Building a deeper understanding of images
September 5, 2014
Posted by Christian Szegedy, Software Engineer
Quick links
The ImageNet large-scale visual recognition challenge (ILSVRC) is the largest academic challenge in computer vision, held annually to test state-of-the-art technology in image understanding, both in the sense of recognizing objects in images and locating where they are. Participants in the competition include leading academic institutions and industry labs. In 2012 it was won by DNNResearch using the convolutional neural network approach described in the now-seminal paper by Krizhevsky et al.[4]
In this year’s challenge, team GoogLeNet (named in homage to LeNet, Yann LeCun's influential convolutional network) placed first in the classification and detection (with extra training data) tasks, doubling the quality on both tasks over last year's results. The team participated with an open submission, meaning that the exact details of its approach are shared with the wider computer vision community to foster collaboration and accelerate progress in the field.
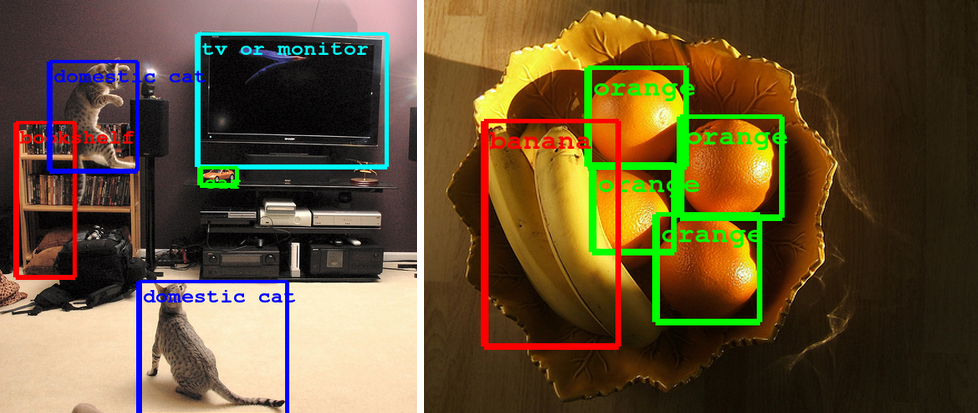
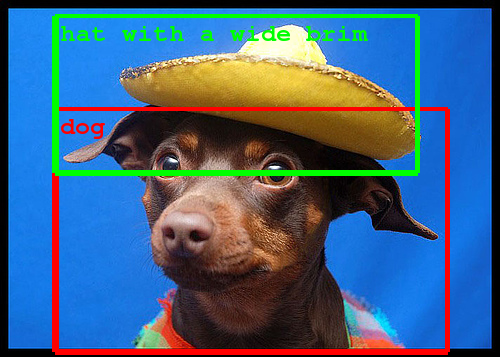
This effort was accomplished by using the DistBelief infrastructure, which makes it possible to train neural networks in a distributed manner and rapidly iterate. At the core of the approach is a radically redesigned convolutional network architecture. Its seemingly complex structure (typical incarnations of which consist of over 100 layers with a maximum depth of over 20 parameter layers), is based on two insights: the Hebbian principle and scale invariance. As the consequence of a careful balancing act, the depth and width of the network are both increased significantly at the cost of a modest growth in evaluation time. The resultant architecture leads to over 10x reduction in the number of parameters compared to most state of the art vision networks. This reduces overfitting during training and allows our system to perform inference with low memory footprint.

These technological advances will enable even better image understanding on our side and the progress is directly transferable to Google products such as photo search, image search, YouTube, self-driving cars, and any place where it is useful to understand what is in an image as well as where things are.
References:
[1] Erhan D., Szegedy C., Toshev, A., and Anguelov, D., "Scalable Object Detection using Deep Neural Networks", The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 2147-2154.
[2] Girshick, R., Donahue, J., Darrell, T., & Malik, J., "Rich feature hierarchies for accurate object detection and semantic segmentation", arXiv preprint arXiv:1311.2524, 2013.
[3] Howard, A. G., "Some Improvements on Deep Convolutional Neural Network Based Image Classification", arXiv preprint arXiv:1312.5402, 2013.
[4] Krizhevsky, A., Sutskever I., and Hinton, G., "Imagenet classification with deep convolutional neural networks", Advances in neural information processing systems, 2012.
Quick links
Other posts of interest
-

February 17, 2026
Teaching AI to read a map- Machine Perception ·
- Open Source Models & Datasets
-

February 10, 2026
Beyond one-on-one: Authoring, simulating, and testing dynamic human-AI group conversations- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

February 5, 2026
How AI tools can redefine universal design to increase accessibility- Education Innovation ·
- Machine Intelligence ·
- Natural Language Processing ·
- Responsible AI
×
❮
❯