter that needs to be tuned. At any stage of the learning process, RGD simply reweights a data point as the exponential of its loss, and performs weight clipping to guard against outliers. RGD comes with a simple closed-form expression, and can be easily applied to solve any learning task using just two lines of code. We empirically demonstrate that the RGD algorithm improves the performance of numerous learning algorithms across various tasks, ranging from supervised learning to meta learning. Notably, we show improvements over state-of-the-art methods on DomainBed and Tabular classification. Moreover, the RGD algorithm also boosts performance for BERT using the GLUE benchmarks and ViT on ImageNet-1K.
Distributionally robust optimization
Distributionally robust optimization (DRO) is an approach that assumes a “worst-case” data distribution shift may occur, which can harm a model's performance. If a model has focussed on identifying few spurious features for prediction, these “worst-case” data distribution shifts could lead to the misclassification of samples and, thus, a performance drop. DRO optimizes the loss for samples in that “worst-case” distribution, making the model robust to perturbations (e.g., removing a small fraction of points from a dataset, minor up/down weighting of data points, etc.) in the data distribution. In the context of classification, this forces the model to place less emphasis on noisy features and more emphasis on useful and predictive features. Consequently, models optimized using DRO tend to have better generalization guarantees and stronger performance on unseen samples.
Inspired by these results, we develop the RGD algorithm as a technique for solving the DRO objective. Specifically, we focus on Kullback–Leibler divergence-based DRO, where one adds perturbations to create distributions that are close to the original data distribution in the KL divergence metric, enabling a model to perform well over all possible perturbations. Prior works such as TERM, ABSGD, RECOVER also rely on KL-DRO to develop their respective re-weighting schemes.
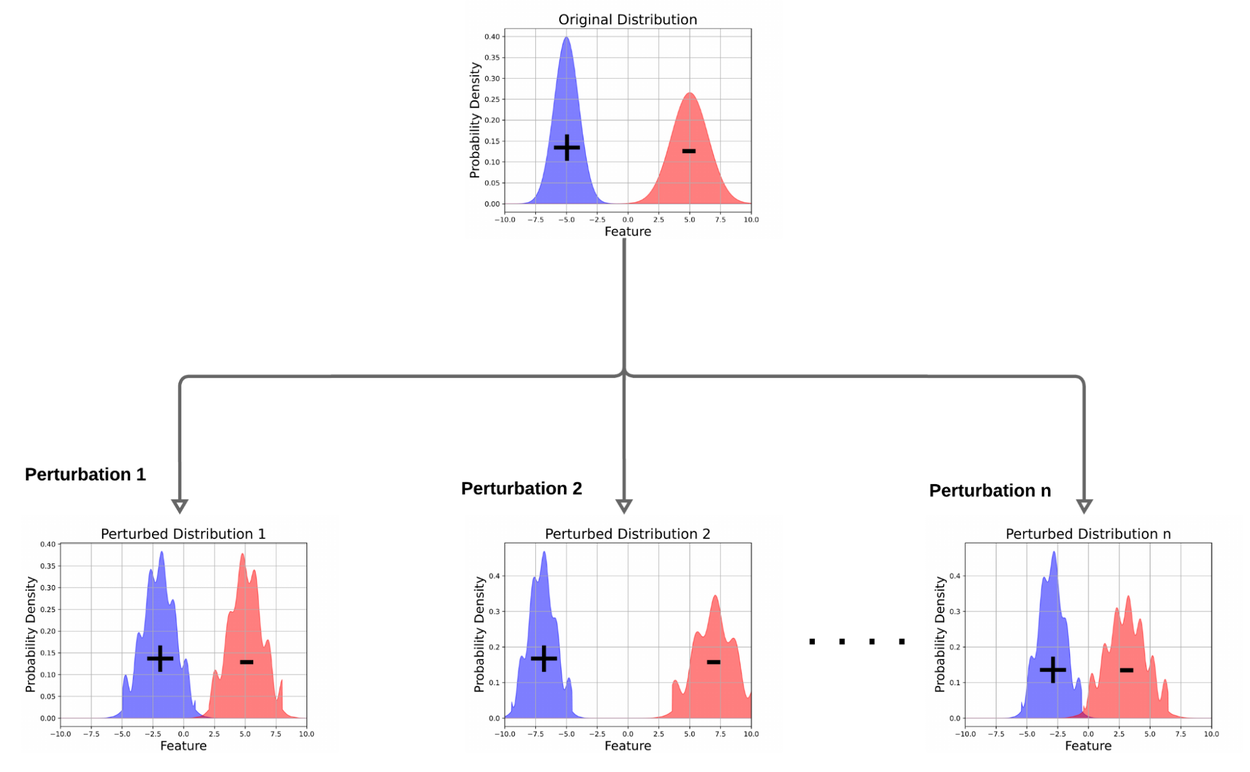
Figure illustrating DRO. In contrast to ERM, which learns a model that minimizes expected loss over original data distribution, DRO learns a model that performs well on several perturbed versions of the original data distribution.
