Learning to See Transparent Objects
February 12, 2020
Posted by Shreeyak Sajjan, Research Engineer, Synthesis AI and Andy Zeng, Research Scientist, Robotics at Google
Quick links
Optical 3D range sensors, like RGB-D cameras and LIDAR, have found widespread use in robotics to generate rich and accurate 3D maps of the environment, from self-driving cars to autonomous manipulators. However, despite the ubiquity of these complex robotic systems, transparent objects (like a glass container) can confound even a suite of expensive sensors that are commonly used. This is because optical 3D sensors are driven by algorithms that assume all surfaces are Lambertian, i.e., they reflect light evenly in all directions, resulting in a uniform surface brightness from all viewing angles. However, transparent objects violate this assumption, since their surfaces both refract and reflect light. Hence, most of the depth data from transparent objects are invalid or contain unpredictable noise.
 |
 |
| Transparent objects often fail to be detected by optical 3D sensors. Top, Right: For instance, glass bottles do not show up in the 3D depth imagery captured from an Intel® RealSense™ D415 RGB-D camera. Bottom: A 3D visualization via point clouds constructed from the depth image. |
To address this problem, we teamed up with researchers from Synthesis AI and Columbia University to develop ClearGrasp, a machine learning algorithm that is capable of estimating accurate 3D data of transparent objects from RGB-D images. This is made possible by a large-scale synthetic dataset that we are also releasing publicly today. ClearGrasp can work with inputs from any standard RGB-D camera, using deep learning to accurately reconstruct the depth of transparent objects and generalize to completely new objects unseen during training. This in contrast to previous methods, which required prior knowledge of the transparent objects (e.g., their 3D models), often combined with maps of background lighting and camera positions. In this work, we also demonstrate that ClearGrasp can benefit robotic manipulation by incorporating it into our pick and place robot’s control system, where we observe significant improvements in the grasping success rate of transparent plastic objects.
 |
 |
| ClearGrasp uses deep learning to recover accurate 3D depth data of transparent surfaces. |
Massive quantities of data are required to train any effective deep learning model (e.g., ImageNet for vision or Wikipedia for BERT), and ClearGrasp is no exception. Unfortunately, no datasets are available with 3D data of transparent objects. Existing 3D datasets like Matterport3D or ScanNet overlook transparent surfaces, because they require expensive and time-consuming labeling processes.
To overcome this issue, we created our own large-scale dataset of transparent objects that contains more than 50,000 photorealistic renders with corresponding surface normals (representing the surface curvature), segmentation masks, edges, and depth, useful for training a variety of 2D and 3D detection tasks. Each image contains up to five transparent objects, either on a flat ground plane or inside a tote, with various backgrounds and lighting.
 |
| Some example data of transparent objects from the ClearGrasp synthetic dataset. |
 |
| Left: The real-world image capturing setup, Middle: Custom user interface enables precisely replacing each transparent object with a spray-painted duplicate, Right: Example of captured data. |
While the distorted view of the background seen through transparent objects confounds typical depth estimation approaches, there are clues that hint at the objects’ shape. Transparent surfaces exhibit specular reflections, which are mirror-like reflections that show up as bright spots in a well-lit environment. Since these visual cues are prominent in RGB images and are influenced primarily by the shape of the objects, convolutional neural networks can use these reflections to infer accurate surface normals, which then can be used for depth estimation.
 |
| Specular reflections on transparent objects create distinct features that vary based on the object shape and provide strong visual cues for estimating surface normals. |
The ClearGrasp Algorithm
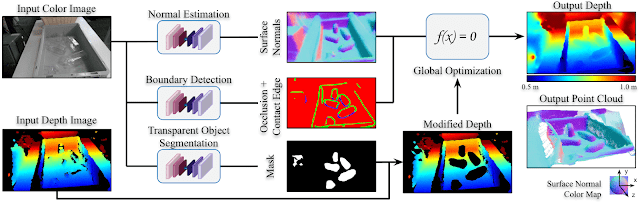
ClearGrasp uses 3 neural networks: a network to estimate surface normals, one for occlusion boundaries (depth discontinuities), and one that masks transparent objects. The mask is used to remove all pixels belonging to transparent objects, so that the correct depths can be filled in. We then use a global optimization module that starts extending the depth from known surfaces, using the predicted surface normals to guide the shape of the reconstruction, and the predicted occlusion boundaries to maintain the separation between distinct objects.
