
Learning to clarify: Multi-turn conversations with Action-Based Contrastive Self-Training
June 3, 2025
Maximillian Chen, Research Scientist, Google Research, and Ruoxi Sun, Research Scientist, Google DeepMind
We propose Action-Based Contrastive Self-Training, a data-efficient contrastive reinforcement learning tuning approach for improved multi-turn conversation modeling in mixed-initiative interaction.
Quick links
Large language models (LLMs) that have been optimized through human feedback have rapidly emerged as a leading paradigm for developing intelligent conversational agents. However, despite their strong performance across many benchmarks, LLM-based agents can still lack multi-turn conversational skills such as disambiguation — when they are faced with ambiguity, they often overhedge or implicitly guess users' true intents rather than asking clarifying questions. Yet high-quality conversation samples are often limited, constituting a bottleneck for LLMs' ability to learn optimal dialogue actions.
In “Learning to Clarify: Multi-turn Conversations with Action-Based Contrastive Self-Training” (presented at ICLR 2025), we propose Action-Based Contrastive Self-Training (ACT), a quasi-online preference optimization algorithm based on Direct Preference Optimization (DPO), which enables data-efficient dialogue policy learning in multi-turn conversation modeling. We demonstrate ACT's efficacy under data-efficient tuning scenarios using multiple real-world conversational tasks such as tabular-grounded question-answering and machine reading comprehension. We also introduce AmbigSQL, a novel task for disambiguating information-seeking requests for complex Structured Query Language (SQL) code generation to facilitate the development of data analysis agents. Additionally, we propose evaluating the ability of LLMs to function as conversational agents by examining whether they can implicitly recognize and reason about ambiguity in conversation. ACT demonstrates substantial conversation modeling improvements over standard tuning approaches like supervised fine-tuning and DPO.

A conversational agent capable of disambiguation could recognize when there is ambiguity and ask a clarifying question towards a more accurate final answer.
A novel perspective on conversational reasoning
Traditional neural approaches to building conversational agents typically consist of two core components: a module for dialogue understanding and planning (e.g., a binary prediction task to determine whether it is appropriate to ask a clarifying question), and a generation module which can execute such conversational actions (i.e., forming a clarifying question or answer attempt). However, in the modern interaction paradigm, LLMs are typically adapted for end-to-end usage in conversational applications without an intermediate planning stage. We propose directly optimizing conversational action planning as an implicit subtask of response generation. We refer to this paradigm as implicit action planning.
Training an LLM for downstream use consists of three phases: pre-training, supervised fine-tuning (SFT) for instruction-following, and tuning for alignment with human preferences. A common algorithm used for this final alignment phase is DPO, an off-policy contrastive learning algorithm designed to optimize the probabilities of winning and losing sequences such as conversation responses. However, such algorithms are typically still misaligned with the multi-turn nature of conversations. The proposed ACT algorithm seeks to address these issues.
Phase 1: Action-based contrastive data generation
The first phase of building ACT involves constructing a preference dataset, consisting of pairs of conversational responses where one resembles a winning action and one resembles a losing action.
We start from an initial conversational dataset. For each turn in the dataset, we use the conversation history as part of the input prompt (“Show me information…” in the figure below) in addition to any necessary task-specific context (such as a SQL database schema) and treat that turn as the winning response (“What specific …”, below). This winning response expresses an action (here, “Clarify”) and thus we synthesize a rejected response representing some converse action (here, “Answer”) using some conditional generation model. The result of this stage is a pairwise dataset where each of the rejected responses is synthetically generated.
