Load balancing with random job arrivals
March 20, 2025
Ravi Kumar and Manish Purohit, Research Scientists, Google Research
We examine classical scheduling problems, common in computational cluster management, and present improved upper and lower bounds for load balancing with random arrival orders.
Quick links
Cluster management systems, such as Google’s Borg, run hundreds of thousands of jobs across tens of thousands of machines with the goal of achieving high utilization via effective load balancing, efficient task placement, and machine sharing. Load balancing is the process of distributing network traffic or computational workloads across multiple servers or computing resources, and it is one of the most critical components of a modern cluster management system. Effective load balancing is critical to improving the performance, robustness and scalability of the system.
In the classical formulation of the online load balancing problem, computational jobs arrive one-by-one and, as soon as a job arrives, it must be assigned to one of several machines. Each job may impose different processing loads on different machines, and the load incurred by a machine depends on the jobs that are assigned to it. The goal of a load balancing algorithm is to minimize the maximum load on any machine. Online algorithms are those designed for situations where the input to the system is revealed to the algorithm piece by piece.
Online problems are common in decision-making scenarios that have uncertainty, including the ski-rental problem, secretary problem, caching and scheduling problems, and many others. Scheduling and load balancing questions are prevalent in resource management for large-scale systems leading to research into many real-world scheduling problems, including maintaining consistent allocation of clients to servers and, more recently, platforms for AI workloads. Traditionally, online algorithms for scheduling and load balancing are studied through the lens of competitive analysis. The competitive ratio of an online algorithm quantifies the worst-case performance of the algorithm relative to an optimal offline algorithm that knows future jobs, specifically by determining the worst-case ratio of the cost incurred by the two algorithms over all possible sequences of jobs.
In “Online Load and Graph Balancing for Random Order Inputs”, presented at SPAA 2024, we study the competitive ratio of online load balancing problems when jobs arrive in uniformly random order (i.e., when each possible permutation of job arrival sequences is equally likely). We show new limitations on how well deterministic online algorithms can perform in this setting.
A tree balancing game
