
AI in software engineering at Google: Progress and the path ahead
June 6, 2024
Satish Chandra, Principal Engineer, and Maxim Tabachnyk, Senior Staff Software Engineer, Core Systems and Experiences
Quick links
In 2019, a software engineer — at Google or indeed anywhere else — would have heard of advances in machine learning, and how deep learning has become remarkably effective in fields such as computer vision or language translation. However, most of them would not have imagined, let alone experienced, the ways in which machine learning might benefit what they do.
Just five years later, in 2024, there is widespread enthusiasm among software engineers about how AI is helping write code. And a significant number of those have used ML-based autocomplete, whether it is using company internal tools at large companies, e.g., Google’s internal code completion, or via commercially available products.
In this blog, we present our newest AI-powered improvements within the context of the continuing transformation of Google’s internal software development tools, and discuss further changes that we expect to see in the coming 5 years. We also present our methodology on how to build AI products that deliver value for professional software development. Our team is responsible for the software development environments where Google engineers spend the majority of their time, including inner loop (e.g., IDE, code review, code search), as well as outer loop surfaces (e.g., bug management, planning). We illustrate that improvements to these surfaces can directly impact developer productivity and satisfaction, both metrics that we monitor carefully.
The challenge
An ongoing challenge in this domain is that AI technology is evolving quickly and it is hard to predict which ideas to explore first. There is often a significant gap between technically feasible demos and successful productization. We approach deployment of ideas to products with three guidelines:
- Prioritize by technical feasibility and impact: Work on ideas wherein both technical feasibility has already been established and high (measureable) impact on engineers’ workflows is expected.
- Learn quickly, to improve UX and model quality: Focus on iterating quickly and extracting lessons learned, while safeguarding developer productivity and happiness. User experience is just as important as model quality.
- Measure effectiveness: As our goal is to increase productivity and satisfaction metrics, we need to extensively monitor these metrics.
Applying LLMs to software development
With the advent of transformer architectures, we started exploring how to apply LLMs to software development. LLM-based inline code completion is the most popular application of AI applied to software development: it is a natural application of LLM technology to use the code itself as training data. The UX feels natural to developers since word-level autocomplete has been a core feature of IDEs for many years. Also, it’s possible to use a rough measure of impact, e.g., the percentage of new characters written by AI. For these reasons and more, it made sense for this application of LLMs to be the first to deploy.
