Closing the Simulation-to-Reality Gap for Deep Robotic Learning
October 31, 2017
Posted by Konstantinos Bousmalis, Senior Research Scientist, and Sergey Levine, Faculty Advisor, Google Brain Team
Quick links
Each of us can learn remarkably complex skills that far exceed the proficiency and robustness of even the most sophisticated robots, when it comes to basic sensorimotor skills like grasping. However, we also draw on a lifetime of experience, learning over the course of multiple years how to interact with the world around us. Requiring such a lifetime of experience for a learning-based robot system is quite burdensome: the robot would need to operate continuously, autonomously, and initially at a low level of proficiency before it can become useful. Fortunately, robots have a powerful tool at their disposal: simulation.
Simulating many years of robotic interaction is quite feasible with modern parallel computing, physics simulation, and rendering technology. Moreover, the resulting data comes with automatically-generated annotations, which is particularly important for tasks where success is hard to infer automatically. The challenge with simulated training is that even the best available simulators do not perfectly capture reality. Models trained purely on synthetic data fail to generalize to the real world, as there is a discrepancy between simulated and real environments, in terms of both visual and physical properties. In fact, the more we increase the fidelity of our simulations, the more effort we have to expend in order to build them, both in terms of implementing complex physical phenomena and in terms of creating the content (e.g., objects, backgrounds) to populate these simulations. This difficulty is compounded by the fact that powerful optimization methods based on deep learning are exceptionally proficient at exploiting simulator flaws: the more powerful the machine learning algorithm, the more likely it is to discover how to "cheat" the simulator to succeed in ways that are infeasible in the real world. The question then becomes: how can a robot utilize simulation to enable it to perform useful tasks in the real world?
The difficulty of transferring simulated experience into the real world is often called the "reality gap." The reality gap is a subtle but important discrepancy between reality and simulation that prevents simulated robotic experience from directly enabling effective real-world performance. Visual perception often constitutes the widest part of the reality gap: while simulated images continue to improve in fidelity, the peculiar and pathological regularities of synthetic pictures, and the wide, unpredictable diversity of real-world images, makes bridging the reality gap particularly difficult when the robot must use vision to perceive the world, as is the case for example in many manipulation tasks. Recent advances in closing the reality gap with deep learning in computer vision for tasks such as object classification and pose estimation provide promising solutions. For example, Shrivastava et al. and Bousmalis et al. explored pixel-level domain adaptation. Ganin et al. and Bousmalis and Trigeorgis et al. focus on feature-level domain adaptation. These advances required a rethinking of the approaches used to solve the simulation-to-reality domain shift problem for robotic manipulation as well. Although a number of recent works have sought to address the reality gap in robotics, through techniques such as machine learning-based domain adaptation (Tzeng et al.) and randomization of simulated environments (Sadeghi and Levine), effective transfer in robotic manipulation has been limited to relatively simple tasks, such as grasping rectangular, brightly-colored objects (Tobin et al. and James et al.) and free-space motion (Christiano et al.). In this post, we describe how learning in simulation, in our case PyBullet, and using domain adaptation methods such as machine learning methods that deal with the simulation-to-reality domain shift, can accelerate learning of robotic grasping in the real world. This approach can enable real robots to grasp large of variety physical objects, unseen during training, with a high degree of proficiency.
 |
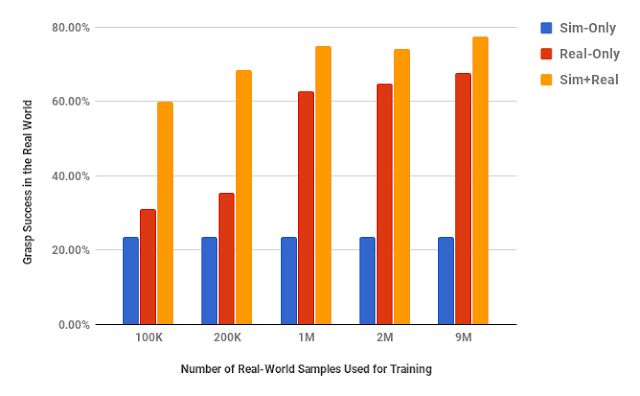
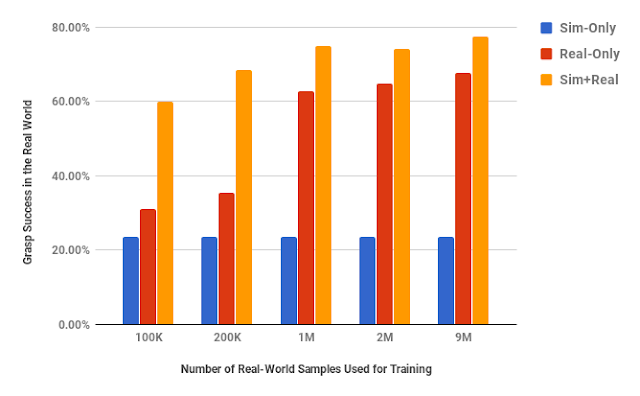
| The performance effect of using 8 million simulated samples of procedural objects with no randomization and various amounts of real data. |
Before we consider introducing simulated experience, what does it take for our robots to learn to reliably grasp such not-before-seen objects with only real-world experience? In a previous post, we discussed how the Google Brain team and X’s robotics teams teach robots how to grasp a variety of ordinary objects by just using images from a single monocular camera. It takes tens to hundreds of thousands of grasp attempts, the equivalent of thousands of robot-hours of real-world experience. Although distributing the learning across multiple robots expedites this, the realities of real-world data collection, including maintenance and wear-and-tear, mean that these kinds of data collection efforts still take a significant amount of real time. As mentioned above, an appealing alternative is to use off-the-shelf simulators and learn basic sensorimotor skills like grasping in a virtual environment. Training a robot how to grasp in simulation can be parallelized easily over any number of machines, and can provide large amounts of experience in dramatically less time (e.g., hours rather than months) and at a fraction of the cost.