Consider the following game between an adversary and an algorithm: the adversary selects a tree (a simple graph with no cycles, i.e., no path that can connect back to itself) whose nodes are labeled and presents to the algorithm the edges of the tree, one at a time, in an order it chooses. When the algorithm receives an undirected edge (u — v), it must choose the orientation, either u → v or u ← v. The goal of the algorithm is to minimize the maximum number of edges that are oriented towards any particular node, i.e., to minimize the maximum indegree of the tree. This simple game is a special instance of online load balancing. Indeed, each node of the tree corresponds to a machine and each edge corresponds to a job.
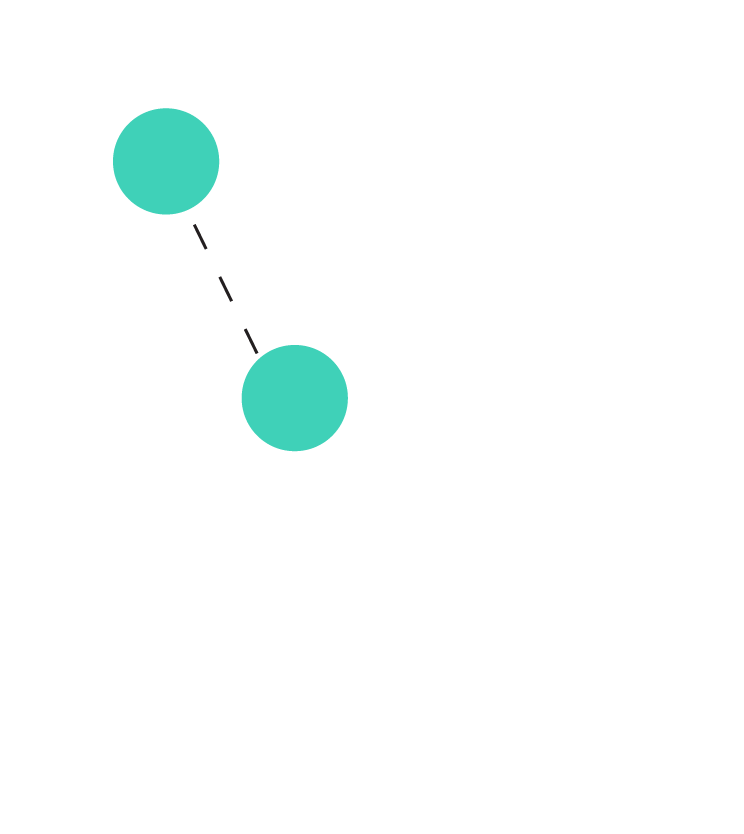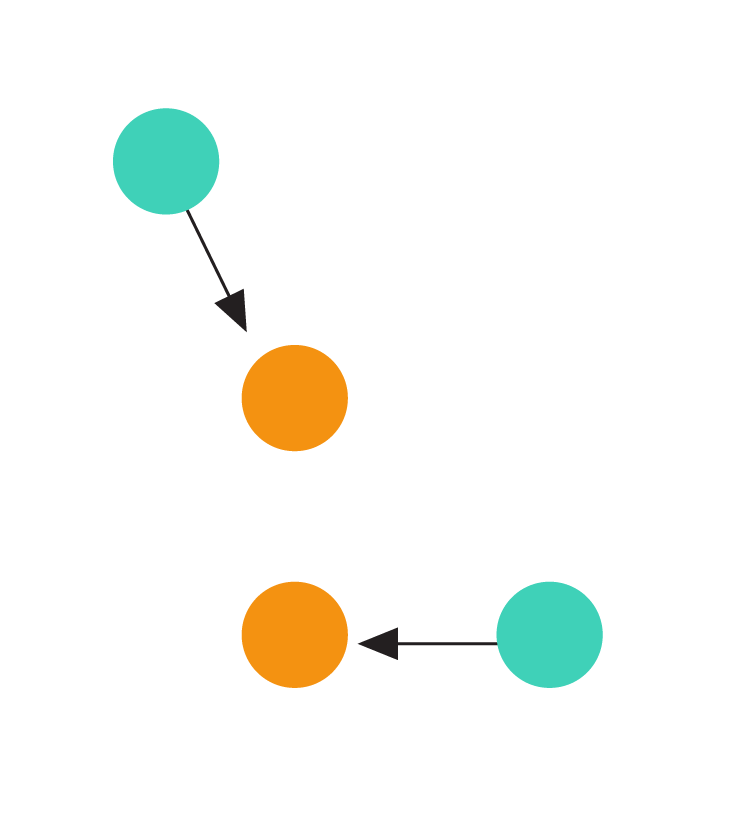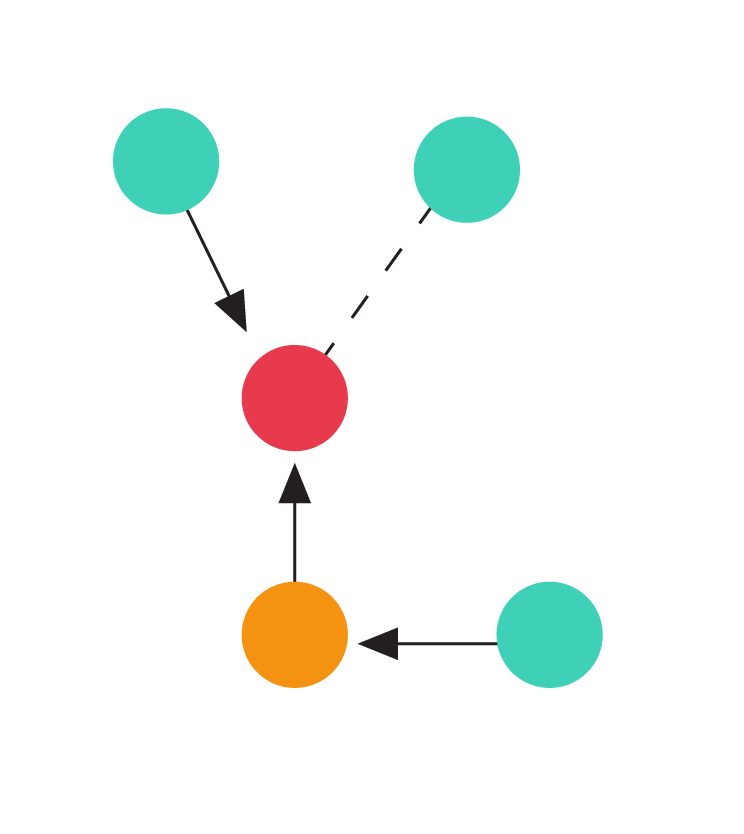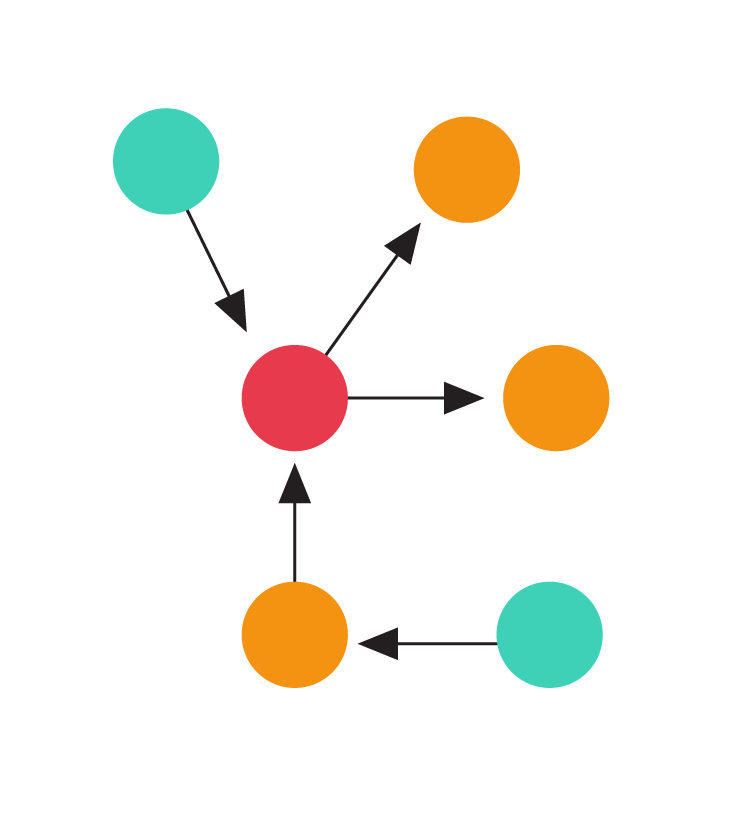
Illustration of the tree balancing game. Each dashed line denotes an undirected edge presented by the adversary. The animation shows the outcome of a greedy algorithm that orients the incoming edge towards the node with the smaller indegree.
Since the 1990s, it has been known that no deterministic online algorithm can guarantee that the indegree of the tree will always be less than log n, where n is the number of nodes in the tree. Since one can always orient the edges of a tree so that each node has indegree at most 1, this shows that any deterministic algorithm must have a competitive ratio of at least log n.
