
Contrastive neural audio separation
April 12, 2024
Posted by Yang Yang, Software Engineer, Core ML, and Shao-Fu Shih, Software Engineer, Pixel
Quick links
Audio spatial separation, i.e., isolating sounds from a mixture with various angles of arrival, is a fundamental topic in the field of audio processing. The task is to leverage the spatial diversity of audio captured from multiple microphones commonly available on portable devices, such as phones, tablets, smart speakers, and laptops, to separate audio sources in designated angular regions from the remaining interference.
Conventional linear beamformer approaches derive their output from a linear combination of multi-channel audio inputs in the time/frequency domain. The linear weights are usually derived assuming a fixed microphone geometry and various estimations of speech and noise statistics. In most neural beamformer approaches, weights can be adaptive and learned through data. While these approaches achieve good spatial separation results with large microphone arrays, they inherently face a quality bottleneck due to the limited capacity of linear processing. This limitation becomes particularly pronounced in devices with only two or three microphones, restricting their spatial separation performance.
People can localize and separate sound from different spatial directions to focus on an audio signal of interest using just two channel inputs from our ears. Our brain processes these signals by utilizing the subtle differences in the relative timing and intensity of different components of sounds, among other cues. This inspires us to ask: can we train a machine learning (ML) model to exploit the relative delays and gains of different signal components from multiple microphones to optimize the quality of spatial separation?
In “Binaural Angular Separation Network” (BASNet), presented at ICASSP 2024, and “Guided Speech Enhancement Network” (GSENet), presented at ICASSP 2023, we tackle this question by designing a data simulation pipeline along with a training task that challenges a model to exploit the delay and gain contrast from two microphones. We demonstrate that this solution achieves up to 40 decibels (dB) suppression of interference while preserving the signal of interest when evaluated using real-life recordings.
Delay and gain contrasts
For a given device with two microphones and a single audio source, the time difference of arrival (TDoA) refers to the difference in the time it takes the sound wave to reach each microphone. The inter-microphone level difference (ILD) refers to the difference in sound wave energy (i.e., loudness, often measured in dB), between the two microphones. When presented with multiple audio sources, we define delay contrast as the difference in their TDoA and gain contrast as the difference in their ILD.
In the left figure below, we show a device with two microphones (mic-1 and mic-2) with multiple nearby audio sources represented using shapes (circle, star, triangle, and rhombus). If we compare the red circle and blue star, we expect the signal from the red circle audio source to be captured by the two microphones with the same arrival time since both microphones are an equal distance away. In contrast, mic-1 captures the signal from the blue star earlier than mic-2 due to the difference in their separation from the source. In other words, the two audio sources can be contrasted with their TDoA on the two microphones. Similarly, the two sources incur different ILD. For the red circle audio source, the energy levels on both microphones are the same, whereas for the blue star audio source, the energy level of its signal on the closest microphone, mic-1, is higher than that of mic-2. In the right figure, we map each audio source to its TDoA and ILD. The difference in the x-coordinates amongst the multiple audio sources is what we refer to as their delay contrast, and the difference in the y-coordinates is what we refer to as their gain contrast.
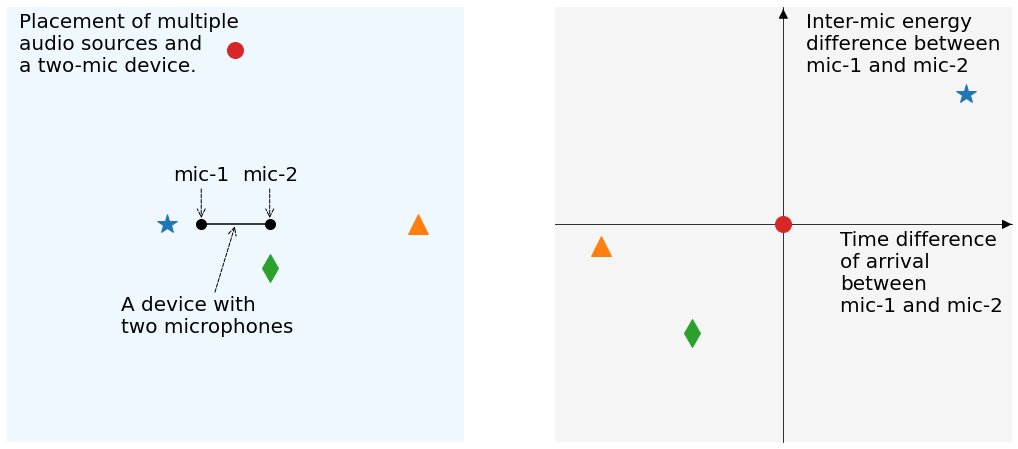
Left: Multiple audio sources and a two-mic device. The circle, star, triangle, and rhombus represent single audio sources. Right: The TDoA and ILD for each audio source.
Neural audio separation using contrasts
In BASNet and GSENet, we task a neural network model to separate audio signals based on their delay contrast or gain contrast, respectively. In both cases, we design the network as a causal Residual-Conv-UNet that works in the short-time Fourier transform domain and can be applied in streaming mode for real-time inference. The model takes two channels of audio as input and outputs a single channel. In the training data pipeline, we use a room impulse response (RIR) simulator to generate RIRs that capture diverse environments (e.g., varying room shapes) and audio propagation characteristics (e.g., acoustic reflection and absorption characteristics). We then create a delay or gain contrast between the target signal we intend to preserve and an interference signal that we intend to suppress. The training task is to separate the target audio signal from a mixture of the target audio signal and an interference signal.