If the goal is to bridge the reality gap for vision-based robotic manipulation, we must answer a few critical questions. First, how do we design simulation so that simulated experience appears realistic to a neural network? And second, how should we integrate simulated and real experience in a way that maximizes transfer to the real world? We studied these questions in the context of a particularly challenging and important robotic manipulation task: vision-based grasping of diverse objects. We extensively evaluated the effect of various simulation design decisions in combination with various techniques for integrating simulated and real experience for maximal performance.
 |
| The setup we used for collecting the simulated and real-world datasets. |
 |
| Images used during training of simulated grasping experience with procedurally generated objects (left) and of real-world experience with a varied collection of everyday physical objects (right). In both cases, we see pairs of image inputs with and without the robot arm present. |
 |
| Some of the procedurally-generated objects used in simulation. |
 |
| Some of the ShapeNet objects used in simulation. |
 |
| Some of the physical objects used to collect real grasping experience. |
 |
| Appearance randomization in simulation. |
Our main proposed approach to integrating simulated and real experience, which we call GraspGAN, takes as input synthetic images generated by a simulator, along with their semantic maps, and produces adapted images that look similar to real-world ones. This is possible with adversarial training, a powerful idea proposed by Goodfellow et al. In our framework, a convolutional neural network, the generator, takes as input synthetic images and generates images that another neural network, the discriminator, cannot distinguish from actual real images. The generator and discriminator networks are trained simultaneously and improve together, resulting in a generator that can produce images that are both realistic and useful for learning a grasping model that will generalize to the real world. One way to make sure that these images are useful is the use of the semantic maps of the synthetic images to ground the generator. By using the prediction of these masks as an auxiliary task, the generator is encouraged to produce meaningful adapted images that correspond to the original label attributed to the simulated experience. We train a deep vision-based grasping model with both visually-adapted simulated and real images, and attempt to account for the domain shift further by using a feature-level domain adaptation technique which helps produce a domain-invariant model. See below the GraspGAN adapting simulated images to realistic ones and a semantic map it infers.
By using synthetic data and domain adaptation we are able to reduce the number of real-world samples required to achieve a given level of performance by up to 50 times, using only randomly generated objects in simulation. This means that we have no prior information about the objects in the real world, other than pre-specified size limits for the graspable objects. We have shown that we are able to increase performance with various amounts of real-world data, and also that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with hundreds of thousands of labeled real-world samples. This suggests that, instead of collecting labeled experience, it may be sufficient in the future to simply record raw unlabeled images, use them to train a GraspGAN model, and then learn the skills themselves in simulation.
Although this work has not addressed all the issues around closing the reality gap, we believe that our results show that using simulation and domain adaptation to integrate simulated and real robotic experience is an attractive choice for training robots. Most importantly, we have extensively evaluated the performance gains for different available amounts of labeled real-world samples, and for the different design choices for both the simulator and the domain adaptation methods used. This evaluation can hopefully serve as a guide for practitioners to use for their own design decisions and for weighing the advantages and disadvantages of incorporating such an approach in their experimental design.
This research was conducted by K. Bousmalis, A. Irpan, P. Wohlhart, Y. Bai, M, Kelcey, M. Kalakrishnan, L. Downs, J. Ibarz, P. Pastor, K. Konolige, S. Levine, V. Vanhoucke, with special thanks to colleagues at Google Research and X who've contributed their expertise and time to this research. An early preprint is available on arXiv.
The collection of procedurally-generated objects we used in simulation was made publicly available here by Laura Downs.
Quick links
Other posts of interest
-

March 31, 2026
Building better AI benchmarks: How many raters are enough?- Algorithms & Theory ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 24, 2026
TurboQuant: Redefining AI efficiency with extreme compression- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
×
❮
❯