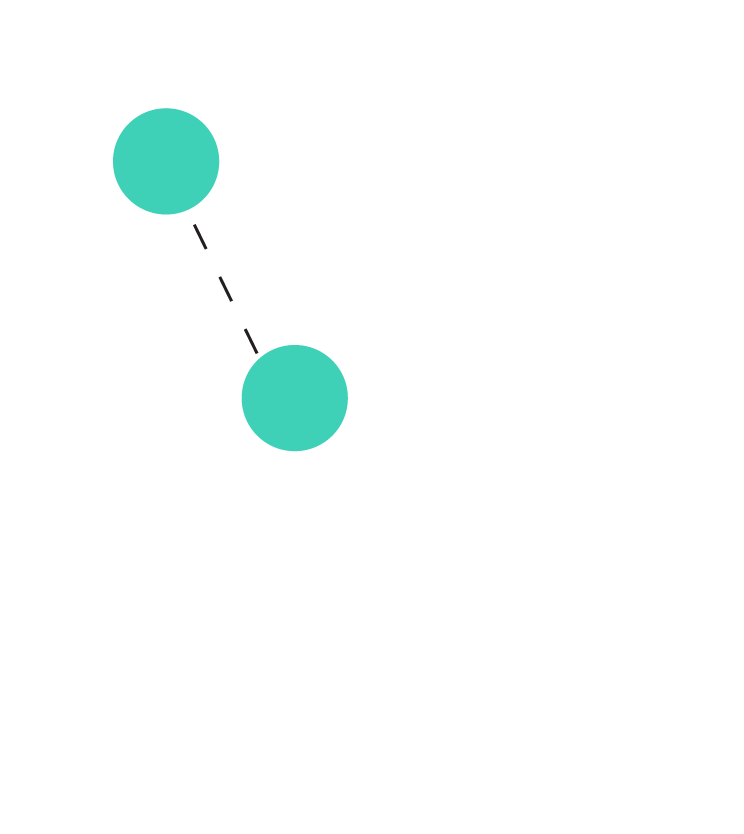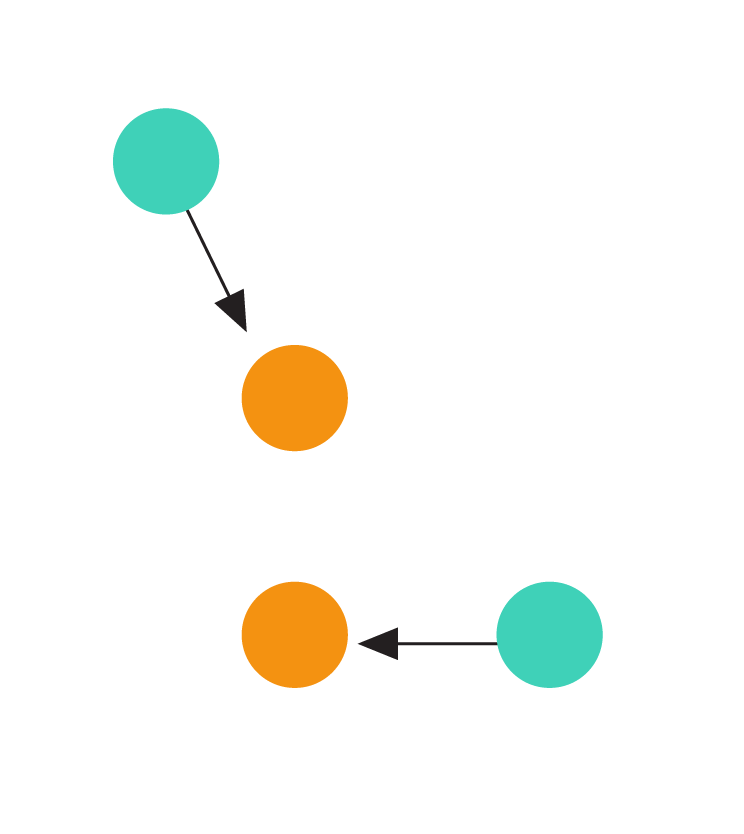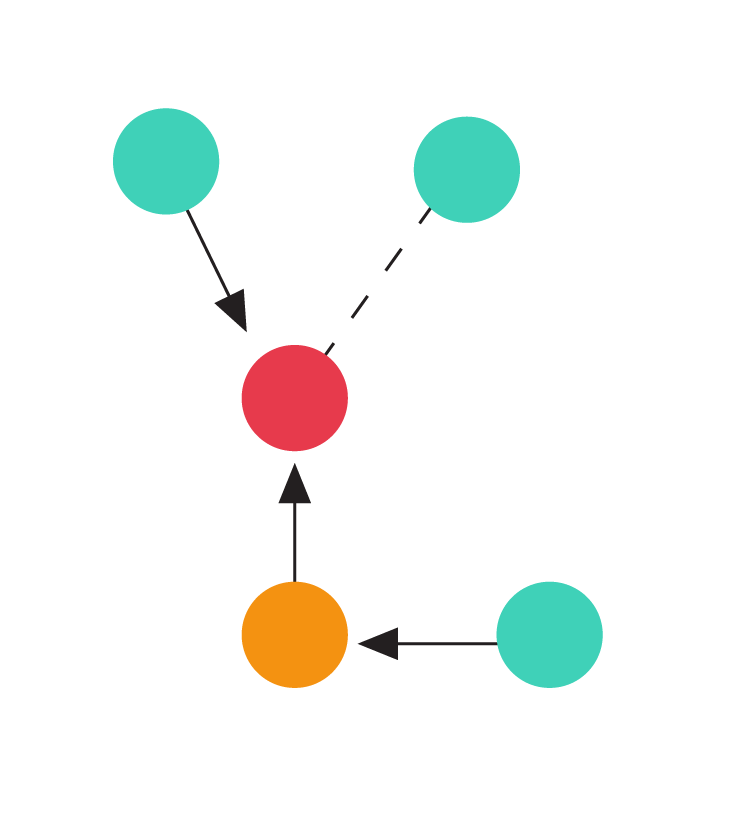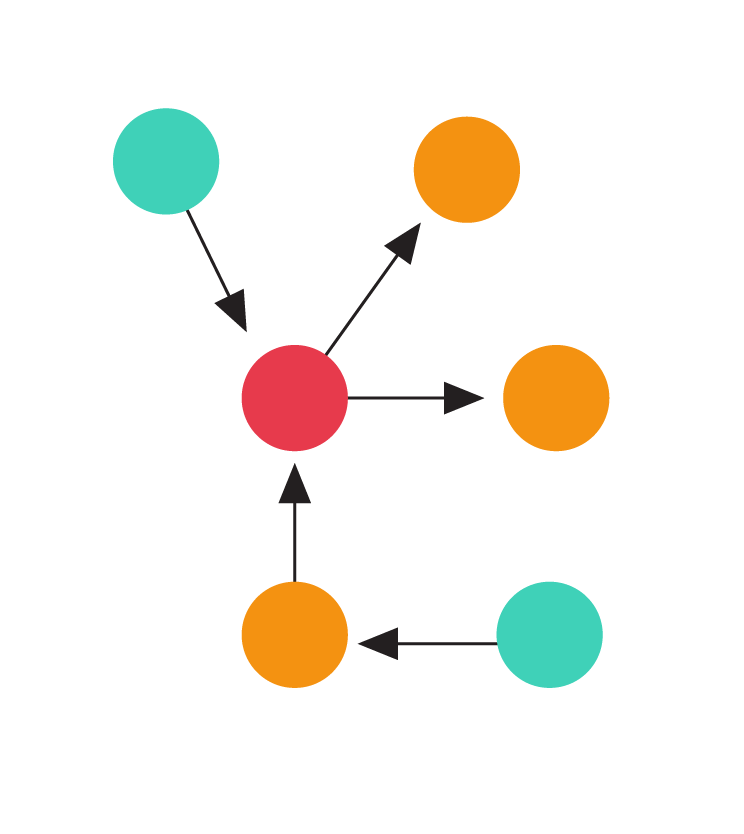
The following animation illustrates such a hard instance. At the first step, a batch of edges arrive that all look exactly identical. Since there is no way of distinguishing the endpoints of any edge, the algorithm can do no better than orienting the edge arbitrarily (in the animation, each edge gets oriented towards the yellow node). The second batch of edges is then incident only on the yellow nodes forcing the algorithm to increase the indegree of the tree. This process then continues until no more batches can be constructed.
