Paper to Digital in 200+ languages
May 6, 2015
Posted by Dmitriy Genzel and Ashok Popat, Research Scientists and Dhyanesh Narayanan, Product Manager
Quick links
Many of the world’s important sources of information - books, newspapers, magazines, pamphlets, and historical documents - are not digital. Unlike digital documents, these paper-based sources of information are difficult to search through or edit, or worse, completely inaccessible to some people. Part of the solution is scanning, getting a digital image of the page, but raw image pixels aren’t yet recognized as textual content from the computer’s point of view.
Optical Character Recognition (OCR) technology aims to turn pictures of text into computer text that can be indexed, searched, and edited. For some time, Google Drive has provided OCR capabilities. Recently, we expanded this state-of-the-art technology to support all of the world’s major languages - that’s over 200 languages in more than 25 writing systems. This technology is available to users in 2 easy steps:
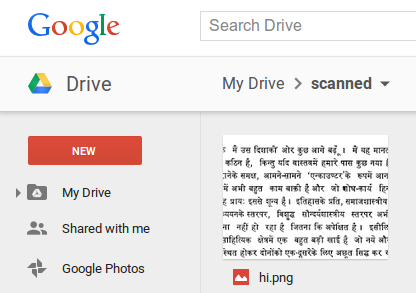
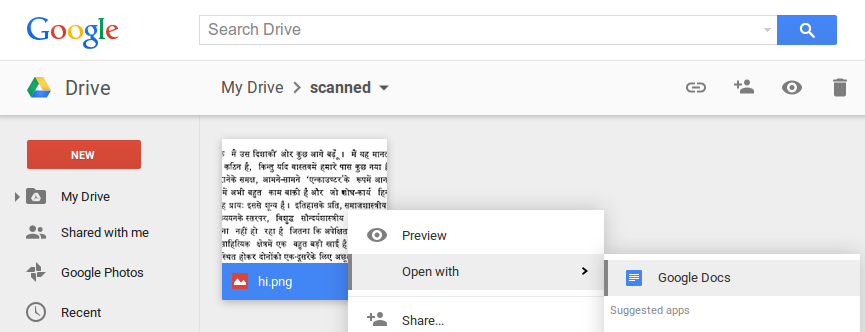
1. Upload a scanned document in its current form (say, as an image or PDF). The example below shows a scanned document in Hindi uploaded to a user’s Drive account as a PNG.



To make this possible, engineering teams across Google pursued an approach to OCR focused on broad language coverage, with a goal of designing an architecture that could potentially work with all existing languages and writing systems. We do this in part by using Hidden Markov Models (HMMs) to make sense of the input as a whole sequence, rather than first trying to break it apart into pieces. This is similar to how modern speech recognition systems recognize audio input.
OCR and speech recognition share some challenges - like dealing with background “noise,” different languages, and low-quality inputs. But some challenges are specific to OCR: the variety of typefaces, the different types of scanners and cameras, and the need to work on older material that may contain archaic orthographic and linguistic elements. In addition to utilizing HMMs, we leveraged many of the same technologies used in the Google Handwriting Input app to allow automatic learning of features and to give preference to more likely output, as well as minimum-error-rate training to allow effective combination of multiple sources of information, and modern methods in machine learning to minimize manual design and maximize use of data. We also take advantage of advances in internationalization and typesetting, by using synthetic data in our training.
Currently, the OCR works best on cleanly scanned, high-resolution documents in the most commonly used typefaces. We are working to improve performance on poor quality scans and challenging text layouts. Give it a try and let us know how it works for you.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