Stochastic re-weighted gradient descent
Consider a random subset of samples (called a mini-batch), where each data point has an associated loss ℒi. Traditional algorithms like SGD give equal importance to all the samples in the mini-batch, and update the parameters of the model by descending along the averaged gradients of the loss of those samples. With RGD, we reweight each sample in the mini-batch and give more importance to points that the model identifies as more difficult. To be precise, we use the loss as a proxy to calculate the difficulty of a point, and reweight it by the exponential of its loss. Finally, we update the model parameters by descending along the weighted average of the gradients of the samples.
Due to stability considerations, in our experiments we clip and scale the loss before computing its exponential. Specifically, we clip the loss at some threshold T, and multiply it with a scalar that is inversely proportional to the threshold. An important aspect of RGD is its simplicity as it doesn’t rely on a meta model to compute the weights of data points. Furthermore, it can be implemented with two lines of code, and combined with any popular optimizers (such as SGD, Adam, and Adagrad.
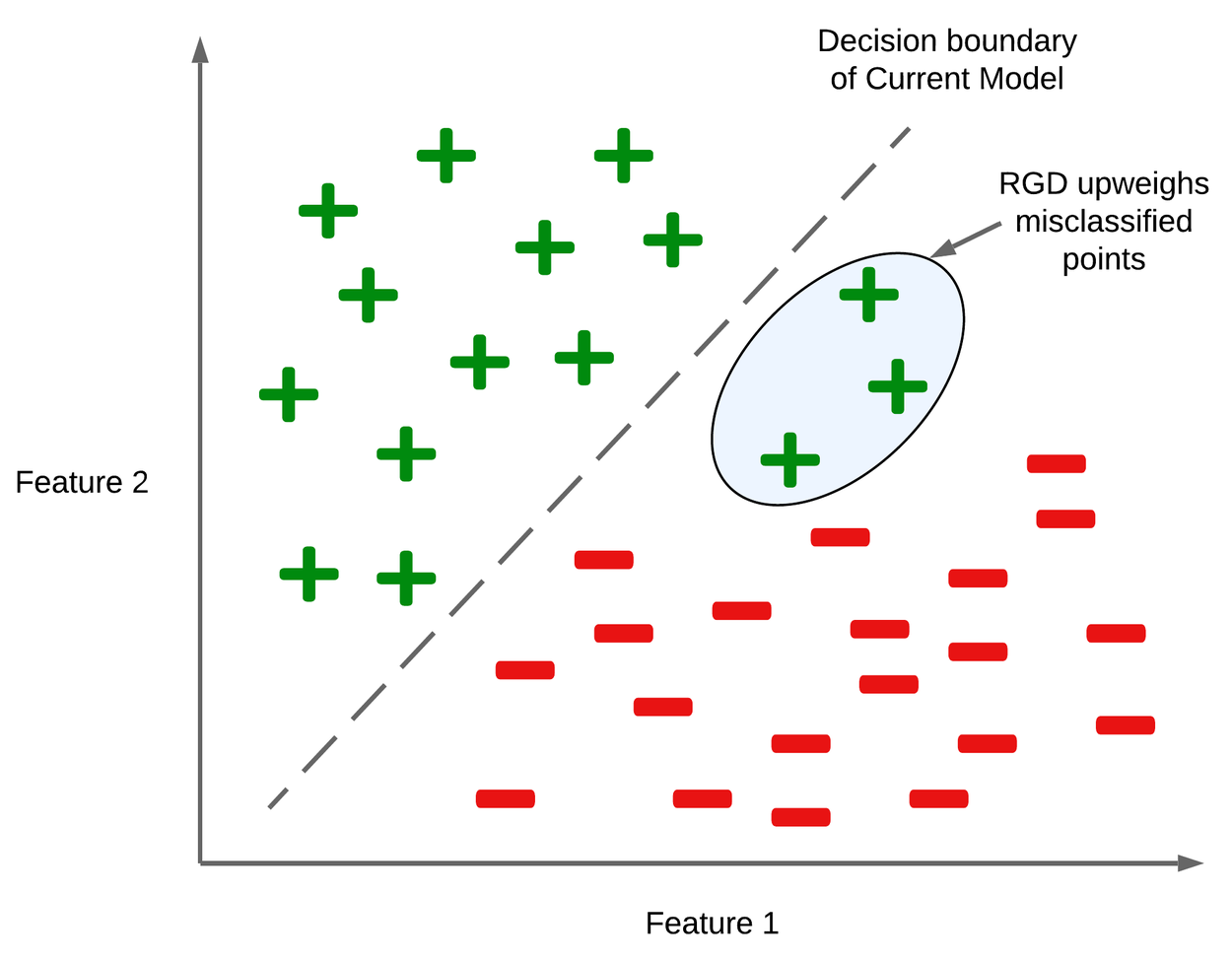
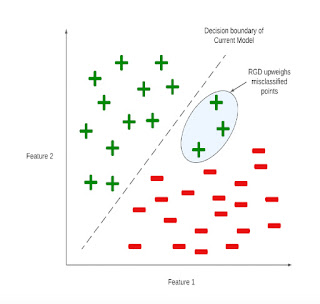
Figure illustrating the intuitive idea behind RGD in a binary classification setting. Feature 1 and Feature 2 are the features available to the model for predicting the label of a data point. RGD upweights the data points with high losses that have been misclassified by the model.
Results
We present empirical results comparing RGD with state-of-the-art techniques on standard supervised learning and domain adaptation (refer to the paper for results on meta learning). In all our experiments, we tune the clipping level and the learning rate of the optimizer using a held-out validation set.
Importance of weight clipping
