Long-Range Robotic Navigation via Automated Reinforcement Learning
February 28, 2019
Aleksandra Faust, Senior Research Scientist and Anthony Francis, Senior Software Engineer, Robotics at Google
Quick links
In the United States alone, there are 3 million people with a mobility impairment that prevents them from ever leaving their homes. Service robots that can autonomously navigate long distances can improve the independence of people with limited mobility, for example, by bringing them groceries, medicine, and packages. Research has demonstrated that deep reinforcement learning (RL) is good at mapping raw sensory input to actions, e.g. learning to grasp objects and for robot locomotion, but RL agents usually lack the understanding of large physical spaces needed to safely navigate long distances without human help and to easily adapt to new spaces.
In three recent papers, “Learning Navigation Behaviors End-to-End with AutoRL,” “PRM-RL: Long-Range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning”, and “Long-Range Indoor Navigation with PRM-RL”, we investigate easy-to-adapt robotic autonomy by combining deep RL with long-range planning. We train local planner agents to perform basic navigation behaviors, traversing short distances safely without collisions with moving obstacles. The local planners take noisy sensor observations, such as a 1D lidar that provides distances to obstacles, and output linear and angular velocities for robot control. We train the local planner in simulation with AutoRL, a method that automates the search for RL reward and neural network architecture. Despite their limited range of 10 - 15 meters, the local planners transfer well to both real robots and to new, previously unseen environments. This enables us to use them as building blocks for navigation in large spaces. We then build a roadmap, a graph where nodes are locations and edges connect the nodes only if local planners, which mimic real robots well with their noisy sensors and control, can traverse between them reliably.
Automating Reinforcement Learning (AutoRL)
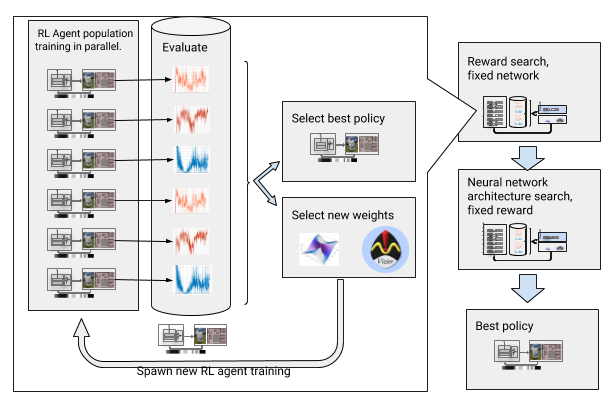
In our first paper, we train the local planners in small, static environments. However, training with standard deep RL algorithms, such as Deep Deterministic Policy Gradient (DDPG), poses several challenges. For example, the true objective of the local planners is to reach the goal, which represents a sparse reward. In practice, this requires researchers to spend significant time iterating and hand-tuning the rewards. Researchers must also make decisions about the neural network architecture, without clear accepted best practices. And finally, algorithms like DDPG are unstable learners and often exhibit catastrophic forgetfulness.
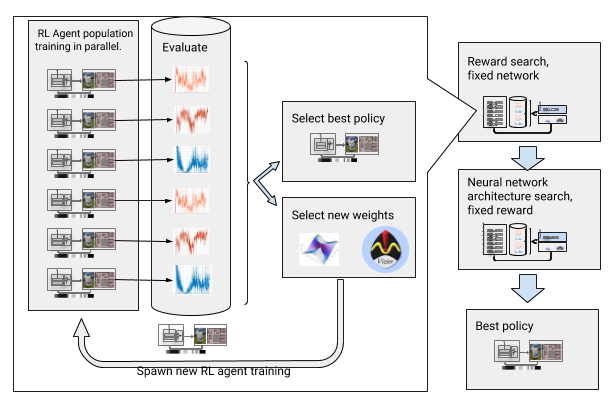
To overcome those challenges, we automate the deep Reinforcement Learning (RL) training. AutoRL is an evolutionary automation layer around deep RL that searches for a reward and neural network architecture using large-scale hyperparameter optimization. It works in two phases, reward search and neural network architecture search. During the reward search, AutoRL trains a population of DDPG agents concurrently over several generations, each with a slightly different reward function optimizing for the local planner’s true objective: reaching the destination. At the end of the reward search phase, we select the reward that leads the agents to its destination most often. In the neural network architecture search phase, we repeat the process, this time using the selected reward and tuning the network layers, optimizing for the cumulative reward.
