Learning an Accurate Physics Simulator via Adversarial Reinforcement Learning
June 16, 2021
Yifeng Jiang, Research Intern and Jie Tan, Research Scientist, Robotics at Google
Quick links
Simulation empowers various engineering disciplines to quickly prototype with minimal human effort. In robotics, physics simulations provide a safe and inexpensive virtual playground for robots to acquire physical skills with techniques such as deep reinforcement learning (DRL). However, as the hand-derived physics in simulations does not match the real world exactly, control policies trained entirely within simulation can fail when tested on real hardware — a challenge known as the sim-to-real gap or the domain adaptation problem. The sim-to-real gap for perception-based tasks (such as grasping) has been tackled using RL-CycleGAN and RetinaGAN, but there is still a gap caused by the dynamics of robotic systems. This prompts us to ask, can we learn a more accurate physics simulator from a handful of real robot trajectories? If so, such an improved simulator could be used to refine the robot controller using standard DRL training, so that it succeeds in the real world.
In our ICRA 2021 publication “SimGAN: Hybrid Simulator Identification for Domain Adaptation via Adversarial Reinforcement Learning”, we propose to treat the physics simulator as a learnable component that is trained by DRL with a special reward function that penalizes discrepancies between the trajectories (i.e., the movement of the robots over time) generated in simulation and a small number of trajectories that are collected on real robots. We use generative adversarial networks (GANs) to provide such a reward, and formulate a hybrid simulator that combines learnable neural networks and analytical physics equations, to balance model expressiveness and physical correctness. On robotic locomotion tasks, our method outperforms multiple strong baselines, including domain randomization.
A Learnable Hybrid Simulator
A traditional physics simulator is a program that solves differential equations to simulate the movement or interactions of objects in a virtual world. For this work, it is necessary to build different physical models to represent different environments – if a robot walks on a mattress, the deformation of the mattress needs to be taken into account (e.g., with the finite element method). However, due to the diversity of the scenarios that robots could encounter in the real world, it would be tedious (or even impossible) for such environment-specific modeling techniques, which is why it is useful to instead take an approach based on machine learning. Although simulators can be learned entirely from data, if the training data does not include a wide enough variety of situations, the learned simulator might violate the laws of physics (i.e., deviate from the real-world dynamics) if it needs to simulate situations for which it was not trained. As a result, the robot that is trained in such a limited simulator is more likely to fail in the real world.
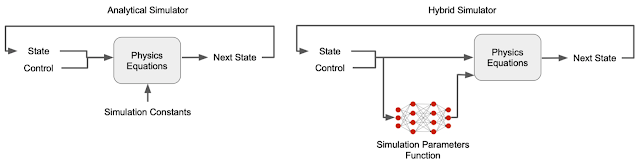
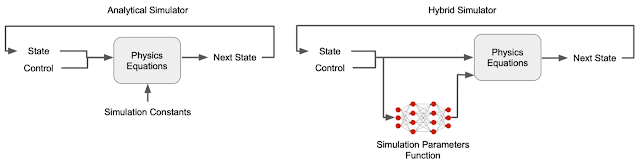
To overcome this complication, we construct a hybrid simulator that combines both learnable neural networks and physics equations. Specifically, we replace what are often manually-defined simulator parameters — contact parameters (e.g., friction and restitution coefficients) and motor parameters (e.g., motor gains) — with a learnable simulation parameter function because the unmodeled details of contact and motor dynamics are major causes of the sim-to-real gap. Unlike conventional simulators in which these parameters are treated as constants, in the hybrid simulator they are state-dependent — they can change according to the state of the robot. For example, motors can become weaker at higher speed. These typically unmodeled physical phenomena can be captured using the state-dependent simulation parameter functions. Moreover, while contact and motor parameters are usually difficult to identify and subject to change due to wear-and-tear, our hybrid simulator can learn them automatically from data. For example, rather than having to manually specify the parameters of a robot’s foot against every possible surface it might contact, the simulation learns these parameters from training data.
 |
| Comparison between a conventional simulator and our hybrid simulator. |
The other part of the hybrid simulator is made up of physics equations that ensure the simulation obeys fundamental laws of physics, such as conservation of energy, making it a closer approximation to the real world and thus reducing the sim-to-real gap.
In our earlier mattress example, the learnable hybrid simulator is able to mimic the contact forces from the mattress. Because the learned contact parameters are state-dependent, the simulator can modulate contact forces based on the distance and velocity of the robot’s feet relative to the mattress, mimicking the effect of the stiffness and damping of a deformable surface. As a result, we do not need to analytically devise a model specifically for deformable surfaces.
Using GANs for Simulator Learning
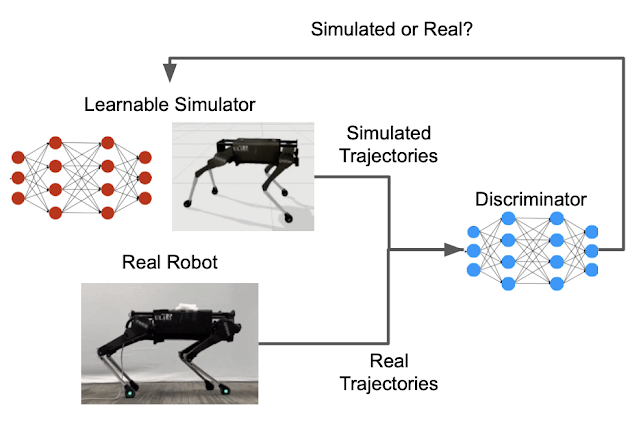
Successfully learning the simulation parameter functions discussed above would result in a hybrid simulator that can generate similar trajectories to the ones collected on the real robot. The key that enables this learning is defining a metric for the similarity between trajectories. GANs, initially designed to generate synthetic images that share the same distribution, or “style,” with a small number of real images, can be used to generate synthetic trajectories that are indistinguishable from real ones. GANs have two main parts, a generator that learns to generate new instances, and a discriminator that evaluates how similar the new instances are to the training data. In this case, the learnable hybrid simulator serves as the GAN generator, while the GAN discriminator provides the similarity scores.