We conducted experiments to investigate the impact of specific design choices in RGD. To understand the importance of weight clipping, we removed it from RGD, which resulted in at least a 1% drop in accuracy. This suggests that without clipping, outliers in the data can negatively influence the performance (see the dark blue line below). Further experiments confirmed that selecting an appropriate clipping factor is crucial for RGD's success.
We tested RGD with different values of the scale parameter (𝛄) (while keeping the clipping factor 𝝉 constant). Interestingly, RGD's performance remained relatively stable across various 𝛄 values. This indicates that the algorithm isn't overly sensitive to this particular parameter.
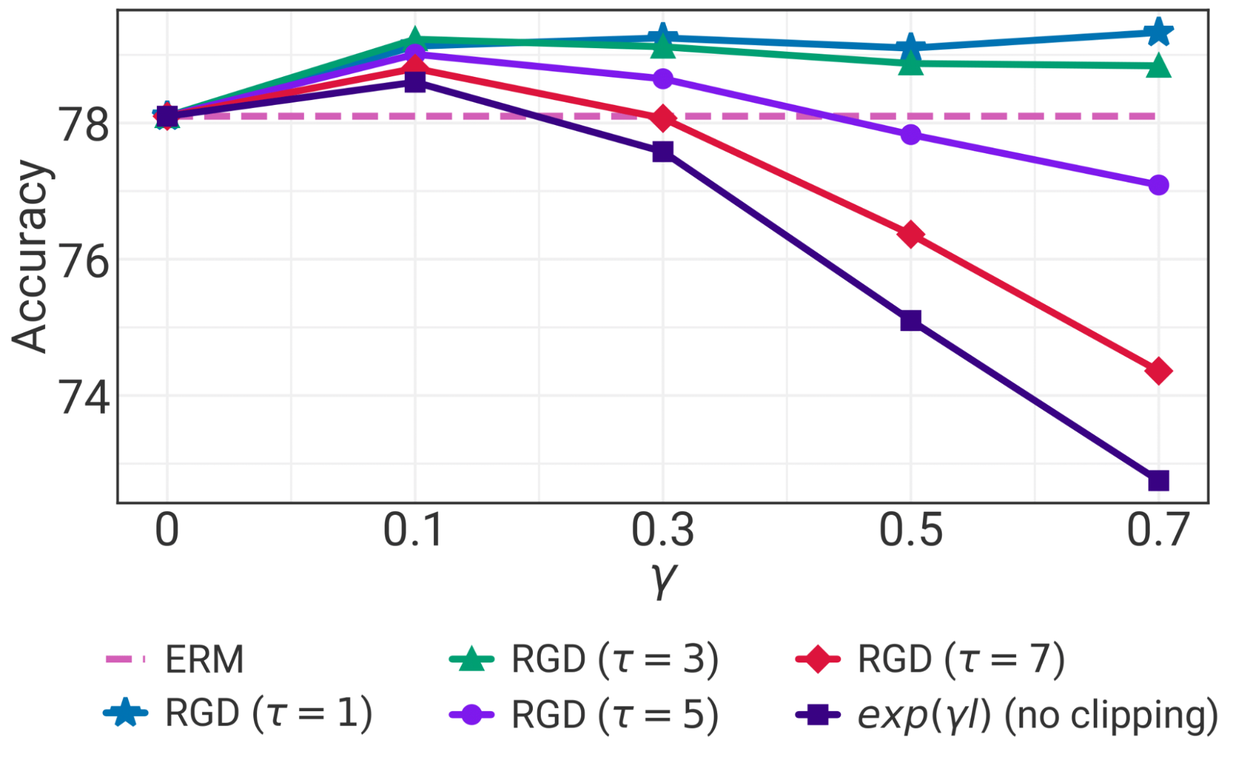
Ablation of scaling and clipping factor of RGD training regime on the Imagenet dataset with a ViT-S backbone.
Supervised learning