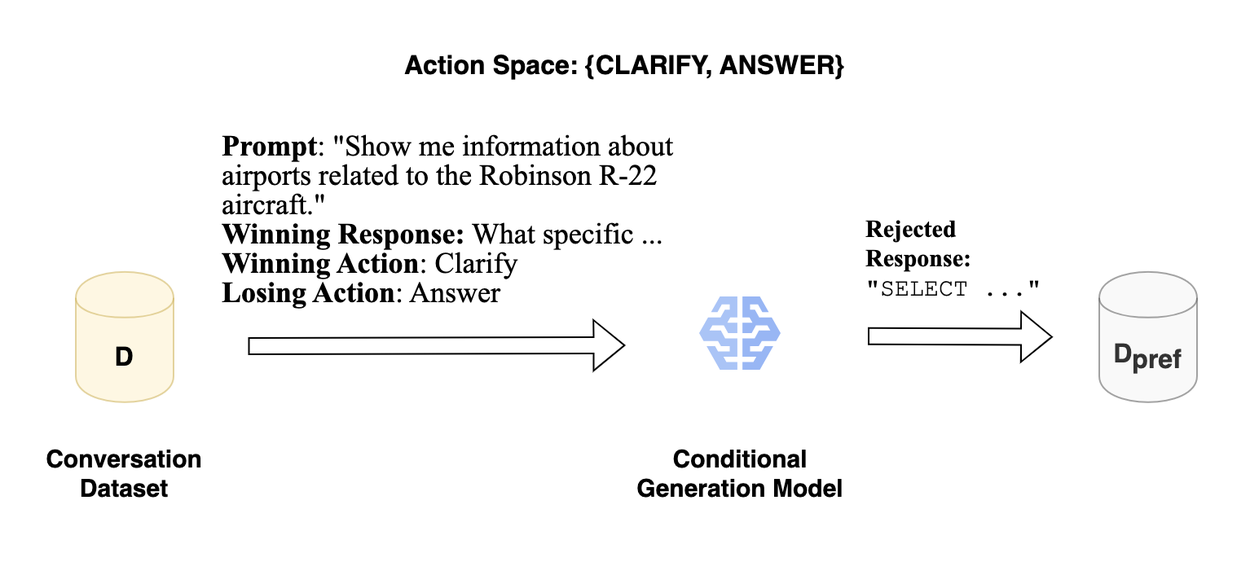
Overview of the data generation phase of ACT.
Phase 2: Contrastive self-training
The second phase involves tuning the policy model using the DPO objective. We can use the prompts from Phase 1, but rather than directly running DPO using the previously constructed contrastive pairs, we perform on-policy learning according to a few intuitions:
- DPO-like algorithms work by optimizing the log probabilities assigned to the winning and losing responses.
- By construction, on-policy response sampling yields high-probability token sequences.
- Conversational improvements require multi-turn optimization, which are difficult to express using only single-turn contrast pairings.
The figure below demonstrates how ACT works according to these intuitions. Rather than directly running an offline gradient update using the fixed contrastive pairs, we perform on-policy sampling. We first determine whether the response expresses the correct action (e.g., a clarifying question), and if so, then we simulate the result of the trajectory and evaluate the outcome against the information-seeking intent given in the original conversation. Depending on if the outcome is correct, we replace either the winning or losing response from the contrastive pair in Phase 1 with the simulated multi-turn trajectory.

Overview of the tuning phase of ACT. For each initial contrastive pairing from the Phase 1 preference dataset, we sample an on-policy response from the model being tuned. We evaluate the trajectory resulting from the sampled response then update the contrastive pairing by either replacing the existing winning or losing response. The policy is updated using the DPO objective.
