Generating Diverse Synthetic Medical Image Data for Training Machine Learning Models
February 19, 2020
Posted by Timo Kohlberger and Yuan Liu, Software Engineers, Google Health
Quick links
The progress in machine learning (ML) for medical imaging that helps doctors provide better diagnoses has partially been driven by the use of large, meticulously labeled datasets. However, dataset size can be limited in real life due to privacy concerns, low patient volume at partner institutions, or by virtue of studying rare diseases. Moreover, to ensure that ML models generalize well, they need training data that span a range of subgroups, such as skin type, demographics, and imaging devices. Requiring that the size of each combinatorial subgroup (e.g., skin type A with skin condition B, taken by camera C) is also sufficiently large can quickly become impractical.
Today we are happy to share two projects aimed at both improving the diversity of ML training data, and increasing the effective amount of available training data for medical applications. The first project is a configurable method for generation of synthetic skin lesion images in order to improve coverage of rarer skin types and conditions. The second project uses synthetic images as training data to develop an ML model, that can better interpret different biological tissue types across a range of imaging devices.
Generating Diverse Images of Skin Conditions
In “DermGAN: Synthetic Generation of Clinical Skin Images with Pathology”, published in the Machine Learning for Health (ML4H) workshop at NeurIPS 2019, we address problems associated with data diversity in de-identified dermatology images taken by consumer grade cameras. This work addresses (1) the scarcity of imaging data representative of rare skin conditions, and (2) the lower frequency of data covering certain Fitzpatrick skin types. Fitzpatrick skin types range from Type I (“pale white, always burns, never tans”) to Type VI (“darkest brown, never burns”), with datasets generally containing relative few cases at the “boundaries”. In both cases, data scarcity problems are exacerbated by the low signal-to-noise ratio common in the target images, due to the lack of standardized lighting, contrast and field-of-view; variability of the background, such as furniture and clothing; and the fine details of the skin, like hair and wrinkles.
To improve diversity in the skin images, we developed a model, called DermGAN, which generates skin images that exhibit the characteristics of a given pre-specified skin condition, location, and underlying skin color. DermGAN uses an image-to-image translation approach, based on the pix2pix generative adversarial network (GAN) architecture, to learn the underlying mapping from one type of image to another.
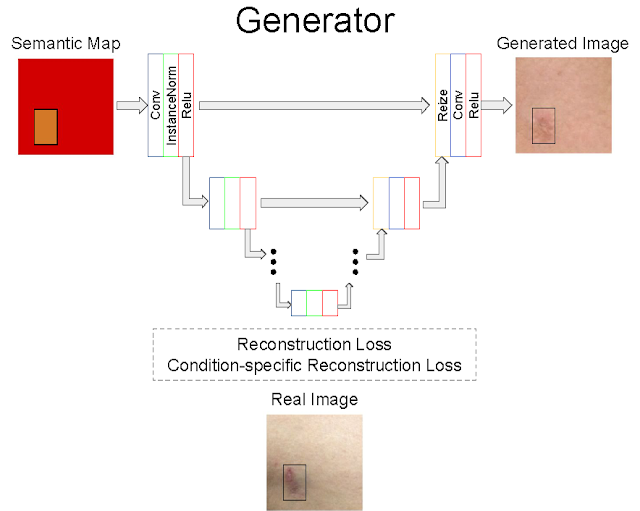
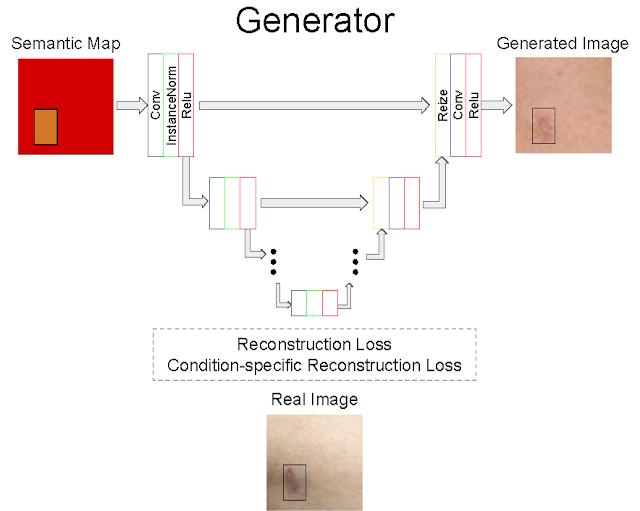
DermGAN takes as input a real image and its corresponding, pre-generated semantic map representing the underlying characteristics of the real image (e.g., the skin condition, location of the lesion, and skin type), from which it will generate a new synthetic example with the requested characteristics. The generator is based on the U-Net architecture, but in order to mitigate checkerboard artifacts, the deconvolution layers are replaced with a resizing layer, followed by a convolution. A few customized losses are introduced to improve the quality of the synthetic images, especially within the pathological region. The discriminator component of DermGAN is solely used for training, whereas the generator is evaluated both visually and for use in augmenting the training dataset for a skin condition classifier.
