On-Device Captioning with Live Caption
October 29, 2019
Posted by Michelle Tadmor-Ramanovich and Nadav Bar, Senior Software Engineers, Google Research, Tel-Aviv
Quick links
Captions for audio content are essential for the deaf and hard of hearing, but they benefit everyone. Watching video without audio is common — whether on the train, in meetings, in bed or when the kids are asleep — and studies have shown that subtitles can increase the duration of time that users spend watching a video by almost 40%. Yet caption support is fragmented across apps and even within them, resulting in a significant amount of audio content that remains inaccessible, including live blogs, podcasts, personal videos, audio messages, social media and others.

Recently we introduced Live Caption, a new Android feature that automatically captions media playing on your phone. The captioning happens in real time, completely on-device, without using network resources, thus preserving privacy and lowering latency. The feature is currently available on Pixel 4 and Pixel 4 XL, will roll out to Pixel 3 models later this year, and will be more widely available on other Android devices soon.
 |
| When media is playing, Live Caption can be launched with a single tap from the volume control to display a caption box on the screen. |
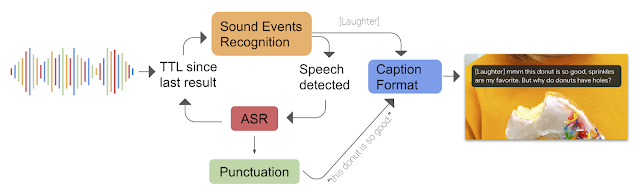
Live Caption works through a combination of three on-device deep learning models: a recurrent neural network (RNN) sequence transduction model for speech recognition (RNN-T), a text-based recurrent neural network model for unspoken punctuation, and a convolutional neural network (CNN) model for sound events classification. Live Caption integrates the signal from the three models to create a single caption track, where sound event tags, like [APPLAUSE] and [MUSIC], appear without interrupting the flow of speech recognition results. Punctuation symbols are predicted while text is updated in parallel.
 |
| Incoming sound is processed through a Sound Recognition and ASR feedback loop. The produced text or sound label is formatted and added to the caption. |
In order for Live Caption to be most useful, it should be able to run continuously for long periods of time. To do this, Live Caption’s ASR model is optimized for edge-devices using several techniques, such as neural connection pruning, which reduced the power consumption to 50% compared to the full sized speech model. Yet while the model is significantly more energy efficient, it still performs well for a variety of use cases, including captioning videos, recognizing short queries and narrowband telephony speech, while also being robust to background noise.
The text-based punctuation model was optimized for running continuously on-device using a smaller architecture than the cloud equivalent, and then quantized and serialized using the TensorFlow Lite runtime. As the caption is formed, speech recognition results are rapidly updated a few times per second. In order to save on computational resources and provide a smooth user experience, the punctuation prediction is performed on the tail of the text from the most recently recognized sentence, and if the next updated ASR results do not change that text, the previously punctuated results are retained and reused.
Looking forward
Live Caption is now available in English on Pixel 4 and will soon be available on Pixel 3 and other Android devices. We look forward to bringing this feature to more users by expanding its support to other languages and by further improving the formatting in order to improve the perceived accuracy and coherency of the captions, particularly for multi-speaker content.
Acknowledgements
The core team includes Robert Berry, Anthony Tripaldi, Danielle Cohen, Anna Belozovsky, Yoni Tsafir, Elliott Burford, Justin Lee, Kelsie Van Deman, Nicole Bleuel, Brian Kemler, and Benny Schlesinger. We would like to thank the Google Speech team, especially Qiao Liang, Arun Narayanan, and Rohit Prabhavalkar for their insightful work on the ASR model as well as Chung-Cheng Chiu from Google Brain Team; Dan Ellis and Justin Paul for their help with integrating the Sound Recognition model; Tal Remez for his help in developing the punctuation model; Kevin Rocard and Eric Laurent for their help with the Android audio capture API; and Eugenio Marchiori, Shivanker Goel, Ye Wen, Jay Yoo, Asela Gunawardana, and Tom Hume for their help with the Android infrastructure work.
Quick links
Other posts of interest
-

February 10, 2026
Beyond one-on-one: Authoring, simulating, and testing dynamic human-AI group conversations- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-
January 15, 2026
Unlocking health insights: Estimating advanced walking metrics with smartwatches- Health & Bioscience ·
- Human-Computer Interaction and Visualization
-

January 13, 2026
Hard-braking events as indicators of road segment crash risk- Algorithms & Theory ·
- Product
×
❮
❯