Exploring Weight Agnostic Neural Networks
August 27, 2019
Posted by Adam Gaier, Student Researcher and David Ha, Staff Research Scientist, Google Research, Tokyo
Quick links
When training a neural network to accomplish a given task, be it image classification or reinforcement learning, one typically refines a set of weights associated with each connection within the network. Another approach to creating successful neural networks that has shown substantial progress is neural architecture search, which constructs neural network architectures out of hand-engineered components such as convolutional network components or transformer blocks. It has been shown that neural network architectures built with these components, such as deep convolutional networks, have strong inductive biases for image processing tasks, and can even perform them when their weights are randomly initialized. While neural architecture search produces new ways of arranging hand-engineered components with known inductive biases for the task domain at hand, there has been little progress in the automated discovery of new neural network architectures with such inductive biases, for various task domains.
We can look at analogies to these useful components in examples of nature vs. nurture. Just as certain precocial species in biology—who possess anti-predator behaviors from the moment of birth—can perform complex motor and sensory tasks without learning, perhaps we can construct network architectures that can perform well without training. Of course, these natural (and by analogy, artificial) neural networks are further improved through training, but their ability to perform even without learning shows that they contain biases that make them well-suited to their task.
In “Weight Agnostic Neural Networks” (WANN), we present a first step toward searching specifically for networks with these biases: neural net architectures that can already perform various tasks, even when they use a random shared weight. Our motivation in this work is to question to what extent neural network architectures alone, without learning any weight parameters, can encode solutions for a given task. By exploring such neural network architectures, we present agents that can already perform well in their environment without the need to learn weight parameters. Furthermore, in order to spur progress in this field community, we have also open-sourced the code to reproduce our WANN experiments for the broader research community.
 |
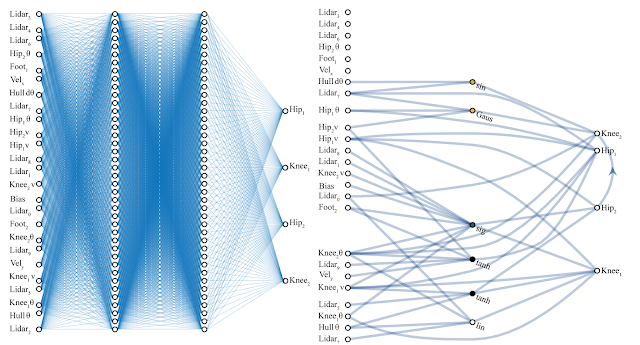
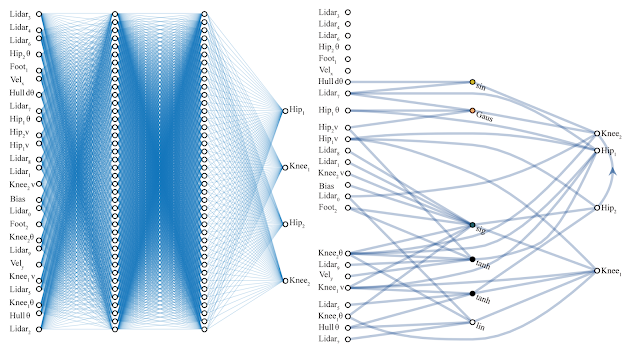
| Left: A hand-engineered, fully-connected deep neural network with 2760 weight connections. Using a learning algorithm, we can solve for the set of 2760 weight parameters so that this network can perform the BipedalWalker-v2 task. Right: A weight agnostic neural network architecture with 44 connections that can perform the same Bipedal Walker task. Unlike the fully-connected network, this WANN can still perform the task without the need to train the weight parameters of each connection. In fact, to simplify the training, the WANN is designed to perform when the values of each weight connection are identical, or shared, and it will even function if this shared weight parameter is randomly sampled. |
We start with a population of minimal neural network architecture candidates, each with very few connections only, and use a well-established topology search algorithm (NEAT), to evolve the architectures by adding single connections and single nodes one by one. The key idea behind WANNs is to search for architectures by de-emphasizing weights. Unlike traditional neural architecture search methods, where all of the weight parameters of new architectures need to be trained using a learning algorithm, we take a simpler and more efficient approach. Here, during the search, all candidate architectures are first assigned a single shared weight value at each iteration, and then optimized to perform well over a wide range of shared weight values.
 |
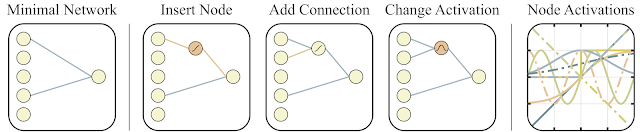
| Operators for searching the space of network topologies Left: A minimal network topology, with input and outputs only partially connected. Middle: Networks are altered in one of three ways: (1) Insert Node: a new node is inserted by splitting an existing connection. (2) Add Connection: a new connection is added by connecting two previously unconnected nodes. (3) Change Activation: the activation function of a hidden node is reassigned. Right: Possible activation functions (linear, step, sin, cosine, Gaussian, tanh, sigmoid, inverse, absolute value, ReLU) |
 |
| Overview of Weight Agnostic Neural Network Search and corresponding operators for searching the space of network topologies. |
Unlike traditional networks, we can easily train the WANN by simply finding the best single shared weight parameter that maximizes its performance. In the example below, we see that our architecture works (to some extent) for a swing-up cartpole task using constant weights:
 |  |
| A WANN performing a Cartpole Swing-up task at various different weight parameters, and also using fine-tuned weight parameters. |
 |  |
| Through the use of multi-objective optimization for both performance and network simplicity, our method found a simple WANN for a Car Racing from pixels task that works well without explicitly training for the weights of the network. |
 |
| An MNIST classifier evolved to work with random weights. |
Even without ensemble methods, collapsing the number of weight values in a network to one allows the network to be rapidly tuned. The ability to quickly fine-tune weights might be useful in continual lifelong learning, where agents acquire, adapt, and transfer skills throughout their lifespan. This makes WANNs particularly well positioned to exploit the Baldwin effect, the evolutionary pressure that rewards individuals predisposed to learn useful behaviors, without being trapped in the computationally expensive trap of ‘learning to learn’.
Conclusion
We hope that this work can serve as a stepping stone to help discover novel fundamental neural network components such as the convolutional network, whose discovery and application have been instrumental to the incredible progress made in deep learning. The computational resources available to the research community have grown significantly since the time convolutional neural networks were discovered. If we are devoting such resources to automated discovery and hope to achieve more than incremental improvements in network architectures, we believe it is also worth searching for with new building blocks, not just their arrangements.
If you are interested to learn more about this work, we invite readers to read our interactive article (or pdf version of the paper for offline reading). In addition to open sourcing these experiments to the research community, we have also released a general Python implementation of NEAT called PrettyNEAT to help interested readers to explore the exciting area of neural network evolution from first principles.
-
Labels:
- Machine Intelligence
Quick links
Other posts of interest
-

April 9, 2026
ConvApparel: Measuring and bridging the realism gap in user simulators- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
×
❮
❯