 |
| The GAN discriminator provides the similarity metric that compares the movements of the simulated and the real robot. |
Fitting parameters of simulation models to data collected in the real world, a process called system identification (SysID), has been a common practice in many engineering fields. For example, the stiffness parameter of a deformable surface can be identified by measuring the displacements of the surface under different pressures. This process is typically manual and tedious, but using GANs can be much more efficient. For example, SysID often requires a hand-crafted metric for the discrepancy between simulated and real trajectories. With GANs, such a metric is automatically learned by the discriminator. Furthermore, to calculate the discrepancy metric, conventional SysID requires pairing each simulated trajectory to a corresponding real-world one that is generated using the same control policy. Since the GAN discriminator takes only one trajectory as the input and calculates the likelihood that it is collected in the real world, this one-to-one pairing is not needed.
Using Reinforcement Learning (RL) to Learn the Simulator and Refine the Policy
Putting everything together, we formulate simulation learning as an RL problem. A neural network learns the state-dependent contact and motor parameters from a small number of real-world trajectories. The neural network is optimized to minimize the error between the simulated and the real trajectories. Note that it is important to minimize this error over an extended period of time — a simulation that accurately predicts a more distant future will lead to a better control policy. RL is well suited to this because it optimizes the accumulated reward over time, rather than just optimizing a single-step reward.
After the hybrid simulator is learned and becomes more accurate, we use RL again to refine the robot’s control policy within the simulation (e.g., walking across a surface, shown below).
 |
| Following the arrows clockwise: (upper left) recording a small number of robot's failed attempts in the target domain (e.g., a real-world proxy in which the leg in red is modified to be much heavier than the source domain); (upper right) learning the hybrid simulator to match trajectories collected in the target domain; (lower right) refining control policies in this learned simulator; (lower left) testing the refined controller directly in the target domain. |
Evaluation
Due to limited access to real robots during 2020, we created a second and different simulation (target domain) as a proxy of the real-world. The change of dynamics between the source and the target domains are large enough to approximate different sim-to-real gaps (e.g., making one leg heavier, walking on deformable surfaces instead of hard floor). We assessed whether our hybrid simulator, with no knowledge of these changes, could learn to match the dynamics in the target domain, and if the refined policy in this learned simulator could be successfully deployed in the target domain.
Qualitative results below show that simulation learning with less than 10 minutes of data collected in the target domain (where the floor is deformable) is able to generate a refined policy that performs much better for two robots with different morphologies and dynamics.
 |
| Comparison of performance between the initial and refined policy in the target domain (deformable floor) for the hopper and the quadruped robot. |
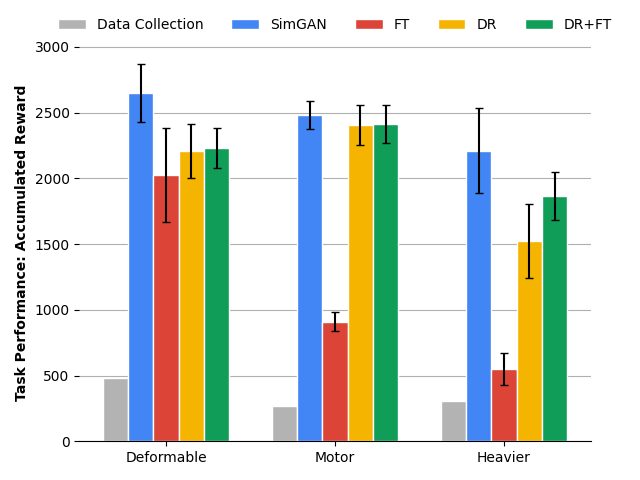
Quantitative results below show that SimGAN outperforms multiple state-of-the-art baselines, including domain randomization (DR) and direct finetuning in target domains (FT).
 |
| Comparison of policy performance using different sim-to-real transfer methods in three different target domains for the Quadruped robot: locomotion on deformable surface, with weakened motors, and with heavier bodies. |
Conclusion
The sim-to-real gap is one of the key bottlenecks that prevents robots from tapping into the power of reinforcement learning. We tackle this challenge by learning a simulator that can more faithfully model real-world dynamics, while using only a small amount of real-world data. The control policy that is refined in this simulator can be successfully deployed. To achieve this, we augment a classical physics simulator with learnable components, and train this hybrid simulator using adversarial reinforcement learning. To date we have tested its application to locomotion tasks, we hope to build on this general framework by applying it to other robot learning tasks, such as navigation and manipulation.
Acknowledgements
We'd like to thank our paper co-authors: Tingnan Zhang, Daniel Ho, Yunfei Bai, C. Karen Liu, and Sergey Levine. We would also like to thank the team members of Robotics at Google for discussions and feedback.
-
Labels:
- Machine Intelligence
- Robotics
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence