Language Models Perform Reasoning via Chain of Thought
May 11, 2022
Posted by Jason Wei and Denny Zhou, Research Scientists, Google Research, Brain team
Quick links
In recent years, scaling up the size of language models has been shown to be a reliable way to improve performance on a range of natural language processing (NLP) tasks. Today’s language models at the scale of 100B or more parameters achieve strong performance on tasks like sentiment analysis and machine translation, even with little or no training examples. Even the largest language models, however, can still struggle with certain multi-step reasoning tasks, such as math word problems and commonsense reasoning. How might we enable language models to perform such reasoning tasks?
In “Chain of Thought Prompting Elicits Reasoning in Large Language Models,” we explore a prompting method for improving the reasoning abilities of language models. Called chain of thought prompting, this method enables models to decompose multi-step problems into intermediate steps. With chain of thought prompting, language models of sufficient scale (~100B parameters) can solve complex reasoning problems that are not solvable with standard prompting methods.
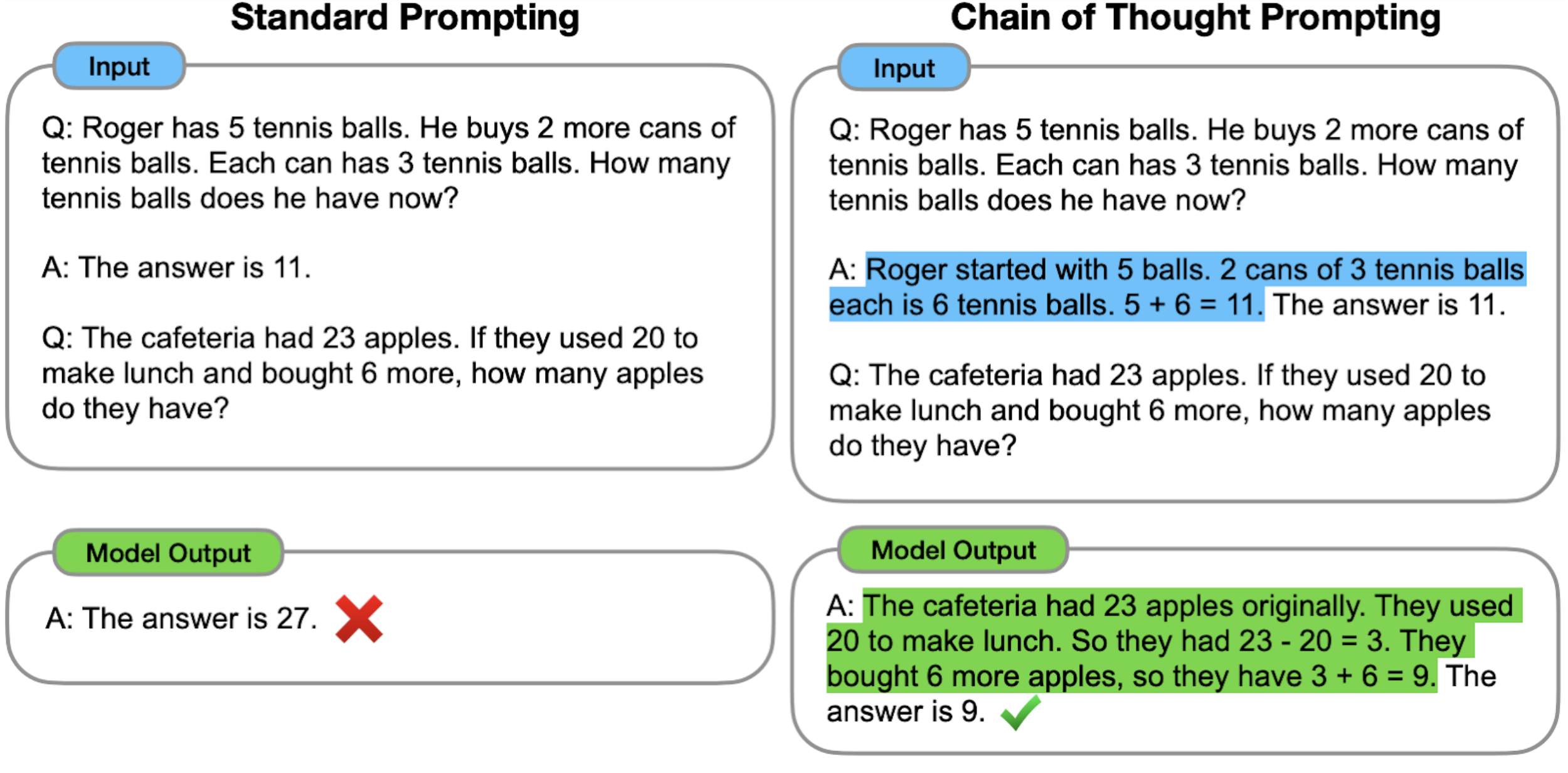
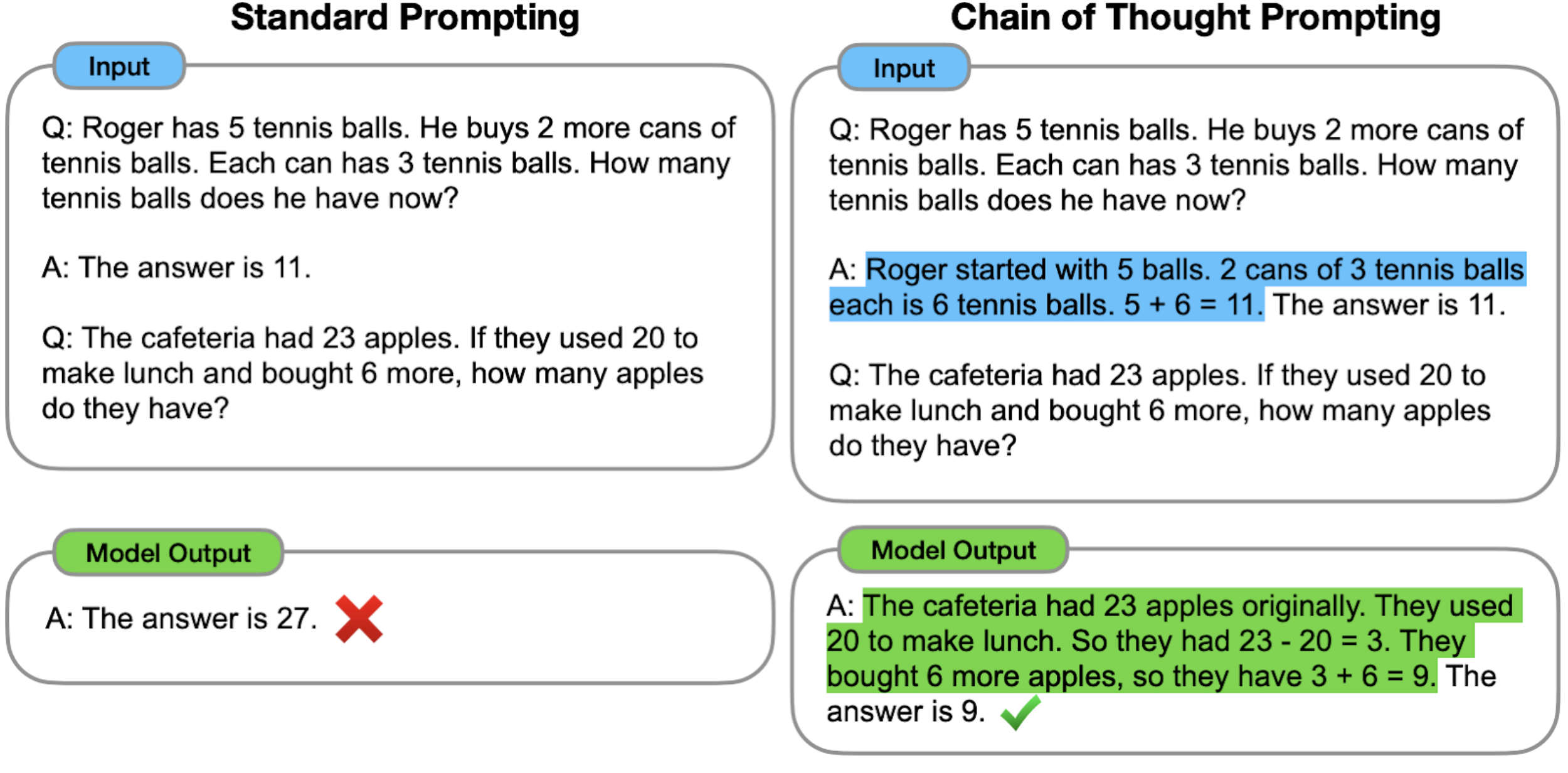
Comparison to Standard Prompting
With standard prompting (popularized by GPT-3) the model is given examples of input–output pairs (formatted as questions and answers) before being asked to predict the answer for a test-time example (shown below on the left). In chain of thought prompting (below, right), the model is prompted to produce intermediate reasoning steps before giving the final answer to a multi-step problem. The idea is that a model-generated chain of thought would mimic an intuitive thought process when working through a multi-step reasoning problem. While producing a thought process has been previously accomplished via fine-tuning, we show that such thought processes can be elicited by including a few examples of chain of thought via prompting only, which does not require a large training dataset or modifying the language model’s weights.
 |
| Whereas standard prompting asks the model to directly give the answer to a multi-step reasoning problem, chain of thought prompting induces the model to decompose the problem into intermediate reasoning steps, in this case leading to a correct final answer. |
Chain of thought reasoning allows models to decompose complex problems into intermediate steps that are solved individually. Moreover, the language-based nature of chain of thought makes it applicable to any task that a person could solve via language. We find through empirical experiments that chain of thought prompting can improve performance on various reasoning tasks, and that successful chain of thought reasoning is an emergent property of model scale — that is, the benefits of chain of thought prompting only materialize with a sufficient number of model parameters (around 100B).
Arithmetic Reasoning
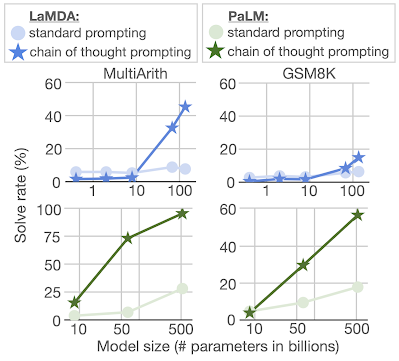
One class of tasks where language models typically struggle is arithmetic reasoning (i.e., solving math word problems). Two benchmarks in arithmetic reasoning are MultiArith and GSM8K, which test the ability of language models to solve multi-step math problems similar to the one shown in the figure above. We evaluate both the LaMDA collection of language models ranging from 422M to 137B parameters, as well as the PaLM collection of language models ranging from 8B to 540B parameters. We manually compose chains of thought to include in the examples for chain of thought prompting.
For these two benchmarks, using standard prompting leads to relatively flat scaling curves: increasing the scale of the model does not substantially improve performance (shown below). However, we find that when using chain of thought prompting, increasing model scale leads to improved performance that substantially outperforms standard prompting for large model sizes.
 |
| Employing chain of thought prompting enables language models to solve arithmetic reasoning problems for which standard prompting has a mostly flat scaling curve. |
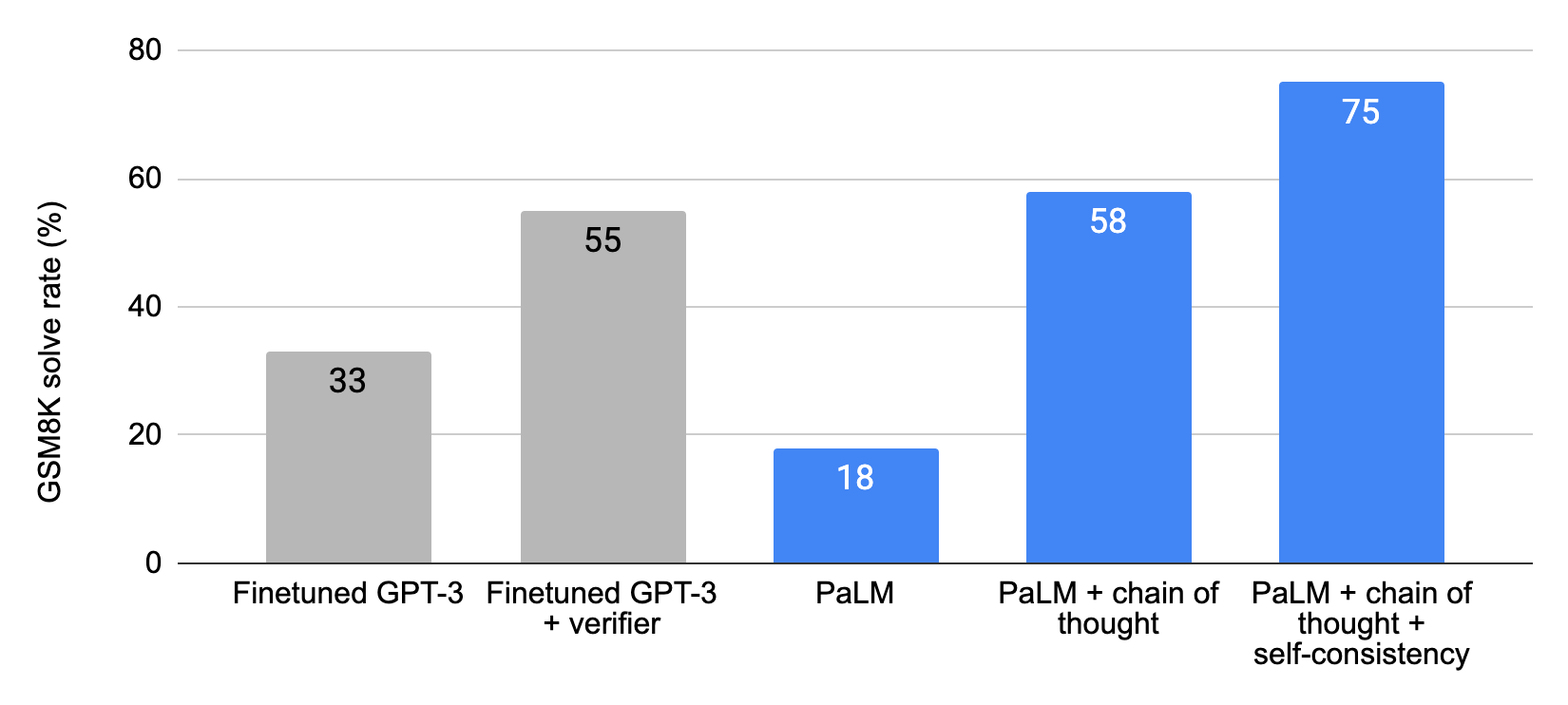
On the GSM8K dataset of math word problems, PaLM shows remarkable performance when scaled to 540B parameters. As shown in the table below, combining chain of thought prompting with the 540B parameter PaLM model leads to new state-of-the-art performance of 58%, surpassing the prior state of the art of 55% achieved by fine-tuning GPT-3 175B on a large training set and then ranking potential solutions via a specially trained verifier. Moreover, follow-up work on self-consistency shows that the performance of chain of thought prompting can be improved further by taking the majority vote of a broad set of generated reasoning processes, which results in 74% accuracy on GSM8K.
 |
| Chain of thought prompting with PaLM achieves a new state of the art on the GSM8K benchmark of math word problems. For a fair comparison against fine-tuned GPT-3 baselines, the chain of thought prompting results shown here also use an external calculator to compute basic arithmetic functions (i.e., addition, subtraction, multiplication and division). |
Commonsense Reasoning
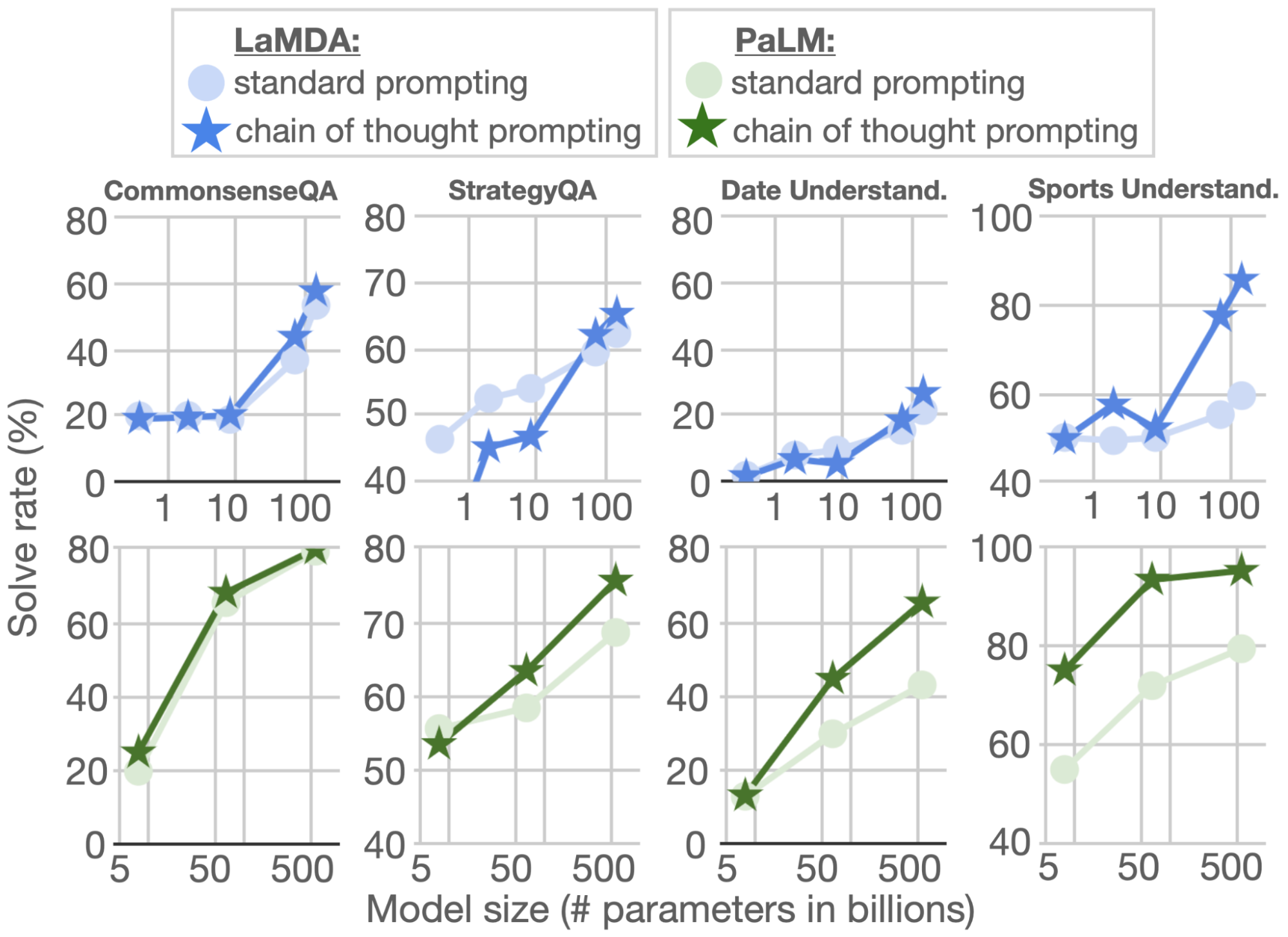
In addition to arithmetic reasoning, we consider whether the language-based nature of chain of thought prompting also makes it applicable to commonsense reasoning, which involves reasoning about physical and human interactions under the presumption of general background knowledge. For these evaluations, we use the CommonsenseQA and StrategyQA benchmarks, as well as two domain-specific tasks from BIG-Bench collaboration regarding date understanding and sports understanding. Example questions are below:
 |
As shown below, for CommonsenseQA, StrategyQA, and Date Understanding, performance improved with model scale, and employing chain of thought prompting led to additional small improvements. Chain of thought prompting had the biggest improvement on sports understanding, for which PaLM 540B’s chain of thought performance surpassed that of an unaided sports enthusiast (95% vs 84%).
 |
| Chain of thought prompting also improves performance on various types of commonsense reasoning tasks. |
Conclusions
Chain of thought prompting is a simple and broadly applicable method for improving the ability of language models to perform various reasoning tasks. Through experiments on arithmetic and commonsense reasoning, we find that chain of thought prompting is an emergent property of model scale. Broadening the range of reasoning tasks that language models can perform will hopefully inspire further work on language-based approaches to reasoning.
Acknowledgements
It was an honor and privilege to work with Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Quoc Le on this project.
-
Labels:
- Conferences & Events
Quick links
Other posts of interest
-

December 12, 2025
Spotlight on innovation: Google-sponsored Data Science for Health Ideathon across Africa- Conferences & Events ·
- Generative AI ·
- Global ·
- Health & Bioscience
-

May 30, 2024
CodecLM: Aligning language models with tailored synthetic data- Conferences & Events ·
- Machine Intelligence ·
- Natural Language Processing
-
May 24, 2024
Google Research at Google I/O 2024- Conferences & Events ·
- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence ·
- Product ·
- Quantum ·
- Responsible AI