Lyra: A New Very Low-Bitrate Codec for Speech Compression
February 25, 2021
Posted by Alejandro Luebs, Software Engineer and Jamieson Brettle, Product Manager, Chrome
Quick links
Connecting to others online via voice and video calls is something that is increasingly a part of everyday life. The real-time communication frameworks, like WebRTC, that make this possible depend on efficient compression techniques, codecs, to encode (or decode) signals for transmission or storage. A vital part of media applications for decades, codecs allow bandwidth-hungry applications to efficiently transmit data, and have led to an expectation of high-quality communication anywhere at any time.
As such, a continuing challenge in developing codecs, both for video and audio, is to provide increasing quality, using less data, and to minimize latency for real-time communication. Even though video might seem much more bandwidth hungry than audio, modern video codecs can reach lower bitrates than some high-quality speech codecs used today. Combining low-bitrate video and speech codecs can deliver a high-quality video call experience even in low-bandwidth networks. Yet historically, the lower the bitrate for an audio codec, the less intelligible and more robotic the voice signal becomes. Furthermore, while some people have access to a consistent high-quality, high-speed network, this level of connectivity isn’t universal, and even those in well connected areas at times experience poor quality, low bandwidth, and congested network connections.
To solve this problem, we have created Lyra, a high-quality, very low-bitrate speech codec that makes voice communication available even on the slowest networks. To do this, we’ve applied traditional codec techniques while leveraging advances in machine learning (ML) with models trained on thousands of hours of data to create a novel method for compressing and transmitting voice signals.
Lyra Overview
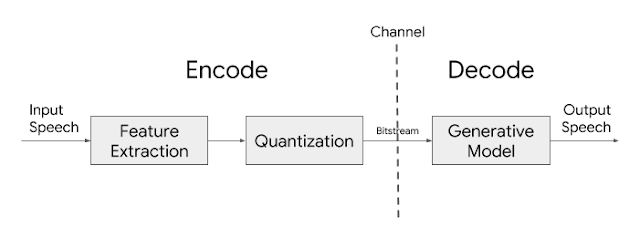
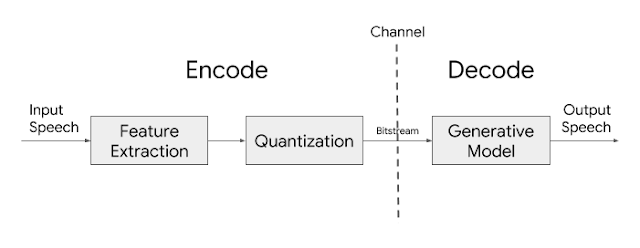
The basic architecture of the Lyra codec is quite simple. Features, or distinctive speech attributes, are extracted from speech every 40ms and are then compressed for transmission. The features themselves are log mel spectrograms, a list of numbers representing the speech energy in different frequency bands, which have traditionally been used for their perceptual relevance because they are modeled after human auditory response. On the other end, a generative model uses those features to recreate the speech signal. In this sense, Lyra is very similar to other traditional parametric codecs, such as MELP.