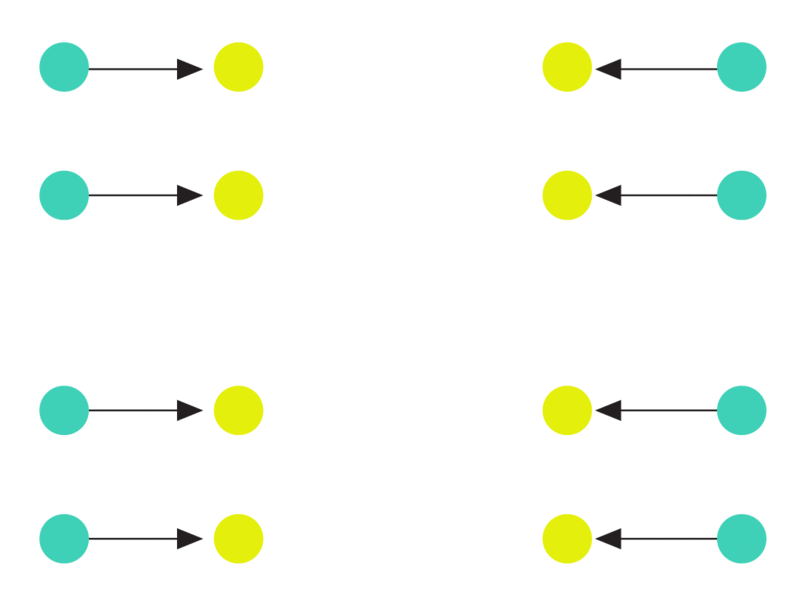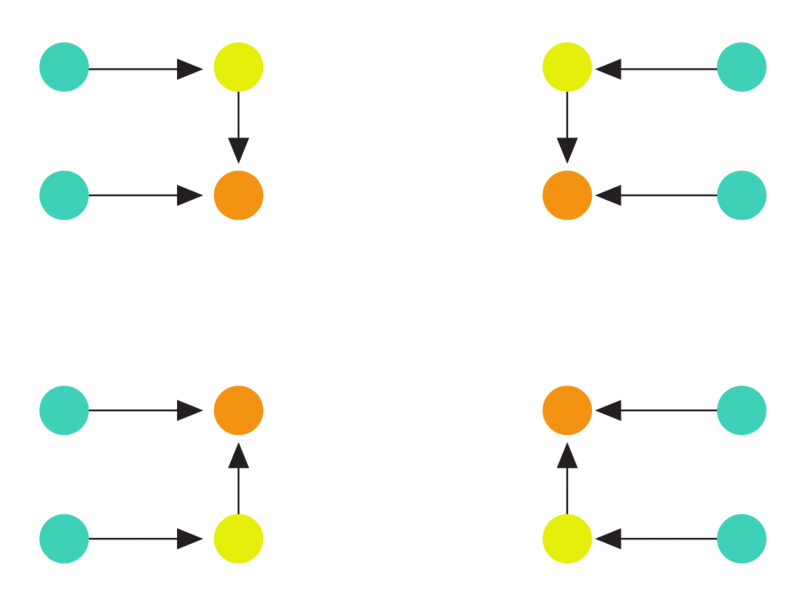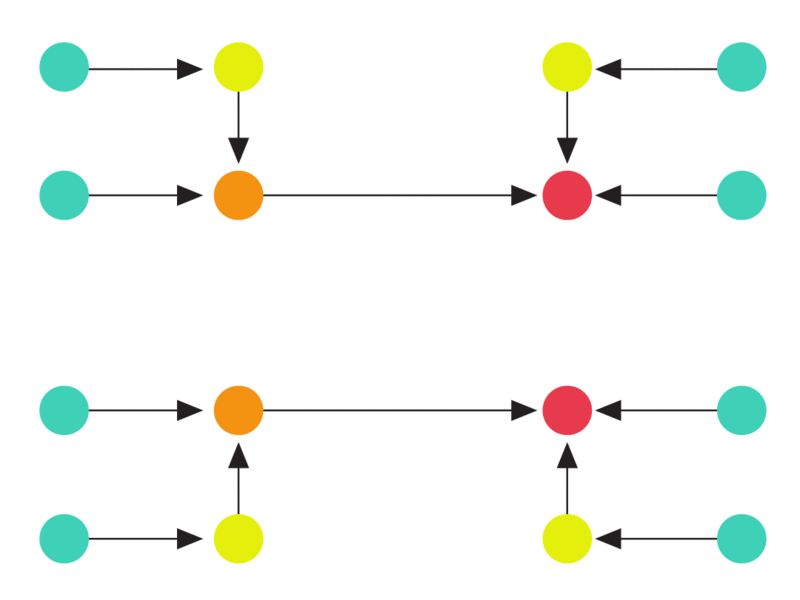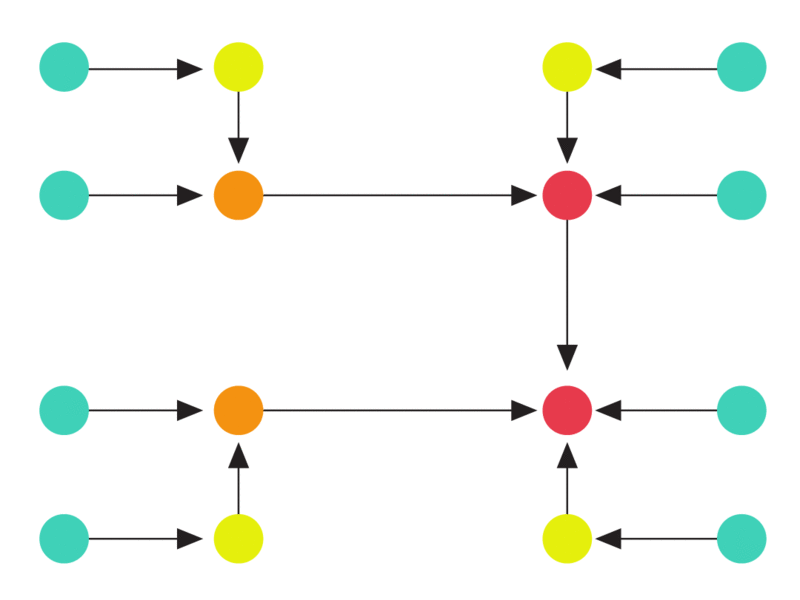
Any deterministic algorithm must incur a maximum load of at least log n. Both end points of each arriving edge look identical to any algorithm. In each batch of edges, the maximum indegree of the graph increases, eventually leading to a node with degree log n.
In the example above, the adversary crucially needs to choose the arrival order of edges to ensure that the algorithm makes the wrong decision for each edge. But what happens when the tree edges arrive in random order?
Random order arrivals
Previous work showed that the greedy algorithm, which orients each incoming edge towards the node with the smaller indegree, performs only slightly better in the random order model. However, the possibility that other, smarter algorithms could perform much better remained open and left a large gap in our understanding of the problem. In our work described below, we construct a new instance that improves the lower bound exponentially and show that no online algorithm can guarantee a competitive ratio significantly better than √(log n).
The lower bound instance we construct is recursive and, as in the adversarial arrival order case, the intuition is to force the algorithm to face an impossible choice: deciding between two endpoints that look identical. If we let D be a fixed integer, then the lower bound instance is a tree of height D that is constructed recursively as follows: We start with a single root node r with label l(r)=D. We then repeatedly perform the following process for each newly created node — for any node v with label l(v), we add 2D-d new nodes with label d (where 0 ≤ d < l(v)), and connect them to v. For example, in the figure below, with D=2, the root node with a label of 2 has two children labeled 1 and four children labeled 0. Each node with label 1 then has four additional children with label 0.