Our earlier blog describes the ways in which we improve user experience with code completion and how we measure impact. Since then, we have seen continued fast growth similar to other enterprise contexts, with an acceptance rate by software engineers of 37%
Key improvements came from both the models — larger models with improved coding capabilities, heuristics for constructing the context provided to the model, as well as tuning models on usage logs containing acceptances, rejections and corrections — and the UX. This cycle is essential for learning from practical behavior, rather than synthetic formulations.
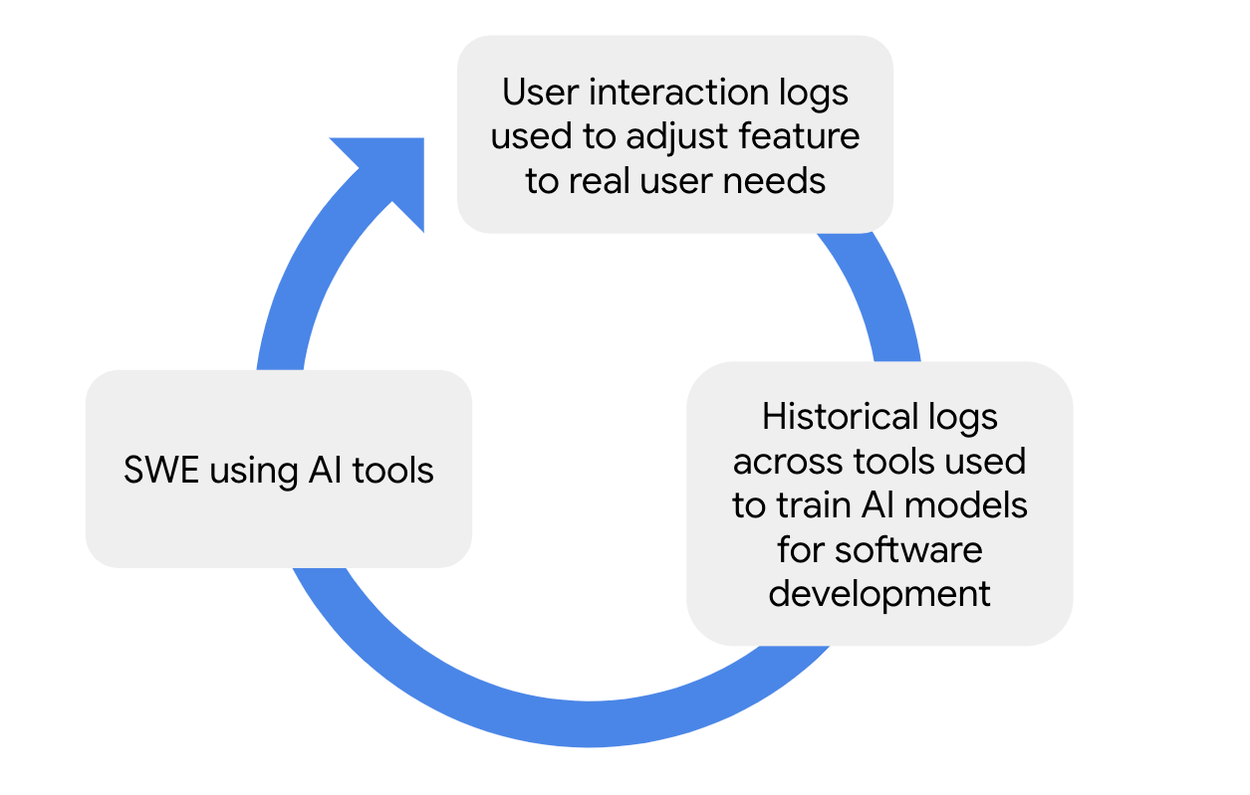
Improving AI-based features in coding tools (e.g., in the IDE) with historical high quality data across tools and with usage data capturing user preferences and needs.
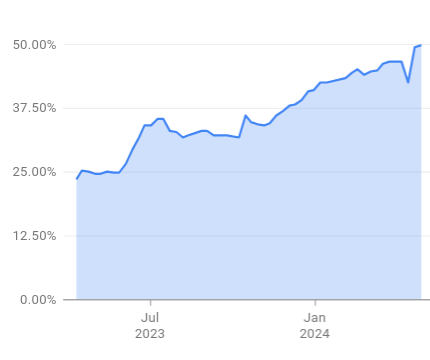
Continued increase of the fraction of code created with AI assistance via code completion, defined as the number of accepted characters from AI-based suggestions divided by the sum of manually typed characters and accepted characters from AI-based suggestions. Notably, characters from copy-pastes are not included in the denominator.
We use our extensive and high quality logs of internal software engineering activities across multiple tools, which we have curated over many years. This data, for example, enables us to represent fine-grained code edits, build outcomes, edits to resolve build issues, code copy-paste actions, fixes of pasted code, code reviews, edits to fix reviewer issues, and change submissions to a repository. The training data is an aligned corpus of code with task-specific annotations in input as well as in output. The design of the data collection process, the shape of the training data, and the model that is trained on this data was described in our DIDACT blog. We continue to explore these powerful datasets with newer generations of foundation models available to us (discussed more below).
Our next significant deployments were resolving code review comments (>8% of which are now addressed with AI-based assistance) and automatically adapting pasted code to the surrounding context (now responsible for ~2% of code in the IDE2). Further deployments include instructing the IDE to perform code edits with natural language and predicting fixes to build failures. Other applications, e.g., predicting tips for code readability following a similar pattern are also possible.
Together, these deployed applications have been successful, highly-used applications at Google, with measurable impact on productivity in a real, industrial context.
A demonstration of how a variety of AI-based features can work together to assist with coding in the IDE.
