Characterizing Emergent Phenomena in Large Language Models
November 10, 2022
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team
Quick links
The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data. Scaling up the size of language models often leads to improved performance and sample efficiency on a range of downstream NLP tasks. In many cases, the performance of a large language model can be predicted by extrapolating the performance trend of smaller models. For instance, the effect of scale on language model perplexity has been empirically shown to span more than seven orders of magnitude.
On the other hand, performance for certain other tasks does not improve in a predictable fashion. For example, the GPT-3 paper showed that the ability of language models to perform multi-digit addition has a flat scaling curve (approximately random performance) for models from 100M to 13B parameters, at which point the performance jumped substantially. Given the growing use of language models in NLP research and applications, it is important to better understand abilities such as these that can arise unexpectedly.
In “Emergent Abilities of Large Language Models,” recently published in the Transactions on Machine Learning Research (TMLR), we discuss the phenomena of emergent abilities, which we define as abilities that are not present in small models but are present in larger models. More specifically, we study emergence by analyzing the performance of language models as a function of language model scale, as measured by total floating point operations (FLOPs), or how much compute was used to train the language model. However, we also explore emergence as a function of other variables, such as dataset size or number of model parameters (see the paper for full details). Overall, we present dozens of examples of emergent abilities that result from scaling up language models. The existence of such emergent abilities raises the question of whether additional scaling could potentially further expand the range of capabilities of language models.
Emergent Prompted Tasks
First we discuss emergent abilities that may arise in prompted tasks. In such tasks, a pre-trained language model is given a prompt for a task framed as next word prediction, and it performs the task by completing the response. Without any further fine-tuning, language models can often perform tasks that were not seen during training.
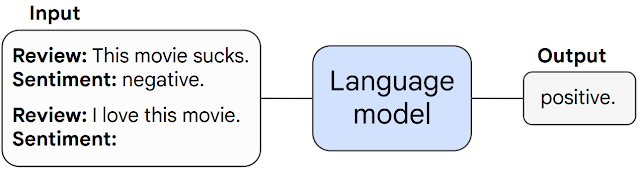
 |
| Example of few-shot prompting on movie review sentiment classification. The model is given one example of a task (classifying a movie review as positive or negative) and then performs the task on an unseen example. |
We call a prompted task emergent when it unpredictably surges from random performance to above-random at a specific scale threshold. Below we show three examples of prompted tasks with emergent performance: multi-step arithmetic, taking college-level exams, and identifying the intended meaning of a word. In each case, language models perform poorly with very little dependence on model size up to a threshold at which point their performance suddenly begins to excel.
 |
| The ability to perform multi-step arithmetic (left), succeed on college-level exams (middle), and identify the intended meaning of a word in context (right) all emerge only for models of sufficiently large scale. The models shown include LaMDA, GPT-3, Gopher, Chinchilla, and PaLM. |
Performance on these tasks only becomes non-random for models of sufficient scale — for instance, above 1022 training FLOPs for the arithmetic and multi-task NLU tasks, and above 1024 training FLOPs for the word in context tasks. Note that although the scale at which emergence occurs can be different for different tasks and models, no model showed smooth improvement in behavior on any of these tasks. Dozens of other emergent prompted tasks are listed in our paper.
Emergent Prompting Strategies
The second class of emergent abilities encompasses prompting strategies that augment the capabilities of language models. Prompting strategies are broad paradigms for prompting that can be applied to a range of different tasks. They are considered emergent when they fail for small models and can only be used by a sufficiently-large model.
One example of an emergent prompting strategy is called “chain-of-thought prompting”, for which the model is prompted to generate a series of intermediate steps before giving the final answer. Chain-of-thought prompting enables language models to perform tasks requiring complex reasoning, such as a multi-step math word problem. Notably, models acquire the ability to do chain-of-thought reasoning without being explicitly trained to do so. An example of chain-of-thought prompting is shown in the figure below.