We evaluate RGD on several supervised learning tasks, including language, vision, and tabular classification. For the task of language classification, we apply RGD to the BERT model trained on the General Language Understanding Evaluation (GLUE) benchmark and show that RGD outperforms the BERT baseline by +1.94% with a standard deviation of 0.42%. To evaluate RGD’s performance on vision classification, we apply RGD to the ViT-S model trained on the ImageNet-1K dataset, and show that RGD outperforms the ViT-S baseline by +1.01% with a standard deviation of 0.23%. Moreover, we perform hypothesis tests to confirm that these results are statistically significant with a p-value that is less than 0.05.
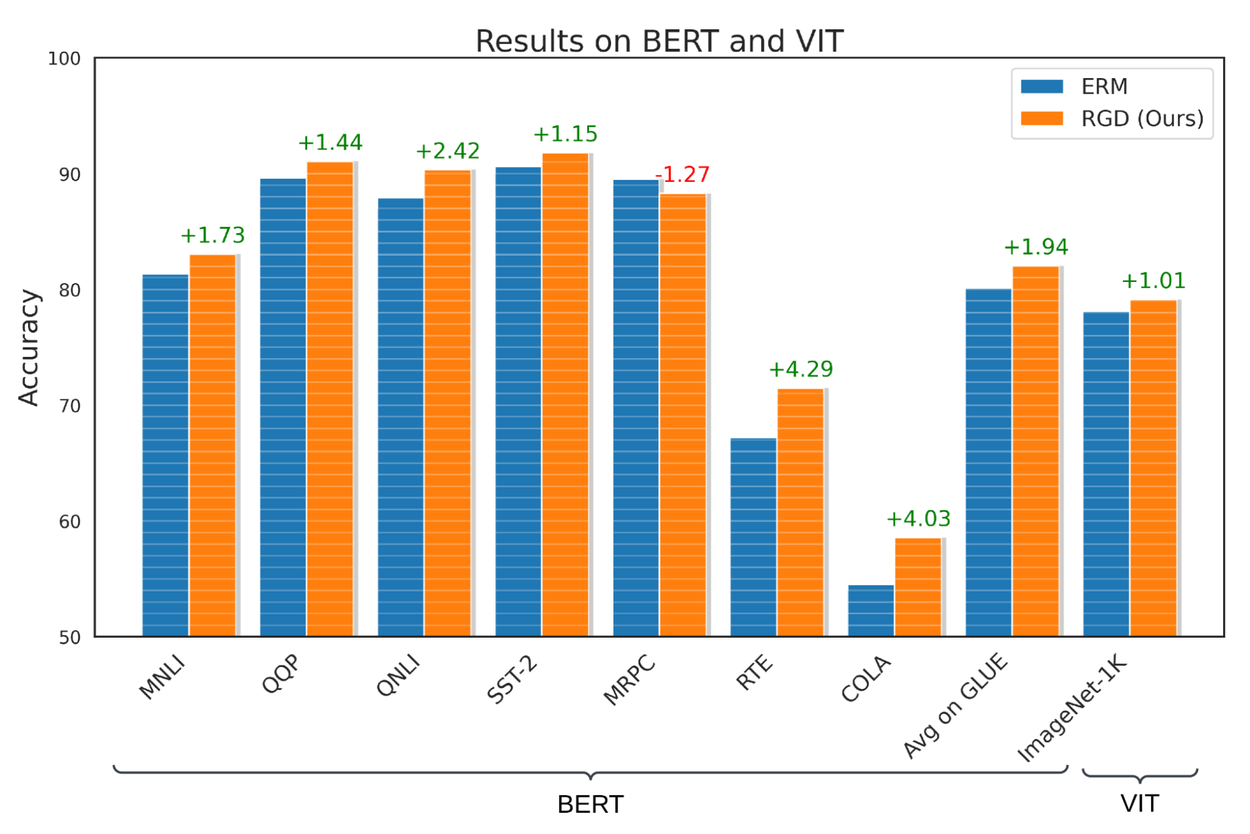
RGD’s performance on language and vision classification using GLUE and Imagenet-1K benchmarks. Note that MNLI, QQP, QNLI, SST-2, MRPC, RTE and COLA are diverse datasets which comprise the GLUE benchmark.