 |
| Automating reinforcement learning with reward and neural network architecture search. |
However, this iterative process means AutoRL is not sample efficient. Training one agent takes 5 million samples; AutoRL training over 10 generations of 100 agents requires 5 billion samples - equivalent to 32 years of training! The benefit is that after AutoRL the manual training process is automated, and DDPG does not experience catastrophic forgetfulness. Most importantly, the resulting policies are higher quality — AutoRL policies are robust to sensor, actuator and localization noise, and generalize well to new environments. Our best policy is 26% more successful than other navigation methods across our test environments.
 |
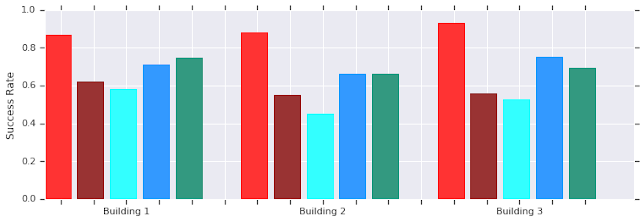
| AutoRL (red) success over short distances (up to 10 meters) in several unseen buildings. Compared to hand-tuned DDPG (dark-red), artificial potential fields (light blue), dynamic window approach (blue), and behavior cloning (green). |
| AutoRL local planner policy transfer to robots in real, unstructured environments |
While these policies only perform local navigation, they are robust to moving obstacles and transfer well to real robots, even in unstructured environments. Though they were trained in simulation with only static obstacles, they can also handle moving objects effectively. The next step is to combine the AutoRL policies with sampling-based planning to extend their reach and enable long-range navigation.
Achieving Long Range Navigation with PRM-RL
Sampling-based planners tackle long-range navigation by approximating robot motions. For example, probabilistic roadmaps (PRMs) sample robot poses and connect them with feasible transitions, creating roadmaps that capture valid movements of a robot across large spaces. In our second paper, which won Best Paper in Service Robotics at ICRA 2018, we combine PRMs with hand-tuned RL-based local planners (without AutoRL) to train robots once locally and then adapt them to different environments.
First, for each robot we train a local planner policy in a generic simulated training environment. Next, we build a PRM with respect to that policy, called a PRM-RL, over a floor plan for the deployment environment. The same floor plan can be used for any robot we wish to deploy in the building in a one time per robot+environment setup.
To build a PRM-RL we connect sampled nodes only if the RL-based local planner, which represents robot noise well, can reliably and consistently navigate between them. This is done via Monte Carlo simulation. The resulting roadmap is tuned to both the abilities and geometry of the particular robot. Roadmaps for robots with the same geometry but different sensors and actuators will have different connectivity. Since the agent can navigate around corners, nodes without clear line of sight can be included. Whereas nodes near walls and obstacles are less likely to be connected into the roadmap because of sensor noise. At execution time, the RL agent navigates from roadmap waypoint to waypoint.