 |
| Overview of the generator component of DermGAN. The model takes an RGB semantic map (red box) annotated with the skin condition's size and location (smaller orange rectangle), and outputs a realistic skin image. Colored boxes represent various neural network layers, such as convolutions and ReLU; the skip connections resemble the U-Net and enable information to be propagated at the appropriate scales. |
 |
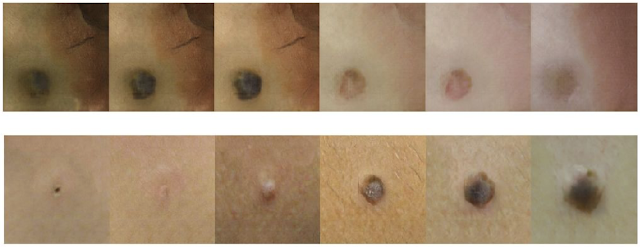
| The top row shows generated synthetic examples and the bottom row illustrates real images of basal cell carcinoma (left) and melanocytic nevus (right). More examples can be found in the paper. |
 |
| DermGAN can be used to generate skin images (all with melanocytic nevus in this case) with different background skin types (top, by changing the input skin color) and different-sized lesions (bottom, by changing the input lesion size). As the input skin color changes, the lesion changes appearance to match what the lesion would look like on different skin types. |
Generating Pathology Images with Different Labels Across Diverse Scanners
The focus quality of medical images is important for accurate diagnoses. Poor focus quality can trigger both false positives and false negatives, even in otherwise accurate ML-based metastatic breast cancer detection algorithms. Determining whether or not pathology images are in-focus is difficult due to factors such as the complexity of the image acquisition process. Digitized whole-slide images could have poor focus across the entire image, but since they are essentially stitched together from thousands of smaller fields of view, they could also have subregions with different focus properties than the rest of the image. This makes manual screening for focus quality impractical and motivates the desire for an automated approach to detect poorly-focused slides and locate out-of-focus regions. Identifying regions with poor focus might enable re-scanning, or yield opportunities to improve the focusing algorithms used during the scanning process.
In our second project, presented in “Whole-slide image focus quality: Automatic assessment and impact on AI cancer detection”, published in the Journal of Pathology Informatics, we develop a method of evaluating de-identified, large gigapixel pathology images for focus quality issues. This involved training a convolutional neural network on semi-synthetic training data that represent different tissue types and slide scanner optical properties. However, a key barrier towards developing such an ML-based system was the lack of labeled data — focus quality is difficult to grade reliably and labeled datasets were not available. To exacerbate the problem, because focus quality affects minute details of the image, any data collected for a specific scanner may not be representative of other scanners, which may have differences in the physical optical systems, the stitching procedure used to recreate a large pathology image from captured image tiles, white-balance and post-processing algorithms, and more. This led us to develop a novel multi-step system for generating synthetic images that exhibit realistic out-of-focus characteristics.
We deconstructed the process of collecting training data into multiple steps. The first step was to collect images from various scanners and to label in-focus regions. This task is substantially easier than trying to determine the degree to which an image is out of focus, and can be completed by non-experts. Next, we generated synthetic out-of-focus images, inspired by the sequence of events that happen prior to a real out-of-focus image is captured: the optical blurring effect happens first, followed by those photons being collected by a sensor (a process that adds sensor noise), and finally software compression adds noise.
 |
| A sequence of images showing step-wise out-of-focus image generation. Images are shown in grayscale to accentuate the difference between steps. First, an in-focus image is collected (a) and a bokeh effect is added to produce a blurry image (b). Next, sensor noise is added to simulate a real image sensor (c), and finally JPEG compression is added to simulate the sharp edges introduced by post-acquisition software processing (d). A real out-of-focus image is shown for comparison (e). |
 |
| An example of a particularly interesting out-of-focus pattern across a biological tissue slice. Areas in blue were recognized by the model to be in-focus, whereas areas highlighted in yellow, orange, or red were more out of focus. The gradation in focus here (represented by concentric circles: a red/orange out-of-focus center surrounded by green/cyan mildly out-of-focus, and then a blue in-focus ring) was caused by a hard “stone” in the center that lifted the surrounding biological tissue. |
Though the volume of data used to develop ML systems is seen as a fundamental bottleneck, we have presented techniques for generating synthetic data that can be used to improve the diversity of training data for ML models and thereby improve the ability of ML to work well on more diverse datasets. We should caution though that these methods are not appropriate for validation data, so as to avoid bias such as an ML model performing well only on synthetic data. To ensure unbiased, statistically-rigorous evaluation, real data of sufficient volume and diversity will still be needed, though techniques such as inverse probability weighting (for example, as leveraged in our work on ML for chest X-rays) may be useful there. We continue to explore other approaches to more efficiently leverage de-identified data to improve data diversity and reduce the need for large datasets in the development of ML models for healthcare.
Acknowledgements
These projects involved the efforts of multidisciplinary teams of software engineers, researchers, clinicians and cross functional contributors. Key contributors to these projects include Timo Kohlberger, Yun Liu, Melissa Moran, Po-Hsuan Cameron Chen, Trissia Brown, Jason Hipp, Craig Mermel, Martin Stumpe, Amirata Ghorbani, Vivek Natarajan, David Coz, and Yuan Liu. The authors would also like to acknowledge Daniel Fenner, Samuel Yang, Susan Huang, Kimberly Kanada, Greg Corrado and Erica Brand for their advice, members of the Google Health dermatology and pathology teams for their support, and Ashwin Kakarla and Shivamohan Reddy Garlapati for their team for image labeling.
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