For tabular classification, we use MET as our baseline, and consider various binary and multi-class datasets from UC Irvine's machine learning repository. We show that applying RGD to the MET framework improves its performance by 1.51% and 1.27% on binary and multi-class tabular classification, respectively, achieving state-of-the-art performance in this domain.
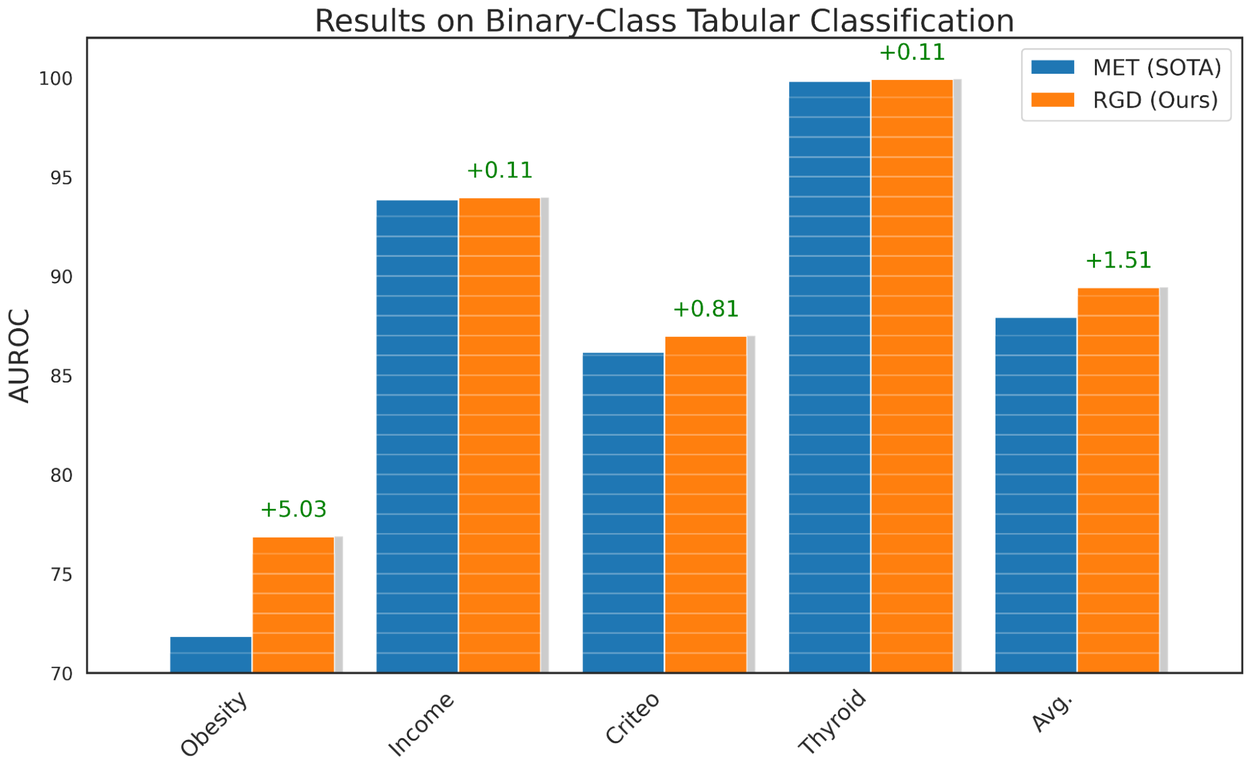
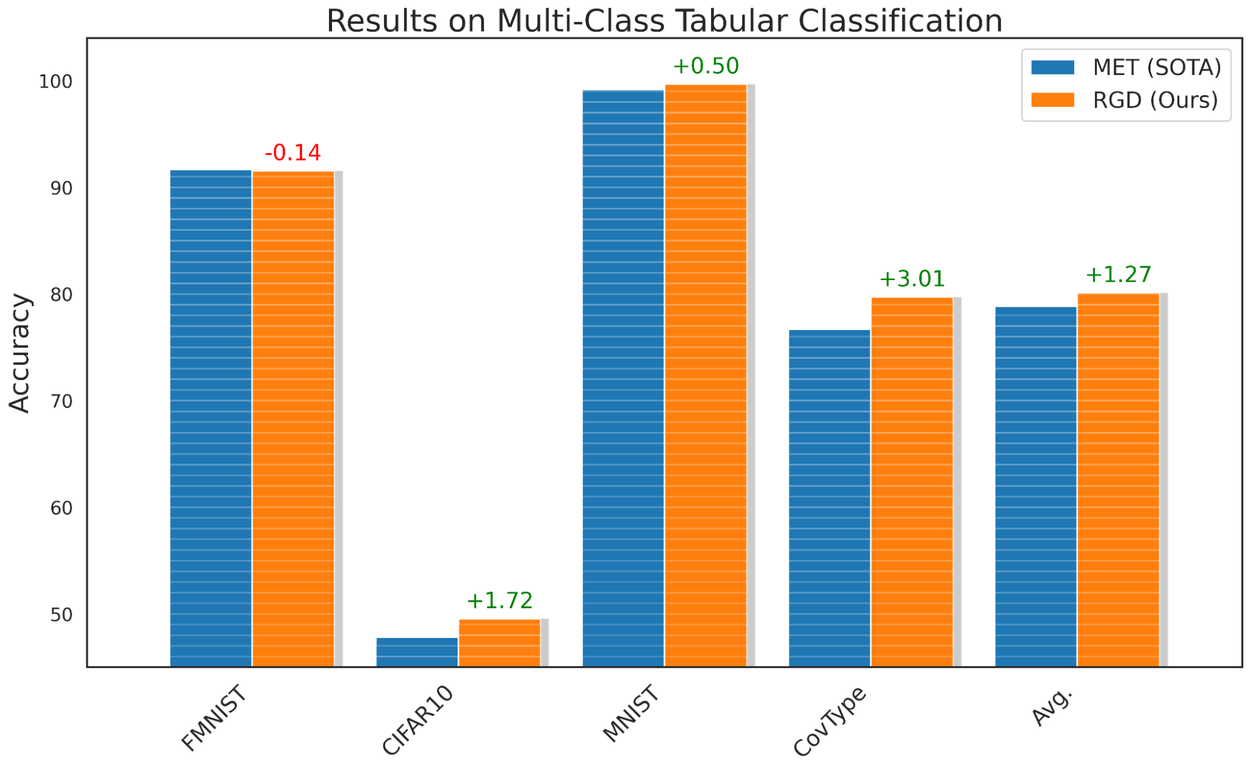
Performance of RGD for classification of various tabular datasets.
Domain generalization
To evaluate RGD’s generalization capabilities, we use the standard DomainBed benchmark, which is commonly used to study a model’s out-of-domain performance. We apply RGD to FRR, a recent approach that improved out-of-domain benchmarks, and show that RGD with FRR performs an average of 0.7% better than the FRR baseline. Furthermore, we confirm with hypothesis tests that most benchmark results (except for Office Home) are statistically significant with a p-value less than 0.05.