 |
| Overview of our method. The point cloud was generated using the output depth and is colored with its surface normals. |
 |
| Surface Normal estimation on real images when trained on a) Matterport3D and ScanNet only (MP+SN), b) our synthetic dataset only, and c) MP+SN as well as our synthetic dataset. Note how the model trained on MP+SN fails to detect the transparent objects. The model trained on only synthetic data picks up the real plastic bottles remarkably well, but fails for other objects and surfaces. When trained on both, our model gets the best of both worlds. |
Overall, our quantitative experiments show that ClearGrasp is able to reconstruct depth for transparent objects with much higher fidelity than alternative methods. Despite being trained on only synthetic transparent objects, we find our models are able to adapt well to the real-world domain — achieving very similar quantitative reconstruction performance on known objects across domains. Our models also generalize well to novel objects with complex shapes never seen before.
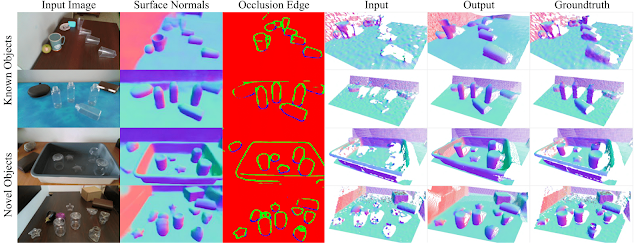
To check the qualitative performance of ClearGrasp, we construct 3D point clouds from the input and output depth images, as shown below (additional examples available on the project webpage). The resulting estimated 3D surfaces have clean and coherent reconstructed shapes — important for applications, such as 3D mapping and 3D object detection — without the jagged noise seen in monocular depth estimation methods. Our models are robust and perform well in challenging conditions, such as identifying transparent objects situated in a patterned background or differentiating between transparent objects partially occluding one another.
 |
| Qualitative results on real images. Top two rows: results on known objects. Bottom two rows: results on novel objects. The point clouds, colored with their surface normals, are generated from the corresponding depth images. |
 |
| Manipulation of novel transparent objects using ClearGrasp. Note the challenging conditions: textureless background, complex object shapes and the directional light causing confusing shadows and caustics (the patterns of light that occur when light rays are reflected or refracted from a surface). |
A limitation of our synthetic dataset is that it does not represent accurate caustics, due to the limitations of rendering with traditional path-tracing algorithms. As a result, our models confuse bright caustics coupled with shadows to be independent transparent objects. Despite these drawbacks, our work with ClearGrasp shows that synthetic data remains a viable approach to achieve competent results for learning-based depth reconstruction methods. A promising direction for future work is improving the domain transfer to real-world images by generating renders with physically-correct caustics and surface imperfections such as fingerprints.
With ClearGrasp, we demonstrate that high-quality renders can be used to successfully train models that perform well in the real world. We hope that our dataset will drive further research on data-driven perception algorithms for transparent objects. Download links and more example images can be found on our project website and our GitHub repository.
Acknowledgements
This research was done by Shreeyak Sajjan (Synthesis.ai), Matthew Moore (Synthesis.ai), Mike Pan (Synthesis.ai), Ganesh Nagaraja (Synthesis.ai), Johnny Lee, Andy Zeng, and Shuran Song (Columbia University). We would like to thank Ryan Hickman for managerial support, Ivan Krasin and Stefan Welker for fruitful technical discussions, Cameron (@camfoxmusic) for sharing 3D models of his potion bottles and Sharat Sajjan for helping with web design.
Quick links
Other posts of interest
-

March 11, 2026
Exploring the feasibility of conversational diagnostic AI in a real-world clinical study- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

March 4, 2026
Teaching LLMs to reason like Bayesians- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
×
❮
❯