 |
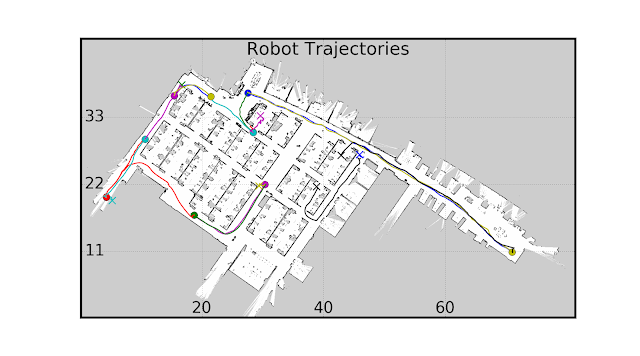
| Roadmap being built with 3 Monte Carlo simulations per randomly selected node pair. |
 |
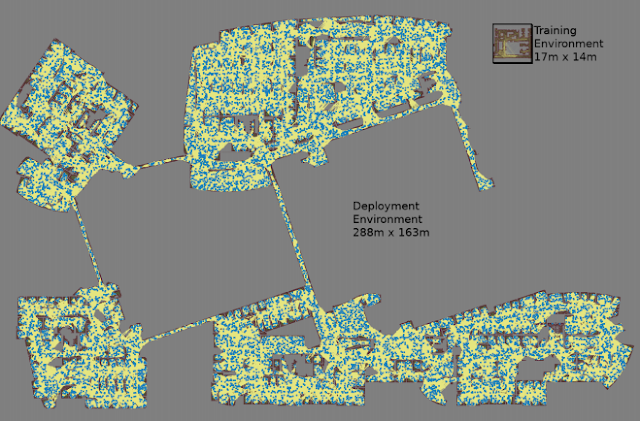
| The largest map was 288 meters by 163 meters and contains almost 700,000 edges, collected over 4 days using 300 workers in a cluster requiring 1.1 billion collision checks. |
The third paper makes several improvements over the original PRM-RL. First, we replace the hand-tuned DDPG with AutoRL-trained local planners, which results in improved long-range navigation. Second, it adds Simultaneous Localization and Mapping (SLAM) maps, which robots use at execution time, as a source for building the roadmaps. Because SLAM maps are noisy, this change closes the “sim2real gap”, a phonomena in robotics where simulation-trained agents significantly underperform when transferred to real-robots. Our simulated success rates are the same as in on-robot experiments. Last, we added distributed roadmap building, resulting in very large scale roadmaps containing up to 700,000 nodes.
We evaluated the method using our AutoRL agent, building roadmaps using the floor maps of offices up to 200x larger than the training environments, accepting edges with at least 90% success over 20 trials. We compared PRM-RL to a variety of different methods over distances up to 100m, well beyond the local planner range. PRM-RL had 2 to 3 times the rate of success over baseline because the nodes were connected appropriately for the robot’s capabilities.
 |
| Navigation over 100 meters success rates in several buildings. First paper -AutoRL local planner only (blue); original PRMs (red); path-guided artificial potential fields (yellow); second paper (green); third paper - PRMs with AutoRL (orange). |
We tested PRM-RL on multiple real robots and real building sites. One set of tests are shown below; the robot is very robust except near cluttered areas and off the edge of the SLAM map.
 |
| On-robot experiments |
Conclusion
Autonomous robot navigation can significantly improve independence of people with limited mobility. We can achieve this by development of easy-to-adapt robotic autonomy, including methods that can be deployed in new environments using information that it is already available. This is done by automating the learning of basic, short-range navigation behaviors with AutoRL and using these learned policies in conjunction with SLAM maps to build roadmaps. These roadmaps consist of nodes connected by edges that robots can traverse consistently. The result is a policy that once trained can be used across different environments and can produce a roadmap custom-tailored to the particular robot.
Acknowledgements
The research was done by, in alphabetical order, Hao-Tien Lewis Chiang, James Davidson, Aleksandra Faust, Marek Fiser, Anthony Francis, Jasmine Hsu, J. Chase Kew, Tsang-Wei Edward Lee, Ken Oslund, Oscar Ramirez from Robotics at Google and Lydia Tapia from University of New Mexico. We thank Alexander Toshev, Brian Ichter, Chris Harris, and Vincent Vanhoucke for helpful discussions.
Quick links
Other posts of interest
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
-

June 30, 2026
Introducing TabFM: A zero-shot foundation model for tabular data- Data Management ·
- Machine Intelligence ·
- Product