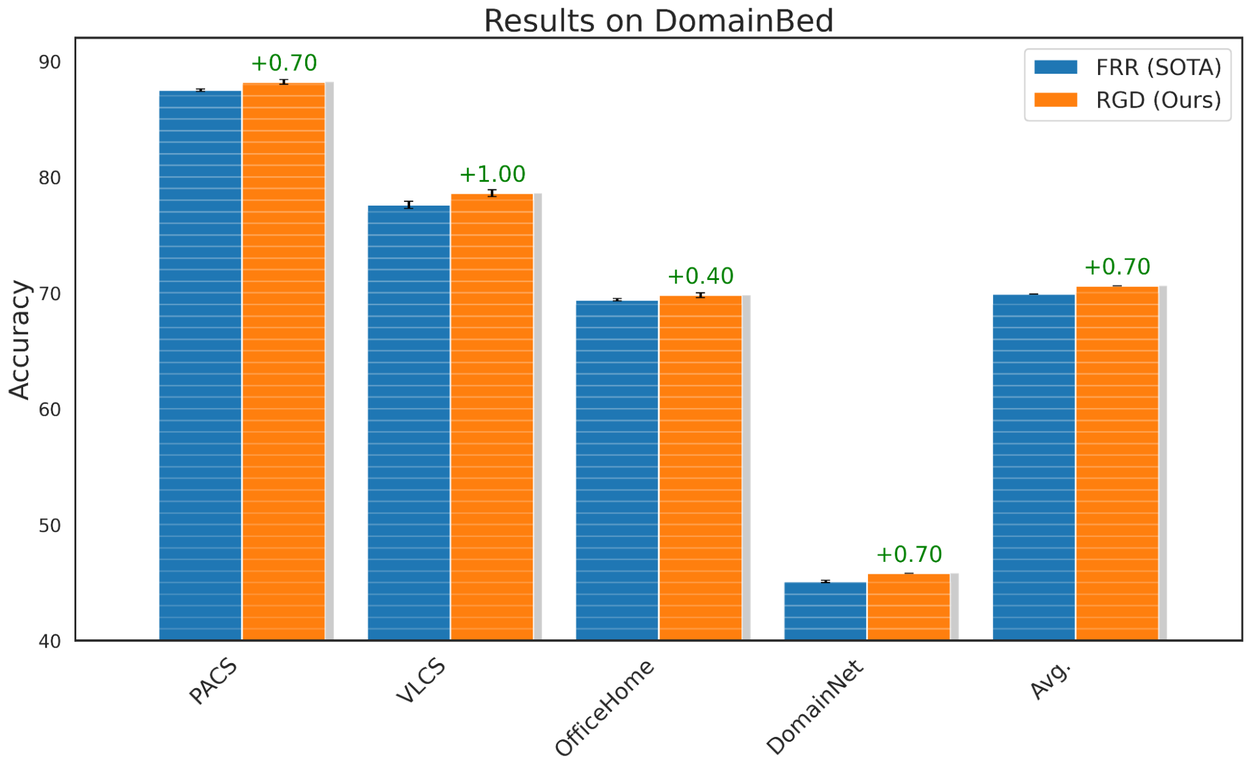
Performance of RGD on DomainBed benchmark for distributional shifts.
Class imbalance and fairness
To demonstrate that models learned using RGD perform well despite class imbalance, where certain classes in the dataset are underrepresented, we compare RGD’s performance with ERM on long-tailed CIFAR-10. We report that RGD improves the accuracy of baseline ERM by an average of 2.55% with a standard deviation of 0.23%. Furthermore, we perform hypothesis tests and confirm that these results are statistically significant with a p-value of less than 0.05.