However traditional parametric codecs, which simply extract from speech critical parameters that can then be used to recreate the signal at the receiving end, achieve low bitrates, but often sound robotic and unnatural. These shortcomings have led to the development of a new generation of high-quality audio generative models that have revolutionized the field by being able to not only differentiate between signals, but also generate completely new ones. DeepMind’s WaveNet was the first of these generative models that paved the way for many to come. Additionally, WaveNetEQ, the generative model-based packet-loss-concealment system currently used in Duo, has demonstrated how this technology can be used in real-world scenarios.
A New Approach to Compression with Lyra
Using these models as a baseline, we’ve developed a new model capable of reconstructing speech using minimal amounts of data. Lyra harnesses the power of these new natural-sounding generative models to maintain the low bitrate of parametric codecs while achieving high quality, on par with state-of-the-art waveform codecs used in most streaming and communication platforms today. The drawback of waveform codecs is that they achieve this high quality by compressing and sending over the signal sample-by-sample, which requires a higher bitrate and, in most cases, isn’t necessary to achieve natural sounding speech.
One concern with generative models is their computational complexity. Lyra avoids this issue by using a cheaper recurrent generative model, a WaveRNN variation, that works at a lower rate, but generates in parallel multiple signals in different frequency ranges that it later combines into a single output signal at the desired sample rate. This trick enables Lyra to not only run on cloud servers, but also on-device on mid-range phones in real time (with a processing latency of 90ms, which is in line with other traditional speech codecs). This generative model is then trained on thousands of hours of speech data and optimized, similarly to WaveNet, to accurately recreate the input audio.
Comparison with Existing Codecs
Since the inception of Lyra, our mission has been to provide the best quality audio using a fraction of the bitrate data of alternatives. Currently, the royalty-free open-source codec Opus, is the most widely used codec for WebRTC-based VOIP applications and, with audio at 32kbps, typically obtains transparent speech quality, i.e., indistinguishable from the original. However, while Opus can be used in more bandwidth constrained environments down to 6kbps, it starts to demonstrate degraded audio quality. Other codecs are capable of operating at comparable bitrates to Lyra (Speex, MELP, AMR), but each suffer from increased artifacts and result in a robotic sounding voice.
Lyra is currently designed to operate at 3kbps and listening tests show that Lyra outperforms any other codec at that bitrate and is compared favorably to Opus at 8kbps, thus achieving more than a 60% reduction in bandwidth. Lyra can be used wherever the bandwidth conditions are insufficient for higher-bitrates and existing low-bitrate codecs do not provide adequate quality.
| Clean Speech |
| Original |
| Opus@6kbps |
| Lyra@3kbps |
| Speex@3kbps |
| Noisy Environment |
| Original |
| Opus@6kbps |
| Lyra@3kbps |
| Speex@3kbps |
| Reference | Opus@6kbps | Lyra@3kbps |

Ensuring Fairness
As with any ML based system, the model must be trained to make sure that it works for everyone. We’ve trained Lyra with thousands of hours of audio with speakers in over 70 languages using open-source audio libraries and then verifying the audio quality with expert and crowdsourced listeners. One of the design goals of Lyra is to ensure universally accessible high-quality audio experiences. Lyra trains on a wide dataset, including speakers in a myriad of languages, to make sure the codec is robust to any situation it might encounter.
Societal Impact and Where We Go From Here
The implications of technologies like Lyra are far reaching, both in the short and long term. With Lyra, billions of users in emerging markets can have access to an efficient low-bitrate codec that allows them to have higher quality audio than ever before. Additionally, Lyra can be used in cloud environments enabling users with various network and device capabilities to chat seamlessly with each other. Pairing Lyra with new video compression technologies, like AV1, will allow video chats to take place, even for users connecting to the internet via a 56kbps dial-in modem.
Duo already uses ML to reduce audio interruptions, and is currently rolling out Lyra to improve audio call quality and reliability on very low bandwidth connections. We will continue to optimize Lyra’s performance and quality to ensure maximum availability of the technology, with investigations into acceleration via GPUs and TPUs. We are also beginning to research how these technologies can lead to a low-bitrate general-purpose audio codec (i.e., music and other non-speech use cases).
Acknowledgements
Thanks to everyone who made Lyra possible including Jan Skoglund, Felicia Lim, Michael Chinen, Bastiaan Kleijn, Tom Denton, Andrew Storus, Yero Yeh (Chrome Media), Henrik Lundin, Niklas Blum, Karl Wiberg (Google Duo), Chenjie Gu, Zach Gleicher, Norman Casagrande, Erich Elsen (DeepMind).
-
Labels:
- Sound & Accoustics
Quick links
Other posts of interest
-

February 9, 2026
How AI trained on birds is surfacing underwater mysteries- Climate & Sustainability ·
- Open Source Models & Datasets ·
- Sound & Accoustics
-

December 3, 2025
From Waveforms to Wisdom: The New Benchmark for Auditory Intelligence- Machine Intelligence ·
- Sound & Accoustics ·
- Speech Processing
-

July 2, 2025
Making group conversations more accessible with sound localization- Human-Computer Interaction and Visualization ·
- Sound & Accoustics ·
- Speech Processing