
Safely repairing broken builds with ML
April 23, 2024
Emily Johnston and Stephanie Tang, Software Engineers, Core Systems & Experiences
Quick links
Software development is a cyclical process of designing, writing, building, testing, deploying, and debugging. If you’ve ever resolved a build error only to introduce 20 more, you’re familiar with the frustration of hunting down a type mismatch in unfamiliar code, or diagnosing where you went wrong using some new API.
At Google, every time a source code file is saved, a snapshot of the code is saved to version control. Every time a build runs, build logs are saved. This is a data treasure trove! We can determine when a build broke, what error messages were present, when the build succeeded, and what code changed — essentially, exactly how the developer fixed the build.
Today we describe how we trained a DIDACT ML model to predict build fixes. DIDACT, as we previously discussed, is a methodology that uses the software development process as a whole as training data. Using this dedicated build fix ML model, we then surfaced fixes in an IDE and ran a controlled experiment on this feature. This experiment showed statistically-significant gains across several measures of productivity, including a 2% increase in the number of code changes. These gains are not only good for their own sake, but they also remove developer toil through automation, allowing developers more time for creative problem solving. This promotes focus by removing obstacles, thus keeping developers in their flow state longer. Indeed, we now observe that about 34% of users experiencing a build breakage in a given month end up applying such ML-suggested fixes. We also detect no observable increase in safety risks or bugs when ML-generated fixes are applied. ML-powered build repair is now enabled for all Google developers and was recently featured at Google Cloud Next.
An overview of our build repair model being trained and suggesting fixes to code. A pre-trained DIDACT model is fine-tuned on records of developers’ build errors and their fixes. This model is then used to suggest repairs to developers’ builds in real time in the IDE.
Problem and motivation
Our ambition originated with the desire to improve developers’ experience fixing Java build errors. Could we make error messages more actionable, or even fix the errors automatically? We harnessed Google’s comprehensive record of its developers’ code and Google’s research expertise to repair broken builds with ML.
Build errors are not all simple missing parentheses, typos, or oops-I-forgot-my-dependency-agains. Errors from generics or templates can be convoluted, and error messages can be cryptic. At Google, a build is also more than just compilation. Over the years, there have been many efforts to “shift left” several types of errors that may occur in the course of the development lifecycle, detecting them as early as possible, frequently at build time (i.e., while the code is in the early stages of being written). For example, a curated set of Error Prone static analysis checkers are run on every build. Build errors and some static-analysis checks block submission of code changes. We saw potential in our approach for these more complex issues, so we expanded the scope of our repairs to other kinds of errors, then to other languages including C++, and to more environments.
Training and input data
To generate training data from Google’s development history, we assembled “resolution sessions”. These are chronological sequences of code snapshots and build logs occurring in the same workspace, capturing the change in code from the moment a breakage first occurred to the moment it was resolved.
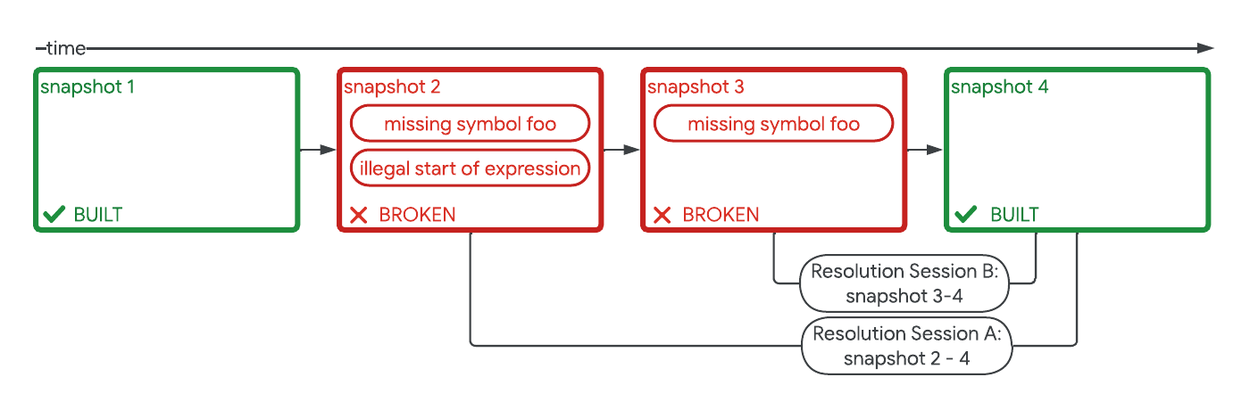
A breakdown of two resolution sessions in a series of four builds occurring over time in the same workspace.
DIDACT is trained on the build errors in our internal codebases that appear at the first snapshot of the resolution session, the state of the code (i.e., the file contents) at that same broken snapshot, and the code diff between the broken and the fixed snapshot.
At serving time, the DIDACT input is the current code state and the build errors found at that state. DIDACT then predicts a patch to be applied to the code (with a confidence score) as a suggested fix.
Filtering suggested fixes for quality and safety
The industry has seen that code-generation ML models may introduce bugs that can slip past developers, so there is a real risk of making code worse with ML-generated repairs. In order to maintain the quality and safety of Google’s codebase (and credibility with our developers), we apply post-processing to the ML-generated fixes: auto-formatting, then heuristic filters we devised using a combination of expert knowledge and user feedback to avoid common quality and safety pitfalls, such as code vulnerabilities.
What it looks like
A developer sees a fix inline as soon as it is available, previews it, and can choose to accept or reject it.
A recording of a build repair being applied in an IDE. When the developer encounters a build error while coding, they are presented with a “Review ML-suggested fix” button. Upon clicking the button, they are shown a preview of the suggested fix, which they can then apply or discard. In this case, the developer applied the fix, and the new code built successfully.