 |
| Chain of thought prompting enables sufficiently large models to solve multi-step reasoning problems. |
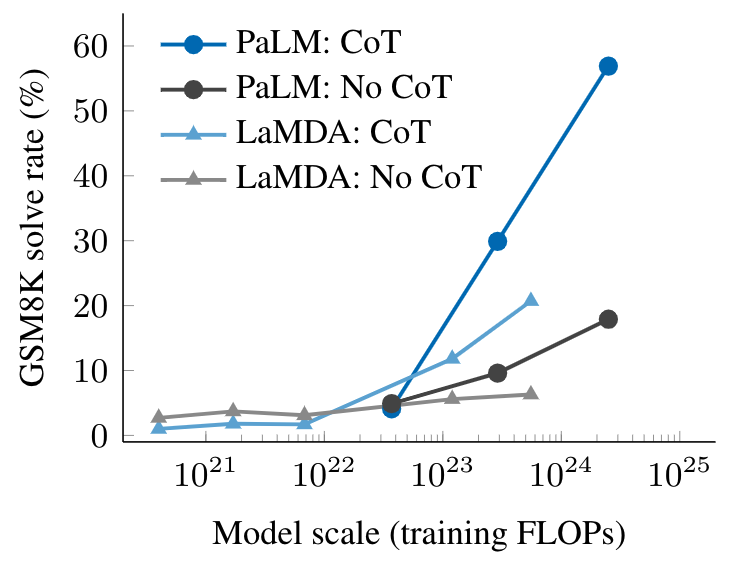
The empirical results of chain-of-thought prompting are shown below. For smaller models, applying chain-of-thought prompting does not outperform standard prompting, for example, when applied to GSM8K, a challenging benchmark of math word problems. However, for large models (1024 FLOPs), chain-of-thought prompting substantially improves performance in our tests, reaching a 57% solve rate on GSM8K.
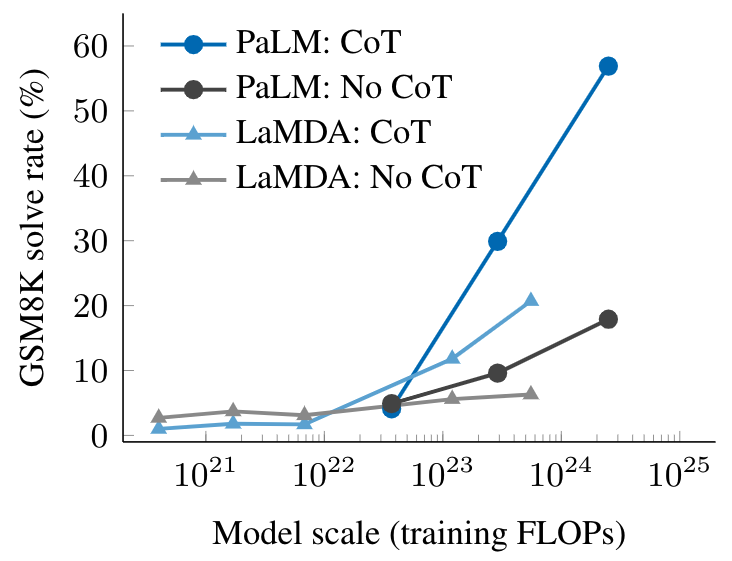 |
| Chain-of-thought prompting is an emergent ability — it fails to improve performance for small language models, but substantially improves performance for large models. Here we illustrate the difference between standard and chain-of-thought prompting at different scales for two language models, LaMDA and PaLM. |
Implications of Emergent Abilities
The existence of emergent abilities has a range of implications. For example, because emergent few-shot prompted abilities and strategies are not explicitly encoded in pre-training, researchers may not know the full scope of few-shot prompted abilities of current language models. Moreover, the emergence of new abilities as a function of model scale raises the question of whether further scaling will potentially endow even larger models with new emergent abilities.
Identifying emergent abilities in large language models is a first step in understanding such phenomena and their potential impact on future model capabilities. Why does scaling unlock emergent abilities? Because computational resources are expensive, can emergent abilities be unlocked via other methods without increased scaling (e.g., better model architectures or training techniques)? Will new real-world applications of language models become unlocked when certain abilities emerge? Analyzing and understanding the behaviors of language models, including emergent behaviors that arise from scaling, is an important research question as the field of NLP continues to grow.
Acknowledgements
It was an honor and privilege to work with Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus.
-
Labels:
- Conferences & Events
Quick links
Other posts of interest
-

December 12, 2025
Spotlight on innovation: Google-sponsored Data Science for Health Ideathon across Africa- Conferences & Events ·
- Generative AI ·
- Global ·
- Health & Bioscience
-

May 30, 2024
CodecLM: Aligning language models with tailored synthetic data- Conferences & Events ·
- Machine Intelligence ·
- Natural Language Processing
-
May 24, 2024
Google Research at Google I/O 2024- Conferences & Events ·
- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence ·
- Product ·
- Quantum ·
- Responsible AI