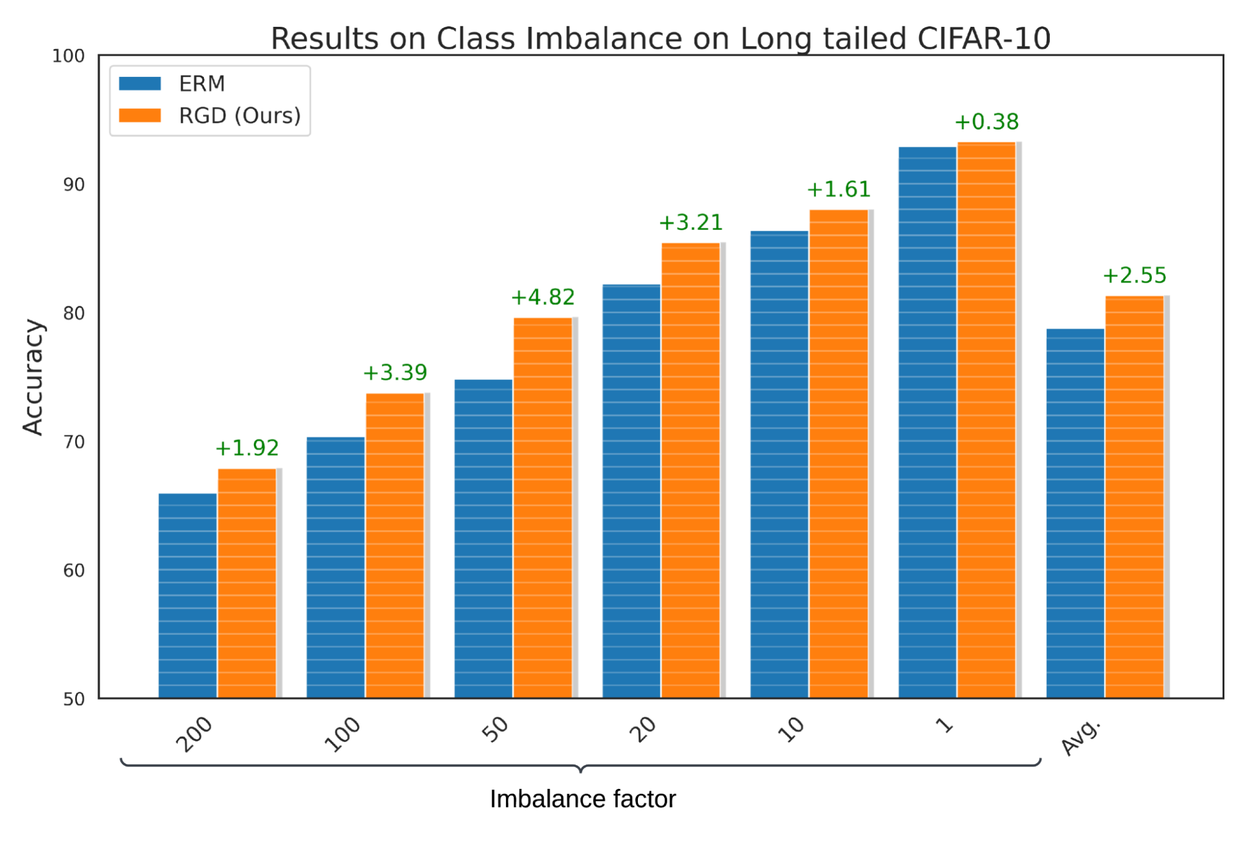
Performance of RGD on the long-tailed Cifar-10 benchmark for class imbalance domain.
Limitations
While weight clipping can help RGD withstand benign outliers, we believe it is not the best way to handle a large number of systematic or adversarial corruptions.. A potential approach to handle such scenarios is to apply an outlier removal technique to the RGD algorithm. This outlier removal technique should be capable of filtering out outliers from the mini-batch and sending the remaining points to our algorithm.
Conclusion
RGD has been shown to be effective on a variety of tasks, including out-of-domain generalization, tabular representation learning, and class imbalance. It is simple to implement and can be seamlessly integrated into existing algorithms with just two lines of code change. Overall, RGD is a promising technique for boosting the performance of DNNs, and could help push the boundaries in various domains.
Acknowledgements
The paper described in this blog post was written by Ramnath Kumar, Arun Sai Suggala, Dheeraj Nagaraj and Kushal Majmundar. We extend our sincere gratitude to Ahmad Beirami, Virginia Smith, Manzil Zaheer, Tian Li, and Maziar Sanjabi for their feedback on an earlier version of the blogpost. We also thank Prateek Jain, Pradeep Shenoy, Anshul Nasery, Lovish Madaan, the anonymous reviewers, and the numerous dedicated members of the machine learning and optimization team at Google Research India for their invaluable feedback and contributions to this work.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

July 7, 2026
The power of collaboration: How we can reduce traffic congestion- Algorithms & Theory ·
- Climate & Sustainability ·
- Data Mining & Modeling

Figure illustrating DRO. In contrast to ERM, which learns a model that minimizes expected loss over original data distribution, DRO learns a model that performs well on several perturbed versions of the original data distribution.