Fixes that pass quality and safety filtering are surfaced to the user in the IDE, and if they are accepted, development continues as normal — the standard process of building, testing, static and dynamic analysis, and code review continues.
The experiment
We randomly assigned 50% of all Google developers to the treatment group: they received access to ML build fixes in the IDE. The other 50% were assigned to control. We monitored the two groups for 11 weeks, then compared outcomes.
Productivity improvements
We investigated speed- and efficiency-related metrics when evaluating productivity impact. Our results show statistically significant results:
- ~2% reduction in active coding time per changelist (CL): Average time spent “fingers on keyboard” working on a CL, including coding and closely related activities, before sending for review.
- ~2% reduction in shepherding time per CL: Average time spent in the development of a CL after sending for review, including addressing code-review feedback.
- ~2% increase in CL throughput: Average number of CLs submitted per week.
These findings suggest that ML build fixes help developers more quickly address development obstacles like build failures, so they can focus on the holistic goal of each CL. In other words, ML build fixes can help developers stay in the flow. Furthermore, the 2% increase in CL throughput shows that developers don’t just type more code; in fact, they now complete more submitted, tested units of work.
We suspect that developers realize increased productivity from more than just trivial build fixes like missing semicolons, or else they wouldn't invest the extra time needed to review a suggestion. Instead, developers are likely solving more complex build failures or static analysis failures more efficiently. Examples include complex C++ template issues and lambdas, or complex concurrency Java APIs. We hypothesize that developers end up reviewing and perhaps modifying the ML suggestions for such failures, rather than having to leave the IDE to search for possible answers, thus interrupting their coding flow.
Maintaining safety
Increasing development velocity alone isn’t necessarily better. We must also ensure that ML-generated code is high-quality and safe.
To evaluate the risk of introducing incorrect or even dangerous code via our fixes, we examined retrospective safety- and reliability-related metrics, including:
- Rate of CL rollbacks: Issues in production are typically resolved by rolling back the culprit CL that introduced the bug.
- Rate of new sanitizer failures: Google runs sanitizers that can detect and flag issues like memory corruption or leaks on unit tests and fuzz targets; examples are AddressSanitizer, MemorySanitizer, and GWP-Asan.
We monitored these metrics between CLs authored with the help of build repairs vs. without, and found no detectable difference.
Conclusions
Surfacing ML build fixes in the IDE, guarded by automated safety checks and human review, significantly improved developer productivity without negatively impacting code safety. This supports our intuition that leveraging ML during software development, even on well-understood problems, reduces toil and frees developers to solve higher-order problems more efficiently. Moreover, similar approaches may be effective in addressing other kinds of error and engineering tasks throughout the development cycle. These results demonstrate the potential of ML to improve developer productivity, focus, and code quality, both effectively and safely.
Acknowledgements
This work is the result of a multi-year collaboration between Google DeepMind and Google Core Systems & Experiences team. We would like to acknowledge our colleagues Matt Frazier, Franjo Ivančić, Jessica Ko, Markus Kusano, Pascal Lamblin, Pierre-Antoine Manzagol, Sara Qu, and Vaibhav Tulsyan. We would also like to thank our collaborators and leadership, including Hassan Abolhassani, Edward Aftandilian, Jacob Austin, Paige Bailey, Kevin Bierhoff, Boris Bokowski, Juanjo Carin, Satish Chandra, Zimin Chen, Iris Chu, Cristopher Claeys, Elvira Djuraeva, Madhura Dudhgaonkar, Alberto Elizondo, Zoubin Ghahramani, Eli Gild, Nick Glorioso, Chris Gorgolewski, Evgeny Gryaznov, Daniel Jasper, Manuel Klimek, Matthew F. Kulukundis, Hugo Larochelle, Darla Louis, Quinn Madison, Petros Maniatis, Vahid Meimand, Ali Mesbah, Subhodeep Moitra, Kristóf Molnár, Ambar Murillo, Stoyan Nikolov, Amit Patel, Jim Plotts, Andy Qin, Marcus Revaj, Andrew Rice, Ballie Sandhu, Sergei Shmulyian, Tom Small, Charles Sutton, Pavel Sychev, Maxim Tabachnyk, Danny Tarlow, David Tattersall, Niranjan Tulpule, Cornelius Weig, Donald Duo Zhao, and Daniel Zheng. Thank you!
Quick links
Other posts of interest
-

July 22, 2026
Towards a quantum computer that learns from its errors- Machine Intelligence ·
- Quantum
-

July 15, 2026
Towards demystifying the creativity of diffusion models- Algorithms & Theory ·
- Generative AI ·
- Machine Intelligence
-

July 9, 2026
SensorFM: Towards a general intelligence and interface for wearable health data- Generative AI ·
- Machine Intelligence
A breakdown of two resolution sessions in a series of four builds occurring over time in the same workspace.