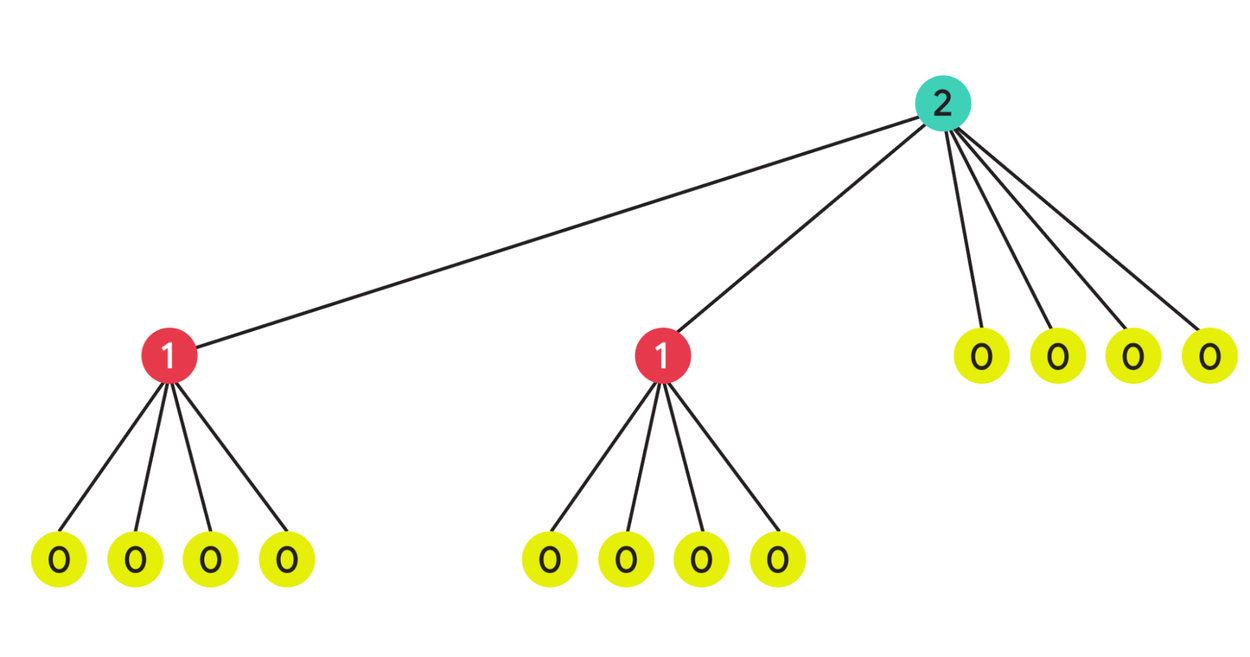
Lower bound instance where the height of the tree is given by D=2. The key observation is that when the first edge connecting a node of label 1 with node 2 arrives, no algorithm can distinguish between the end points. That is, an algorithm is equally likely to connect 1 → 2 as 1 ← 2.
We provide an intuition behind the lower bound. As a thought experiment, when the edges arrive at random, suppose that an edge (r, v) appears before any edge (r, w) with labels l(w) ≥ l(v). Now, conditioned on this event, the nodes r and v appear identical from the perspective of the algorithm. The algorithm, faced with an impossible choice, can do no better than a random guess, and hence orients the edge towards root r with probability ½. But since by construction, the root has far more edges leading to nodes with smaller labels, the event above happens with probability at least ½ as well. Hence, we expect the root node r to get a load of at least D/4. Analyzing the construction, we have D ~ √(log n), where n denotes the number of nodes in the tree.
Job scheduling on unrelated machines
Moving beyond the simple tree balancing problem, we consider online load balancing in a general setting called unrelated machines, which effectively models load balancing in cluster management systems. Assume that we have a set of jobs that are queued for processing on m machines. Jobs arrive in the system one-by-one and an algorithm needs to irrevocably assign each job to a machine when it arrives. The goal of the algorithm is to minimize the load of the most loaded machine.
Just as in the tree balancing game, we show that a natural variant of the greedy algorithm yields an improved competitive ratio of log m / log (log m) when the jobs arrive in random order.
Conclusion
We study job scheduling on unrelated machines and obtain an improved competitive ratio for random job arrivals. Although we significantly improve the previous lower bound for the tree balancing game with random edge arrivals, there is still a significant gap between the lower bound and the upper bound. Closing this gap is an interesting open question.
Acknowledgements
This represents joint work with Sungjin Im (UC Santa Cruz), Shi Li (Nanjing University) and Aditya Petety (UC Merced) and was a co-winner of the Outstanding Paper Award at the 2024 ACM Symposium on Parallelism in Algorithms and Architectures (SPAA).
Quick links
Other posts of interest
-
February 11, 2026
Scheduling in a changing world: Maximizing throughput with time-varying capacity- Algorithms & Theory
-

February 4, 2026
Sequential Attention: Making AI models leaner and faster without sacrificing accuracy- Algorithms & Theory
-

January 23, 2026
Introducing GIST: The next stage in smart sampling- Algorithms & Theory ·
- Data Mining & Modeling ·
- Machine Intelligence