In the training of BASNet, to create a delay contrast between the target and the inference, we divide the spatial region in the RIR simulator into two non-overlapping angular regions relative to two randomly placed microphones, where the target comes from one specific angular region, and the interference comes from the other. Note that target region is a parameter that is configurable during training, and we can train a model to focus on arbitrary directions of interest.The inter-microphone distance in the RIR simulator is configured to match that of the real device on which we plan to run the model. In the training of GSENet, both audio sources and the target source are randomly spatially placed. To create gain contrast, consistent gains are applied to the target audio signal on one of the microphones.
Results
Despite its simplicity, this training method has proven to be quite effective. BASNet models, trained with delay-contrast inputs, obtain up to 40dB suppression of signals (i.e., rejecting 99.99% of the interference energy) from interference directions (configurable as part of RIR parameters) while preserving signal from target directions with little distortion using two microphones. This audio separation capability enables a better user experience for use-cases like teleconferences where we want to isolate the speech signal within the camera's field of view and reject audio signals from other directions.
|
Two-channel input with two |
BASNet model output |
| Input and output audio samples using the BASNet model. |
To measure its directivity pattern, we collect audio recordings using a device with two microphones placed in an anechoic chamber, where each recording is collected with a single audio source placed at various angles relative to the device. Below, we visualize the amount of energy suppression in the output of a BASNet model, as a function of the direction of the input audio source. There is a clear boundary between the region where the signals are preserved (output energy reduction close to 0dB) and where the signals are suppressed (output energy reduction below -20dB, i.e., rejecting more than 99% of the interference energy).
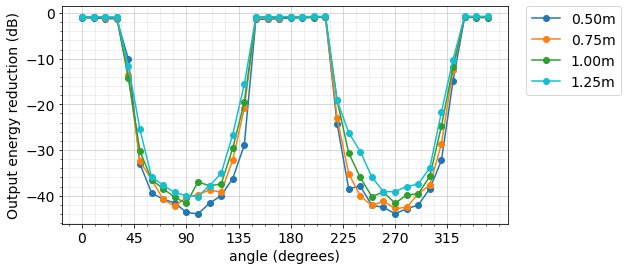
Directivity pattern of a BASNet model trained to focus on [-45°, 45°], evaluated using four sets of audio source distances.
Further, the directivity pattern of a trained model can be steered easily by applying artificial sample delays to one of the two microphones inputs.
Steering of BASNet’s directivity pattern with artificial sample offsets applied to one of the two input channels at the sample rate of 48kHz. The two input microphones are separated by 16cm.
The GSENet model can effectively isolate the audio signal whose energy level in one channel is larger than the other. The capability for the model to identify and utilize gain contrast for audio separation is helpful in two ways:
- It allows us to separate nearby target audio sources from far away audio sources, where the former has a larger ILD compared to the latter.
- It can identify the gain contrast from a traditional beamformer and boost its spatial suppression performance, by using the beamformer output and one microphone's raw audio signal as the two-channel input.
Further, we find that speech-denoising, dereverberation, and spatial separation can be coupled together in one model so that it relies on both the signal pattern and signal contrast to derive its output.
On-Device inference
We studied the real-time inference performance of both BASNet and GSENet using Google Tensor. Specifically, we tested and compared the latency and power consumption between ARM Cortex-A and edgeTPU. For edgeTPU inference, we used the edgeTPU compiler to convert the model into FP16 precision. The experiment revealed that edgeTPU demonstrated a significant advantage in terms of both power efficiency and processing time, being approximately 25% more power-efficient and five times faster than ARM Cortex-A (1.2ms vs. 6ms) when performing model inference, with no perceivable audio quality differences from reduced precision inference.
Additional samples
We showcase the capabilities of BASNet and GSENet by providing the following samples.
| Angle of target speech | Angle of interference speech | BASNet input two channel audio | BASNet output audio | |
| 0° | N/A | |||
| 90° | ||||
| 270° | ||||
| Separating speech from different spatial angles utilizing a BASNet model, trained to preserve audio signal from 0° with a +-45° opening angle and reject signals from other directions. |
| Target music at 90° |
Interference music at 0° |
BASNet input two channel audio (BASNet trained to target 90°) |
BASNet output audio |
| music-1 | music-2 | ||
| music-2 | music-1 |
| Separating music from different spatial angles utilizing delay contrast using a BASNet model trained to preserve audio signal from 90° with a +-45° opening angle and reject signals from other directions. |
| Recording on a mobile device with two microphones | |
| Output after applying GSENet |
| Separating near-field (personal speaking while holding a two-microphone device with one mic close to speaker’s mouth) and far-field speech signals (from a TV about 2 meters away) utilizing a GSENet model.. |
Acknowledgements
This blog post is made on behalf of all BASNet and GSENet authors including: George Sung, Hakan Erdogan, Chehung Lee, Yunpeng Li and Matthias Grundmann. We would like thank Jiuqiang Tang, David Massoud, Esha Uboweja, Luigi Zevola, Carter Hsu, Jenny Wong, Per Åhgren, Craig Dooley, Alessio Centazzo and Brian Lo for on-device implementation, validation, and data collection. Thanks to Helen Gu, Dongdong Li, Qiumin Xu, Situ Yi, Feiyu Chen, Greg Clemson, Clément Faber, Mohamad El-hage, and Aaron Master for their support on optimizing and profiling for the edgeTPU on Google Tensor.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence

Left: Multiple audio sources and a two-mic device. The circle, star, triangle, and rhombus represent single audio sources. Right: The TDoA and ILD for each audio source.

Directivity pattern of a BASNet model trained to focus on [-45°, 45°], evaluated using four sets of audio source distances.