Pushing state-of-the-art multi-turn modeling capabilities
We experimented with ACT using open-weight LLMs on a diverse set of multi-turn conversational datasets: PACIFIC (reasoning over tables mixed with text), Abg-CoQA (reasoning over dense passages), and AmbigSQL (text-to-SQL generation). We compared against various competitive baselines, including:
- Supervised fine-tuning with cross-entropy loss (SFT)
- Iterative Reasoning Preference Optimization (IRPO)
- Prompting Gemini 1.5 with in-context learning (ICL) examples
- Prompting Claude 3.5 with ICL examples
Conversational question answering with tabular grounding on PACIFIC
In the figure below, we see that across all three data-efficient settings considered for PACIFIC, ACT achieves the strongest performance across all metrics compared to both SFT and prompting Gemini, which has the advantage of additional test-time computation. In particular, ACT achieves up to a 19.1% relative improvement over SFT when measuring the tuned model's ability to implicitly recognize ambiguity (from 69.0 to 82.2 Macro F1) given only 50 conversations as tuning data. We also observe that ACT has greatly improved data efficiency compared to adapter-based SFT with Gemini Pro, with a relative improvement of as high as 35.7% in multi-turn task performance (from 45.6 to 61.9 in terms of trajectory-level DROP F1). Additionally, tuning with ACT in these limited data settings grants the model the ability to match or outperform frontier LLMs used with in-context learning despite having zero in-context examples during inference. Overall, we find that on-policy learning and multi-turn trajectory simulation are crucial for improved multi-turn goal completion.

ACT greatly outperforms standard tuning approaches in data-efficient settings for conversational modeling.
In our paper, we present extended results on the PACIFIC corpus, where we demonstrate that ACT outperforms IRPO. There, we additionally present our findings on Abg-CoQA and AmbigSQL.
Attributing the performance gains from ACT
We conducted several experiments to understand the benefits of each component of ACT, the results of which are below:

Ablation study of various components of ACT using PACIFIC.
Are action-based preferences necessary? One of the key factors of ACT is that the contrastive pairs highlight differences between conversational actions. In “ACT w/ Random Actions”, we additionally examine the importance of action selection by randomly sampling both the winning and losing action when constructing the preference pair, and observe this underperforms normal ACT.
Do we need on-policy sampling? In “ACT w/o on-policy sampling”, we examine the importance of on-policy sampling by evaluating normal off-policy DPO on the dataset as constructed in Phase 1. While we do observe some improvements over SFT (e.g., from 69.0 to 74.8 Macro F1), the overall improvements are much larger when using on-policy sampling as with full ACT. This may be due to the fact that the off-policy negative responses are not guaranteed to lie in the language manifold of the policy model, and distribution shift may be too difficult to overcome with off-policy learning.
Is trajectory simulation necessary? ACT is better-aligned with multi-turn conversations due to its trajectory simulation. Without multi-turn simulation, our approach can be viewed similarly to on-policy DPO variants like IRPO, but with a conversation-specific reward signal which accounts for conversation actions and task heuristics. In “ACT w/ sampling w/o simulation”, we find that this trajectory-level simulation is critical to improving multi-turn performance, especially the policy model’s ability to reason about its own clarification questions.
Is ACT model agnostic? The base model in our main experiments, Zephyr, is obtained by aligning Mistral. In “ACT with unaligned foundation models” we observe a performance gap of 6.5 Action F1 and 4.3 Trajectory F1 after ACT tuning for the two models. However, our results demonstrate ACT can improve performance regardless of pre-existing alignment with human feedback, although it can help as an improved model initialization. Overall, we find that improving base model performance with ACT is model agnostic.
The future of multi-turn conversation modeling
We propose ACT, a model agnostic quasi-online contrastive tuning approach for sample-efficient conversational task adaptation, along with a workflow for evaluation of conversational agents. We demonstrate encouraging evidence that ACT is highly effective for task adaptation in the limited data regime. Future work may also consider combining ACT with existing sophisticated tuning approaches for complex tasks like text-to-SQL generation, as well as generalization to large-scale data and multi-task environments.
Acknowledgements
We are deeply grateful for helpful feedback on our manuscript from Hanjun Dai, and advice from Ta-Chung Chi and Kun Qian. We would also like to recognize Chris Baron and Vipin Nair, whose efforts have been crucial to the success of this work. This work was completed in Google Cloud AI Research where Maximillian Chen was a Student Researcher and Ruoxi Sun was a Research Scientist.
Quick links
Other posts of interest
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-
March 17, 2026
Improving breast cancer screening workflows with machine learning- Health & Bioscience ·
- Human-Computer Interaction and Visualization




