AudioLM: a Language Modeling Approach to Audio Generation
October 6, 2022
Posted by Zalán Borsos, Research Software Engineer, and Neil Zeghidour, Research Scientist, Google Research
Quick links
Generating realistic audio requires modeling information represented at different scales. For example, just as music builds complex musical phrases from individual notes, speech combines temporally local structures, such as phonemes or syllables, into words and sentences. Creating well-structured and coherent audio sequences at all these scales is a challenge that has been addressed by coupling audio with transcriptions that can guide the generative process, be it text transcripts for speech synthesis or MIDI representations for piano. However, this approach breaks when trying to model untranscribed aspects of audio, such as speaker characteristics necessary to help people with speech impairments recover their voice, or stylistic components of a piano performance.
In “AudioLM: a Language Modeling Approach to Audio Generation”, we propose a new framework for audio generation that learns to generate realistic speech and piano music by listening to audio only. Audio generated by AudioLM demonstrates long-term consistency (e.g., syntax in speech, melody in music) and high fidelity, outperforming previous systems and pushing the frontiers of audio generation with applications in speech synthesis or computer-assisted music. Following our AI Principles, we've also developed a model to identify synthetic audio generated by AudioLM.
From Text to Audio Language Models
In recent years, language models trained on very large text corpora have demonstrated their exceptional generative abilities, from open-ended dialogue to machine translation or even common-sense reasoning. They have further shown their capacity to model other signals than texts, such as natural images. The key intuition behind AudioLM is to leverage such advances in language modeling to generate audio without being trained on annotated data.
However, some challenges need to be addressed when moving from text language models to audio language models. First, one must cope with the fact that the data rate for audio is significantly higher, thus leading to much longer sequences — while a written sentence can be represented by a few dozen characters, its audio waveform typically contains hundreds of thousands of values. Second, there is a one-to-many relationship between text and audio. This means that the same sentence can be rendered by different speakers with different speaking styles, emotional content and recording conditions.
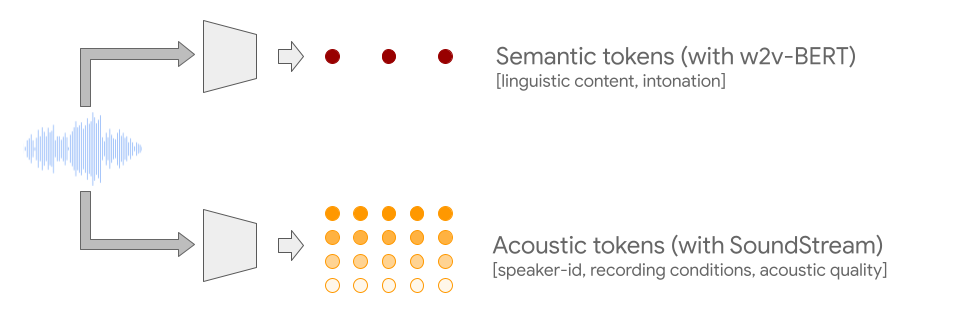
To overcome both challenges, AudioLM leverages two kinds of audio tokens. First, semantic tokens are extracted from w2v-BERT, a self-supervised audio model. These tokens capture both local dependencies (e.g., phonetics in speech, local melody in piano music) and global long-term structure (e.g., language syntax and semantic content in speech, harmony and rhythm in piano music), while heavily downsampling the audio signal to allow for modeling long sequences.
However, audio reconstructed from these tokens demonstrates poor fidelity. To overcome this limitation, in addition to semantic tokens, we rely on acoustic tokens produced by a SoundStream neural codec, which capture the details of the audio waveform (such as speaker characteristics or recording conditions) and allow for high-quality synthesis. Training a system to generate both semantic and acoustic tokens leads simultaneously to high audio quality and long-term consistency.

Training an Audio-Only Language Model
AudioLM is a pure audio model that is trained without any text or symbolic representation of music. AudioLM models an audio sequence hierarchically, from semantic tokens up to fine acoustic tokens, by chaining several Transformer models, one for each stage. Each stage is trained for the next token prediction based on past tokens, as one would train a text language model. The first stage performs this task on semantic tokens to model the high-level structure of the audio sequence.

In the second stage, we concatenate the entire semantic token sequence, along with the past coarse acoustic tokens, and feed both as conditioning to the coarse acoustic model, which then predicts the future tokens. This step models acoustic properties such as speaker characteristics in speech or timbre in music.

In the third stage, we process the coarse acoustic tokens with the fine acoustic model, which adds even more detail to the final audio. Finally, we feed acoustic tokens to the SoundStream decoder to reconstruct a waveform.

After training, one can condition AudioLM on a few seconds of audio, which enables it to generate consistent continuation. In order to showcase the general applicability of the AudioLM framework, we consider two tasks from different audio domains:
- Speech continuation, where the model is expected to retain the speaker characteristics, prosody and recording conditions of the prompt while producing new content that is syntactically correct and semantically consistent.
- Piano continuation, where the model is expected to generate piano music that is coherent with the prompt in terms of melody, harmony and rhythm.
In the video below, you can listen to examples where the model is asked to continue either speech or music and generate new content that was not seen during training. As you listen, note that everything you hear after the gray vertical line was generated by AudioLM and that the model has never seen any text or musical transcription, but rather just learned from raw audio. We release more samples on this webpage.
To validate our results, we asked human raters to listen to short audio clips and decide whether it is an original recording of human speech or a synthetic continuation generated by AudioLM. Based on the ratings collected, we observed a 51.2% success rate, which is not statistically significantly different from the 50% success rate achieved when assigning labels at random. This means that speech generated by AudioLM is hard to distinguish from real speech for the average listener.
Our work on AudioLM is for research purposes and we have no plans to release it more broadly at this time. In alignment with our AI Principles, we sought to understand and mitigate the possibility that people could misinterpret the short speech samples synthesized by AudioLM as real speech. For this purpose, we trained a classifier that can detect synthetic speech generated by AudioLM with very high accuracy (98.6%). This shows that despite being (almost) indistinguishable to some listeners, continuations generated by AudioLM are very easy to detect with a simple audio classifier. This is a crucial first step to help protect against the potential misuse of AudioLM, with future efforts potentially exploring technologies such as audio “watermarking”.
Conclusion
We introduce AudioLM, a language modeling approach to audio generation that provides both long-term coherence and high audio quality. Experiments on speech generation show not only that AudioLM can generate syntactically and semantically coherent speech without any text, but also that continuations produced by the model are almost indistinguishable from real speech by humans. Moreover, AudioLM goes well beyond speech and can model arbitrary audio signals such as piano music. This encourages the future extensions to other types of audio (e.g., multilingual speech, polyphonic music, and audio events) as well as integrating AudioLM into an encoder-decoder framework for conditioned tasks such as text-to-speech or speech-to-speech translation.
Acknowledgments
The work described here was authored by Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi and Neil Zeghidour. We are grateful for all discussions and feedback on this work that we received from our colleagues at Google.
Quick links
Other posts of interest
-

July 10, 2025
Graph foundation models for relational data- Algorithms & Theory ·
- Machine Intelligence
-

July 9, 2025
MedGemma: Our most capable open models for health AI development- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

July 2, 2025
Making group conversations more accessible with sound localization- Human-Computer Interaction and Visualization ·
- Sound & Accoustics ·
- Speech Processing