Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning
February 3, 2021
Posted by Mohammad Babaeizadeh, Research Engineer and Dumitru Erhan, Research Scientist, Google Research
Quick links
Model-free reinforcement learning has been successfully demonstrated across a range of domains, including robotics, control, playing games and autonomous vehicles. These systems learn by simple trial and error and thus require a vast number of attempts at a given task before solving it. In contrast, model-based reinforcement learning (MBRL) learns a model of the environment (often referred to as a world model or a dynamics model) that enables the agent to predict the outcomes of potential actions, which reduces the amount of environment interaction needed to solve a task.
In principle, all that is strictly necessary for planning is to predict future rewards, which could then be used to select near-optimal future actions. Nevertheless, many recent methods, such as Dreamer, PlaNet, and SimPLe, additionally leverage the training signal of predicting future images. But is predicting future images actually necessary, or helpful? What benefit do visual MBRL algorithms actually derive from also predicting future images? The computational and representational cost of predicting entire images is considerable, so understanding whether this is actually useful is of profound importance for MBRL research.
In “Models, Pixels, and Rewards: Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning”, we demonstrate that predicting future images provides a substantial benefit, and is in fact a key ingredient in training successful visual MBRL agents. We developed a new open-source library, called the World Models Library, which enabled us to rigorously evaluate various world model designs to determine the relative impact of image prediction on returned rewards for each.
World Models Library
The World Models Library, designed specifically for visual MBRL training and evaluation, enables the empirical study of the effects of each design decision on the final performance of an agent across multiple tasks on a large scale. The library introduces a platform-agnostic visual MBRL simulation loop and the APIs to seamlessly define new world-models, planners and tasks or to pick and choose from the existing catalog, which includes agents (e.g., PlaNet), video models (e.g., SV2P), and a variety of DeepMind Control tasks and planners, such as CEM and MPPI.
Using the library, developers can study the effect of a varying factor in MBRL, such as the model design or representation space, on the performance of the agent on a suite of tasks. The library supports the training of the agents from scratch, or on a pre-collected set of trajectories, as well as evaluation of a pre-trained agent on a given task. The models, planning algorithms and the tasks can be easily mixed and matched to any desired combination.
To provide the greatest flexibility for users, the library is built using the NumPy interface, which enables different components to be implemented in either TensorFlow, Pytorch or JAX. Please look at this colab for a quick introduction.
Impact of Image Prediction
Using the World Models Library, we trained multiple world models with different levels of image prediction. All of these models use the same input (previously observed images) to predict an image and a reward, but they differ on what percentage of the image they predict. As the number of image pixels predicted by the agent increases, the agent performance as measured by the true reward generally improves.
 |
| The input to the model is fixed (previous observed images), but the fraction of the image predicted varies. As can be seen in the graph on the right, increasing the number of predicted pixels significantly improves the performance of the model. |
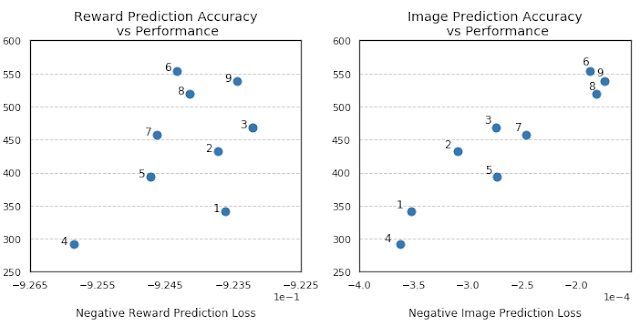
Interestingly, the correlation between reward prediction accuracy and agent performance is not as strong, and in some cases a more accurate reward prediction can even result in lower agent performance. At the same time, there is a strong correlation between image reconstruction error and the performance of the agent.
 |
| Correlation between accuracy of image/reward prediction (x-axis) and task performance (y-axis). This graph clearly demonstrates a stronger correlation between image prediction accuracy and task performance. |
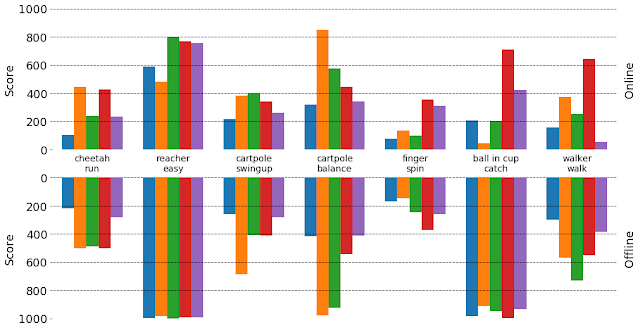
This phenomenon is directly related to exploration, i.e., when the agent attempts more risky and potentially less rewarding actions in order to collect more information about the unknown options in the environment. This can be shown by testing and comparing models in an offline setup (i.e., learning policies from pre-collected datasets, as opposed to online RL, which learns policies by interacting with an environment). An offline setup ensures that there is no exploration and all of the models are trained on the same data. We observed that models that fit the data better usually perform better in the offline setup, and surprisingly, these may not be the same models that perform the best when learning and exploring from scratch.
 |
| Scores achieved by different visual MBRL models across different tasks. The top and bottom half of the graph visualizes the achieved score when trained in the online and offline settings for each task, respectively. Each color is a different model. It is common for a poorly-performing model in the online setting to achieve high scores when trained on pre-collected data (the offline setting) and vice versa. |
Conclusion
We have empirically demonstrated that predicting images can substantially improve task performance over models that only predict the expected reward. We have also shown that the accuracy of image prediction strongly correlates with the final task performance of these models. These findings can be used for better model design and can be particularly useful for any future setting where the input space is high-dimensional and collecting data is expensive.
If you'd like to develop your own models and experiments, head to our repository and colab where you'll find instructions on how to reproduce this work and use or extend the World Models Library.
Acknowledgement:
We would like to give special recognition to multiple researchers in the Google Brain team and co-authors of the paper: Mohammad Taghi Saffar, Danijar Hafner, Harini Kannan, Chelsea Finn and Sergey Levine.
-
Labels:
- Robotics
Quick links
Other posts of interest
-

August 29, 2023
SayTap: Language to quadrupedal locomotion- Machine Intelligence ·
- Robotics
-

August 22, 2023
Language to rewards for robotic skill synthesis- Machine Intelligence ·
- Robotics
-

May 26, 2023
Barkour: Benchmarking animal-level agility with quadruped robots- Hardware & Architecture ·
- Machine Intelligence ·
- Robotics