What we’ve learned
Our work so far has taught us several things:
- We achieved the highest impact with UX that naturally blends into users’ workflows. In all the above examples, a suggestion is presented to the user, taking them to the next step in their workflow with one tab or click. Experiments requiring the user to remember to trigger the feature have failed to scale.
- We observe that with AI-based suggestions, the code author increasingly becomes a reviewer, and it is important to find a balance between the cost of review and added value. We typically address the tradeoff with acceptance rate targets.
- Quick iterations with online A/B experiments are key, as offline metrics are often only rough proxies of user value. By surfacing our AI-based features on internal tooling, we benefit greatly from being able to easily launch and iterate, measure usage data, and ask users directly about their experience through UX research.
- High quality data from activities of Google engineers across software tools, including interactions with our features, is essential for our model quality.
We observe across features that it’s important to optimize for conversion from the opportunity (mostly a user activity, shown at the top of the funnel below) to impact (applied AI assistance, at the bottom of the funnel), while removing bottlenecks from intermediate steps of the funnel by leveraging UX and model improvements.
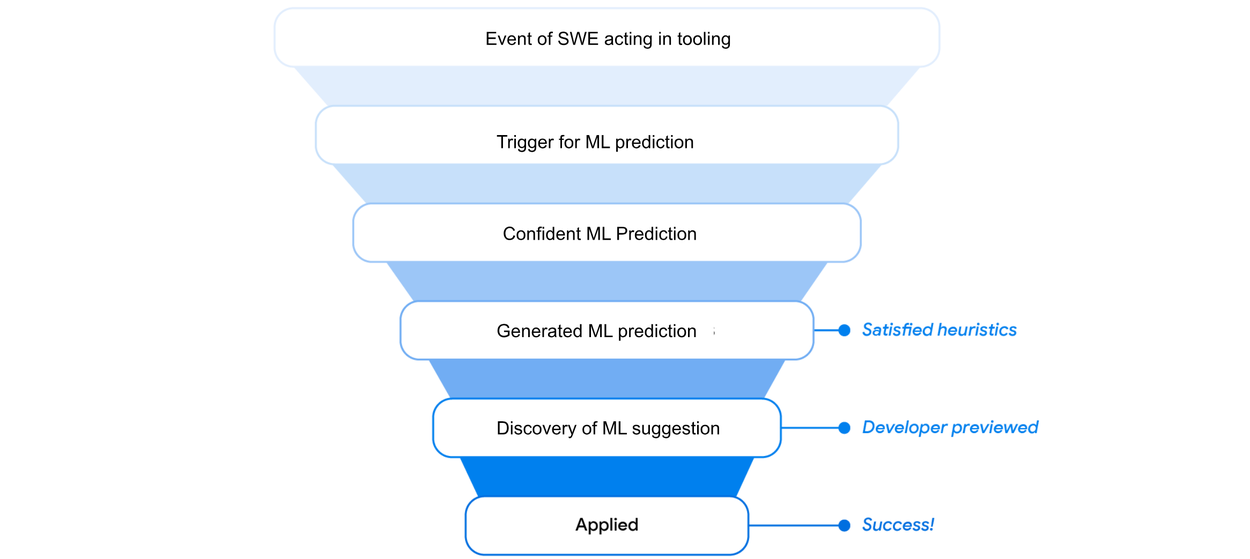
An opportunity funnel starting from SWE actions down to actual application of ML-based suggestions. Opportunities are lost if the model prediction is not confident enough, the model doesn’t respond or responds too late, the prediction is subpar, the user doesn’t notice the prediction, and so on. We use UX and model improvements to harvest as many opportunities as we can.
What’s next
Encouraged by our successes so far, we are doubling down on bringing the latest foundation models (Gemini series) infused with the developer data (as part of DIDACT, mentioned above) to power existing and new applications of ML to software engineering in Google.
Across the industry, ML-based code completion has provided a major boost for software developers. While there are still opportunities to improve code generation, we expect the next wave of benefits to come from ML assistance in a broader range of software engineering activities, such as testing, code understanding and code maintenance; the latter being of particular interest in enterprise settings. These opportunities inform our own ongoing work. We also highlight two trends that we see in the industry:
- Human-computer interaction has moved towards natural language as a common modality, and we are seeing a shift towards using language as the interface to software engineering tasks as well as the gateway to informational needs for software developers, all integrated in IDEs.
- ML-based automation of larger-scale tasks — from diagnosis of an issue to landing a fix — has begun to show initial evidence of feasibility. These possibilities are driven by innovations in agents and tool use, which permit the building of systems that use one or more LLMs as a component to accomplish a larger task.
To expand on the above successes toward these next generation capabilities, the community of practitioners and researchers working in this topic would benefit from common benchmarks to help move the field towards practical engineering tasks. So far, benchmarks have been focused mostly around code generation (e.g., HumanEval). In an enterprise setting, however, benchmarks for a wider range of tasks could be particularly valuable, e.g., code migrations and production debugging. Some benchmarks, such as one for bug resolution (e.g., SWEBench), and prototypes targeting those benchmarks (e.g., from Cognition AI) have been published. We encourage the community to come together to suggest more benchmarks to span a wider range of software engineering tasks.
Acknowledgements
This project is the result of work of many people from the Google Core Systems & Experiences team and Google Deepmind. This article was co-authored with Boris Bokowski (Google Coding Tools Director), Petros Maniatis (research), Ambar Murillo (UXR), and Alberto Elizondo (UXD). Deep gratitude goes to contributors to the various features: Adam Husting, Ahmed Omran, Alexander Frömmgen, Ambar Murillo, Ayoub Kachkach, Brett Durrett, Chris Gorgolewski, Charles Sutton, Christian Schneider, Danny Tarlow, Damien Martin-Guillerez, David Tattersall, Elena Khrapko, Evgeny Gryaznov, Franjo Ivancic, Fredde Ribeiro, Gabriela Surita, Guilherme Herzog, Henrik Muehe, Ilia Krets, Iris Chu, Juanjo Carin, Katja Grünwedel, Kevin Villela, Kristóf Molnár, Lera Kharatyan, Madhura Dudhgaonkar, Marcus Revaj, Nimesh Ghelani, Niranjan Tulpule, Pavel Sychev, Siddhant Sanyam, Stanislav Pyatykh, Stoyan Nikolov, Ugam Kumar, Tobias Welp, Vahid Meimand, Vincent Nguyen, Yurun Shen, and Zoubin Ghahramani. Thanks to Tom Small for creating graphics for this post. Thanks also to contributors DIDACT, build fixing, readability fixes and resolving code review comments.
-
Defined as the number of AI-generated suggestions that are accepted divided by the number shown for greater than 750 milliseconds while the user is not typing.
-
Defined as the number of accepted characters from AI-generated suggestions divided by the sum of manually typed characters and accepted characters from AI-generated suggestions. Notably, characters from copy-pastes are not included in the denominator.
Quick links
Other posts of interest
-

April 8, 2026
Improving the academic workflow: Introducing two AI agents for better figures and peer review- Generative AI ·
- Natural Language Processing
-

April 3, 2026
Evaluating alignment of behavioral dispositions in LLMs- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Machine Intelligence
-

March 25, 2026
Vibe Coding XR: Accelerating AI + XR prototyping with XR Blocks and Gemini- Human-Computer Interaction and Visualization ·
- Machine Intelligence

Continued increase of the fraction of code created with AI assistance via code completion, defined as the number of accepted characters from AI-based suggestions divided by the sum of manually typed characters and accepted characters from AI-based suggestions. Notably, characters from copy-pastes are not included in the denominator.
Improving AI-based features in coding tools (e.g., in the IDE) with historical high quality data across tools and with usage data capturing user preferences and needs.

An opportunity funnel starting from SWE actions down to actual application of ML-based suggestions. Opportunities are lost if the model prediction is not confident enough, the model doesn’t respond or responds too late, the prediction is subpar, the user doesn’t notice the prediction, and so on. We use UX and model improvements to harvest as many opportunities as we can.